 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeparable Mixture of Low-Rank Adaptation for Continual Visual Instruction Tuning
Nov 21, 2024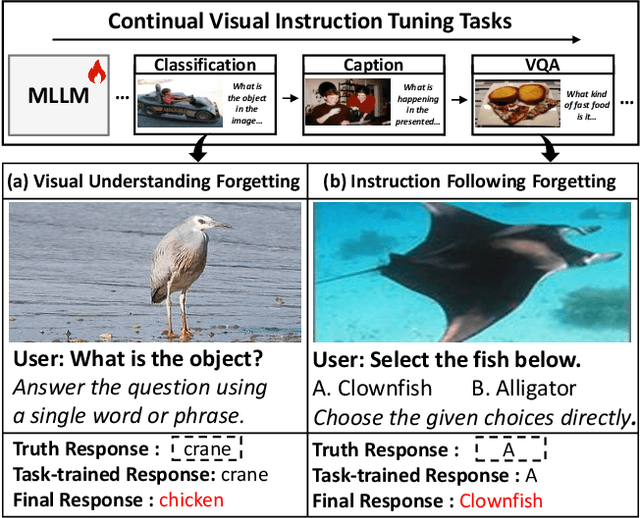
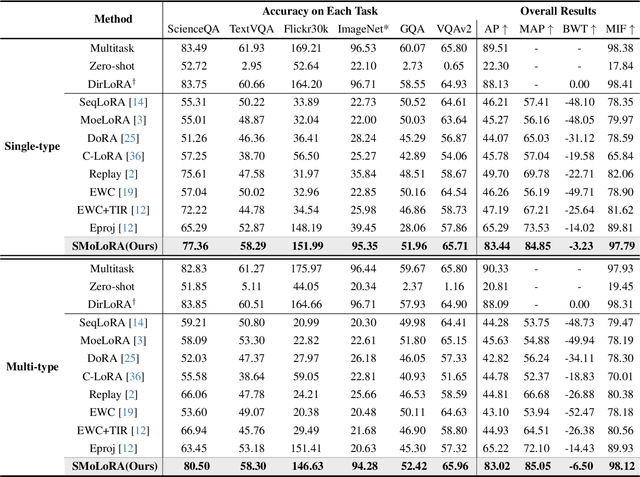
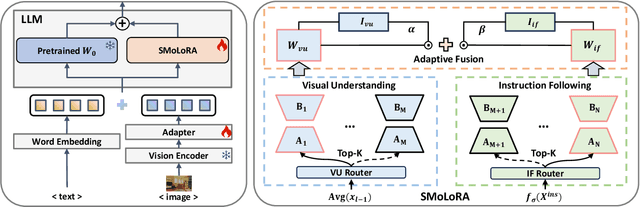
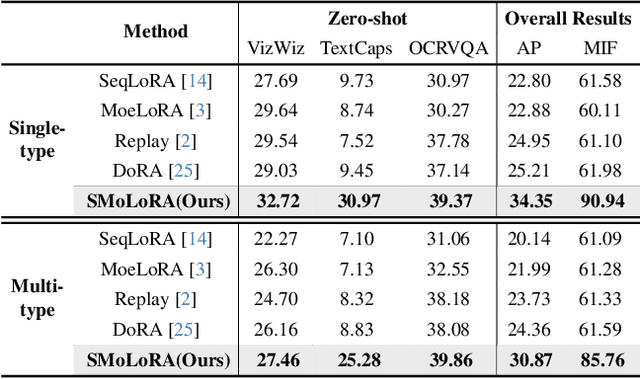
Visual instruction tuning (VIT) enables multimodal large language models (MLLMs) to effectively handle a wide range of vision tasks by framing them as language-based instructions. Building on this, continual visual instruction tuning (CVIT) extends the capability of MLLMs to incrementally learn new tasks, accommodating evolving functionalities. While prior work has advanced CVIT through the development of new benchmarks and approaches to mitigate catastrophic forgetting, these efforts largely follow traditional continual learning paradigms, neglecting the unique challenges specific to CVIT. We identify a dual form of catastrophic forgetting in CVIT, where MLLMs not only forget previously learned visual understanding but also experience a decline in instruction following abilities as they acquire new tasks. To address this, we introduce the Separable Mixture of Low-Rank Adaptation (SMoLoRA) framework, which employs separable routing through two distinct modules - one for visual understanding and another for instruction following. This dual-routing design enables specialized adaptation in both domains, preventing forgetting while improving performance. Furthermore, we propose a novel CVIT benchmark that goes beyond existing benchmarks by additionally evaluating a model's ability to generalize to unseen tasks and handle diverse instructions across various tasks. Extensive experiments demonstrate that SMoLoRA outperforms existing methods in mitigating dual forgetting, improving generalization to unseen tasks, and ensuring robustness in following diverse instructions.
Visual-Oriented Fine-Grained Knowledge Editing for MultiModal Large Language Models
Nov 19, 2024



Knowledge editing aims to efficiently and cost-effectively correct inaccuracies and update outdated information. Recently, there has been growing interest in extending knowledge editing from Large Language Models (LLMs) to Multimodal Large Language Models (MLLMs), which integrate both textual and visual information, introducing additional editing complexities. Existing multimodal knowledge editing works primarily focus on text-oriented, coarse-grained scenarios, failing to address the unique challenges posed by multimodal contexts. In this paper, we propose a visual-oriented, fine-grained multimodal knowledge editing task that targets precise editing in images with multiple interacting entities. We introduce the Fine-Grained Visual Knowledge Editing (FGVEdit) benchmark to evaluate this task. Moreover, we propose a Multimodal Scope Classifier-based Knowledge Editor (MSCKE) framework. MSCKE leverages a multimodal scope classifier that integrates both visual and textual information to accurately identify and update knowledge related to specific entities within images. This approach ensures precise editing while preserving irrelevant information, overcoming the limitations of traditional text-only editing methods. Extensive experiments on the FGVEdit benchmark demonstrate that MSCKE outperforms existing methods, showcasing its effectiveness in solving the complex challenges of multimodal knowledge editing.
Towards Open-Vocabulary Audio-Visual Event Localization
Nov 18, 2024The Audio-Visual Event Localization (AVEL) task aims to temporally locate and classify video events that are both audible and visible. Most research in this field assumes a closed-set setting, which restricts these models' ability to handle test data containing event categories absent (unseen) during training. Recently, a few studies have explored AVEL in an open-set setting, enabling the recognition of unseen events as ``unknown'', but without providing category-specific semantics. In this paper, we advance the field by introducing the Open-Vocabulary Audio-Visual Event Localization (OV-AVEL) problem, which requires localizing audio-visual events and predicting explicit categories for both seen and unseen data at inference. To address this new task, we propose the OV-AVEBench dataset, comprising 24,800 videos across 67 real-life audio-visual scenes (seen:unseen = 46:21), each with manual segment-level annotation. We also establish three evaluation metrics for this task. Moreover, we investigate two baseline approaches, one training-free and one using a further fine-tuning paradigm. Specifically, we utilize the unified multimodal space from the pretrained ImageBind model to extract audio, visual, and textual (event classes) features. The training-free baseline then determines predictions by comparing the consistency of audio-text and visual-text feature similarities. The fine-tuning baseline incorporates lightweight temporal layers to encode temporal relations within the audio and visual modalities, using OV-AVEBench training data for model fine-tuning. We evaluate these baselines on the proposed OV-AVEBench dataset and discuss potential directions for future work in this new field.
Dataset Distillers Are Good Label Denoisers In the Wild
Nov 18, 2024



Learning from noisy data has become essential for adapting deep learning models to real-world applications. Traditional methods often involve first evaluating the noise and then applying strategies such as discarding noisy samples, re-weighting, or re-labeling. However, these methods can fall into a vicious cycle when the initial noise evaluation is inaccurate, leading to suboptimal performance. To address this, we propose a novel approach that leverages dataset distillation for noise removal. This method avoids the feedback loop common in existing techniques and enhances training efficiency, while also providing strong privacy protection through offline processing. We rigorously evaluate three representative dataset distillation methods (DATM, DANCE, and RCIG) under various noise conditions, including symmetric noise, asymmetric noise, and real-world natural noise. Our empirical findings reveal that dataset distillation effectively serves as a denoising tool in random noise scenarios but may struggle with structured asymmetric noise patterns, which can be absorbed into the distilled samples. Additionally, clean but challenging samples, such as those from tail classes in imbalanced datasets, may undergo lossy compression during distillation. Despite these challenges, our results highlight that dataset distillation holds significant promise for robust model training, especially in high-privacy environments where noise is prevalent.
Try-On-Adapter: A Simple and Flexible Try-On Paradigm
Nov 15, 2024



Image-based virtual try-on, widely used in online shopping, aims to generate images of a naturally dressed person conditioned on certain garments, providing significant research and commercial potential. A key challenge of try-on is to generate realistic images of the model wearing the garments while preserving the details of the garments. Previous methods focus on masking certain parts of the original model's standing image, and then inpainting on masked areas to generate realistic images of the model wearing corresponding reference garments, which treat the try-on task as an inpainting task. However, such implements require the user to provide a complete, high-quality standing image, which is user-unfriendly in practical applications. In this paper, we propose Try-On-Adapter (TOA), an outpainting paradigm that differs from the existing inpainting paradigm. Our TOA can preserve the given face and garment, naturally imagine the rest parts of the image, and provide flexible control ability with various conditions, e.g., garment properties and human pose. In the experiments, TOA shows excellent performance on the virtual try-on task even given relatively low-quality face and garment images in qualitative comparisons. Additionally, TOA achieves the state-of-the-art performance of FID scores 5.56 and 7.23 for paired and unpaired on the VITON-HD dataset in quantitative comparisons.
Enhancing ID-based Recommendation with Large Language Models
Nov 04, 2024Large Language Models (LLMs) have recently garnered significant attention in various domains, including recommendation systems. Recent research leverages the capabilities of LLMs to improve the performance and user modeling aspects of recommender systems. These studies primarily focus on utilizing LLMs to interpret textual data in recommendation tasks. However, it's worth noting that in ID-based recommendations, textual data is absent, and only ID data is available. The untapped potential of LLMs for ID data within the ID-based recommendation paradigm remains relatively unexplored. To this end, we introduce a pioneering approach called "LLM for ID-based Recommendation" (LLM4IDRec). This innovative approach integrates the capabilities of LLMs while exclusively relying on ID data, thus diverging from the previous reliance on textual data. The basic idea of LLM4IDRec is that by employing LLM to augment ID data, if augmented ID data can improve recommendation performance, it demonstrates the ability of LLM to interpret ID data effectively, exploring an innovative way for the integration of LLM in ID-based recommendation. We evaluate the effectiveness of our LLM4IDRec approach using three widely-used datasets. Our results demonstrate a notable improvement in recommendation performance, with our approach consistently outperforming existing methods in ID-based recommendation by solely augmenting input data.
Unlocking Your Sales Insights: Advanced XGBoost Forecasting Models for Amazon Products
Nov 01, 2024

One of the important factors of profitability is the volume of transactions. An accurate prediction of the future transaction volume becomes a pivotal factor in shaping corporate operations and decision-making processes. E-commerce has presented manufacturers with convenient sales channels to, with which the sales can increase dramatically. In this study, we introduce a solution that leverages the XGBoost model to tackle the challenge of predict-ing sales for consumer electronics products on the Amazon platform. Initial-ly, our attempts to solely predict sales volume yielded unsatisfactory results. However, by replacing the sales volume data with sales range values, we achieved satisfactory accuracy with our model. Furthermore, our results in-dicate that XGBoost exhibits superior predictive performance compared to traditional models.
EntityCLIP: Entity-Centric Image-Text Matching via Multimodal Attentive Contrastive Learning
Oct 23, 2024



Recent advancements in image-text matching have been notable, yet prevailing models predominantly cater to broad queries and struggle with accommodating fine-grained query intention. In this paper, we work towards the \textbf{E}ntity-centric \textbf{I}mage-\textbf{T}ext \textbf{M}atching (EITM), a task that the text and image involve specific entity-related information. The challenge of this task mainly lies in the larger semantic gap in entity association modeling, comparing with the general image-text matching problem.To narrow the huge semantic gap between the entity-centric text and the images, we take the fundamental CLIP as the backbone and devise a multimodal attentive contrastive learning framework to tam CLIP to adapt EITM problem, developing a model named EntityCLIP. The key of our multimodal attentive contrastive learning is to generate interpretive explanation text using Large Language Models (LLMs) as the bridge clues. In specific, we proceed by extracting explanatory text from off-the-shelf LLMs. This explanation text, coupled with the image and text, is then input into our specially crafted Multimodal Attentive Experts (MMAE) module, which effectively integrates explanation texts to narrow the gap of the entity-related text and image in a shared semantic space. Building on the enriched features derived from MMAE, we further design an effective Gated Integrative Image-text Matching (GI-ITM) strategy. The GI-ITM employs an adaptive gating mechanism to aggregate MMAE's features, subsequently applying image-text matching constraints to steer the alignment between the text and the image. Extensive experiments are conducted on three social media news benchmarks including N24News, VisualNews, and GoodNews, the results shows that our method surpasses the competition methods with a clear margin.
ArrivalNet: Predicting City-wide Bus/Tram Arrival Time with Two-dimensional Temporal Variation Modeling
Oct 17, 2024



Accurate arrival time prediction (ATP) of buses and trams plays a crucial role in public transport operations. Current methods focused on modeling one-dimensional temporal information but overlooked the latent periodic information within time series. Moreover, most studies developed algorithms for ATP based on a single or a few routes of public transport, which reduces the transferability of the prediction models and their applicability in public transport management systems. To this end, this paper proposes \textit{ArrivalNet}, a two-dimensional temporal variation-based multi-step ATP for buses and trams. It decomposes the one-dimensional temporal sequence into intra-periodic and inter-periodic variations, which can be recast into two-dimensional tensors (2D blocks). Each row of a tensor contains the time points within a period, and each column involves the time points at the same intra-periodic index across various periods. The transformed 2D blocks in different frequencies have an image-like feature representation that enables effective learning with computer vision backbones (e.g., convolutional neural network). Drawing on the concept of residual neural network, the 2D block module is designed as a basic module for flexible aggregation. Meanwhile, contextual factors like workdays, peak hours, and intersections, are also utilized in the augmented feature representation to improve the performance of prediction. 125 days of public transport data from Dresden were collected for model training and validation. Experimental results show that the root mean square error, mean absolute error, and mean absolute percentage error of the proposed predictor decrease by at least 6.1\%, 14.7\%, and 34.2\% compared with state-of-the-art baseline methods.
PSVMA+: Exploring Multi-granularity Semantic-visual Adaption for Generalized Zero-shot Learning
Oct 15, 2024



Generalized zero-shot learning (GZSL) endeavors to identify the unseen categories using knowledge from the seen domain, necessitating the intrinsic interactions between the visual features and attribute semantic features. However, GZSL suffers from insufficient visual-semantic correspondences due to the attribute diversity and instance diversity. Attribute diversity refers to varying semantic granularity in attribute descriptions, ranging from low-level (specific, directly observable) to high-level (abstract, highly generic) characteristics. This diversity challenges the collection of adequate visual cues for attributes under a uni-granularity. Additionally, diverse visual instances corresponding to the same sharing attributes introduce semantic ambiguity, leading to vague visual patterns. To tackle these problems, we propose a multi-granularity progressive semantic-visual mutual adaption (PSVMA+) network, where sufficient visual elements across granularity levels can be gathered to remedy the granularity inconsistency. PSVMA+ explores semantic-visual interactions at different granularity levels, enabling awareness of multi-granularity in both visual and semantic elements. At each granularity level, the dual semantic-visual transformer module (DSVTM) recasts the sharing attributes into instance-centric attributes and aggregates the semantic-related visual regions, thereby learning unambiguous visual features to accommodate various instances. Given the diverse contributions of different granularities, PSVMA+ employs selective cross-granularity learning to leverage knowledge from reliable granularities and adaptively fuses multi-granularity features for comprehensive representations. Experimental results demonstrate that PSVMA+ consistently outperforms state-of-the-art methods.