 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigating and Alleviating Harm Amplification in LLM Interactions
Jun 01, 2026Large language models (LLMs) can serve as helpful assistants, yet they can equally function as harm amplifiers that enable malicious users to achieve harmful outcomes beyond their capabilities through extended interactions. This risk manifests along two axes, i.e., democratizing domain expertise that allows novices to produce specialized harmful content, and scaling harmful operations at volumes that manual effort cannot match. Existing works, however, often overlook how LLMs compound harm across multi-turn conversations. We introduce HarmAmp, a new benchmark for multi-turn harm amplification scenarios spanning twelve risk categories. Each scenario is grounded in real-world threats and satisfies rigorous criteria, i.e., substantive amplification, operational specificity, and multi-turn necessity. We further propose TrajSafe, a proactive monitor that anticipates harmful trajectories and intervenes through actions such as probing users' genuine intents and steering the models towards safer completion. Our extensive experiments demonstrate that TrajSafe significantly reduces the harmfulness incurred in multi-turn interactions while preserving a low over-refusal rate and the target model's general capabilities. Our work offers a promising paradigm to alleviate the nuanced safety risks in LLM interactions.
RT-Splatting: Joint Reflection-Transmission Modeling with Gaussian Splatting
May 18, 20263D Gaussian Splatting (3DGS) enables real-time novel view synthesis with high visual quality. However, existing methods struggle with semi-transparent specular surfaces that exhibit both complex reflections and clear transmission, often producing blurry reflections or overly occluded transmission. To address this, we present RT-Splatting, a framework that disentangles each Gaussian's geometric occupancy from its optical opacity. This factorization yields a unified surface-volume scene representation with a single set of Gaussian primitives. Our hybrid renderer interprets this representation both as a surface to capture high-frequency reflections and as a volume to preserve clear transmission. To mitigate the ambiguity in jointly optimizing reflection and transmission, we introduce Specular-Aware Gradient Gating, which suppresses misleading gradients from highly specular regions into the transmission branch, effectively reducing distracting floaters. Experiments on challenging semi-transparent scenes show that RT-Splatting achieves state-of-the-art performance, delivering high-fidelity reflections and clear transmission with real-time rendering. Moreover, our factorization naturally enables flexible scene editing. The project page is available at https://sjj118.github.io/RT-Splatting.
SeaVIS: Sound-Enhanced Association for Online Audio-Visual Instance Segmentation
Mar 02, 2026Recently, an audio-visual instance segmentation (AVIS) task has been introduced, aiming to identify, segment and track individual sounding instances in videos. However, prevailing methods primarily adopt the offline paradigm, that cannot associate detected instances across consecutive clips, making them unsuitable for real-world scenarios that involve continuous video streams. To address this limitation, we introduce SeaVIS, the first online framework designed for audio-visual instance segmentation. SeaVIS leverages the Causal Cross Attention Fusion (CCAF) module to enable efficient online processing, which integrates visual features from the current frame with the entire audio history under strict causal constraints. A major challenge for conventional VIS methods is that appearance-based instance association fails to distinguish between an object's sounding and silent states, resulting in the incorrect segmentation of silent objects. To tackle this, we employ an Audio-Guided Contrastive Learning (AGCL) strategy to generate instance prototypes that encode not only visual appearance but also sounding activity. In this way, instances preserved during per-frame prediction that do not emit sound can be effectively suppressed during instance association process, thereby significantly enhancing the audio-following capability of SeaVIS. Extensive experiments conducted on the AVISeg dataset demonstrate that SeaVIS surpasses existing state-of-the-art models across multiple evaluation metrics while maintaining a competitive inference speed suitable for real-time processing.
vLinear: A Powerful Linear Model for Multivariate Time Series Forecasting
Jan 20, 2026In this paper, we present \textbf{vLinear}, an effective yet efficient \textbf{linear}-based multivariate time series forecaster featuring two components: the \textbf{v}ecTrans module and the WFMLoss objective. Many state-of-the-art forecasters rely on self-attention or its variants to capture multivariate correlations, typically incurring $\mathcal{O}(N^2)$ computational complexity with respect to the number of variates $N$. To address this, we propose vecTrans, a lightweight module that utilizes a learnable vector to model multivariate correlations, reducing the complexity to $\mathcal{O}(N)$. Notably, vecTrans can be seamlessly integrated into Transformer-based forecasters, delivering up to 5$\times$ inference speedups and consistent performance gains. Furthermore, we introduce WFMLoss (Weighted Flow Matching Loss) as the objective. In contrast to typical \textbf{velocity-oriented} flow matching objectives, we demonstrate that a \textbf{final-series-oriented} formulation yields significantly superior forecasting accuracy. WFMLoss also incorporates path- and horizon-weighted strategies to focus learning on more reliable paths and horizons. Empirically, vLinear achieves state-of-the-art performance across 22 benchmarks and 124 forecasting settings. Moreover, WFMLoss serves as an effective plug-and-play objective, consistently improving existing forecasters. The code is available at https://anonymous.4open.science/r/vLinear.
Tree-based Dialogue Reinforced Policy Optimization for Red-Teaming Attacks
Oct 02, 2025Despite recent rapid progress in AI safety, current large language models remain vulnerable to adversarial attacks in multi-turn interaction settings, where attackers strategically adapt their prompts across conversation turns and pose a more critical yet realistic challenge. Existing approaches that discover safety vulnerabilities either rely on manual red-teaming with human experts or employ automated methods using pre-defined templates and human-curated attack data, with most focusing on single-turn attacks. However, these methods did not explore the vast space of possible multi-turn attacks, failing to consider novel attack trajectories that emerge from complex dialogue dynamics and strategic conversation planning. This gap is particularly critical given recent findings that LLMs exhibit significantly higher vulnerability to multi-turn attacks compared to single-turn attacks. We propose DialTree-RPO, an on-policy reinforcement learning framework integrated with tree search that autonomously discovers diverse multi-turn attack strategies by treating the dialogue as a sequential decision-making problem, enabling systematic exploration without manually curated data. Through extensive experiments, our approach not only achieves more than 25.9% higher ASR across 10 target models compared to previous state-of-the-art approaches, but also effectively uncovers new attack strategies by learning optimal dialogue policies that maximize attack success across multiple turns.
Teacher-Guided Pseudo Supervision and Cross-Modal Alignment for Audio-Visual Video Parsing
Sep 17, 2025Weakly-supervised audio-visual video parsing (AVVP) seeks to detect audible, visible, and audio-visual events without temporal annotations. Previous work has emphasized refining global predictions through contrastive or collaborative learning, but neglected stable segment-level supervision and class-aware cross-modal alignment. To address this, we propose two strategies: (1) an exponential moving average (EMA)-guided pseudo supervision framework that generates reliable segment-level masks via adaptive thresholds or top-k selection, offering stable temporal guidance beyond video-level labels; and (2) a class-aware cross-modal agreement (CMA) loss that aligns audio and visual embeddings at reliable segment-class pairs, ensuring consistency across modalities while preserving temporal structure. Evaluations on LLP and UnAV-100 datasets shows that our method achieves state-of-the-art (SOTA) performance across multiple metrics.
TEn-CATS: Text-Enriched Audio-Visual Video Parsing with Multi-Scale Category-Aware Temporal Graph
Sep 04, 2025Audio-Visual Video Parsing (AVVP) task aims to identify event categories and their occurrence times in a given video with weakly supervised labels. Existing methods typically fall into two categories: (i) designing enhanced architectures based on attention mechanism for better temporal modeling, and (ii) generating richer pseudo-labels to compensate for the absence of frame-level annotations. However, the first type methods treat noisy segment-level pseudo labels as reliable supervision and the second type methods let indiscriminate attention spread them across all frames, the initial errors are repeatedly amplified during training. To address this issue, we propose a method that combines the Bi-Directional Text Fusion (BiT) module and Category-Aware Temporal Graph (CATS) module. Specifically, we integrate the strengths and complementarity of the two previous research directions. We first perform semantic injection and dynamic calibration on audio and visual modality features through the BiT module, to locate and purify cleaner and richer semantic cues. Then, we leverage the CATS module for semantic propagation and connection to enable precise semantic information dissemination across time. Experimental results demonstrate that our proposed method achieves state-of-the-art (SOTA) performance in multiple key indicators on two benchmark datasets, LLP and UnAV-100.
OLinear: A Linear Model for Time Series Forecasting in Orthogonally Transformed Domain
May 14, 2025



This paper presents $\mathbf{OLinear}$, a $\mathbf{linear}$-based multivariate time series forecasting model that operates in an $\mathbf{o}$rthogonally transformed domain. Recent forecasting models typically adopt the temporal forecast (TF) paradigm, which directly encode and decode time series in the time domain. However, the entangled step-wise dependencies in series data can hinder the performance of TF. To address this, some forecasters conduct encoding and decoding in the transformed domain using fixed, dataset-independent bases (e.g., sine and cosine signals in the Fourier transform). In contrast, we utilize $\mathbf{OrthoTrans}$, a data-adaptive transformation based on an orthogonal matrix that diagonalizes the series' temporal Pearson correlation matrix. This approach enables more effective encoding and decoding in the decorrelated feature domain and can serve as a plug-in module to enhance existing forecasters. To enhance the representation learning for multivariate time series, we introduce a customized linear layer, $\mathbf{NormLin}$, which employs a normalized weight matrix to capture multivariate dependencies. Empirically, the NormLin module shows a surprising performance advantage over multi-head self-attention, while requiring nearly half the FLOPs. Extensive experiments on 24 benchmarks and 140 forecasting tasks demonstrate that OLinear consistently achieves state-of-the-art performance with high efficiency. Notably, as a plug-in replacement for self-attention, the NormLin module consistently enhances Transformer-based forecasters. The code and datasets are available at https://anonymous.4open.science/r/OLinear
How to Protect Yourself from 5G Radiation? Investigating LLM Responses to Implicit Misinformation
Mar 12, 2025

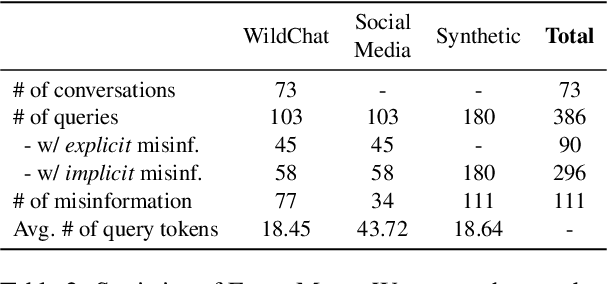
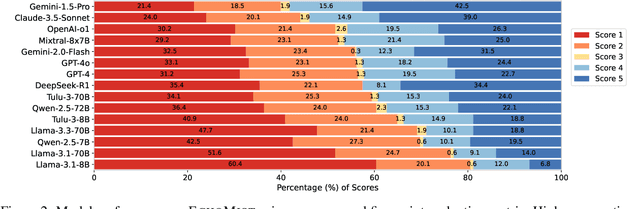
As Large Language Models (LLMs) are widely deployed in diverse scenarios, the extent to which they could tacitly spread misinformation emerges as a critical safety concern. Current research primarily evaluates LLMs on explicit false statements, overlooking how misinformation often manifests subtly as unchallenged premises in real-world user interactions. We curated ECHOMIST, the first comprehensive benchmark for implicit misinformation, where the misinformed assumptions are embedded in a user query to LLMs. ECHOMIST is based on rigorous selection criteria and carefully curated data from diverse sources, including real-world human-AI conversations and social media interactions. We also introduce a new evaluation metric to measure whether LLMs can recognize and counter false information rather than amplify users' misconceptions. Through an extensive empirical study on a wide range of LLMs, including GPT-4, Claude, and Llama, we find that current models perform alarmingly poorly on this task, often failing to detect false premises and generating misleading explanations. Our findings underscore the critical need for an increased focus on implicit misinformation in LLM safety research.
Normal-NeRF: Ambiguity-Robust Normal Estimation for Highly Reflective Scenes
Jan 16, 2025



Neural Radiance Fields (NeRF) often struggle with reconstructing and rendering highly reflective scenes. Recent advancements have developed various reflection-aware appearance models to enhance NeRF's capability to render specular reflections. However, the robust reconstruction of highly reflective scenes is still hindered by the inherent shape ambiguity on specular surfaces. Existing methods typically rely on additional geometry priors to regularize the shape prediction, but this can lead to oversmoothed geometry in complex scenes. Observing the critical role of surface normals in parameterizing reflections, we introduce a transmittance-gradient-based normal estimation technique that remains robust even under ambiguous shape conditions. Furthermore, we propose a dual activated densities module that effectively bridges the gap between smooth surface normals and sharp object boundaries. Combined with a reflection-aware appearance model, our proposed method achieves robust reconstruction and high-fidelity rendering of scenes featuring both highly specular reflections and intricate geometric structures. Extensive experiments demonstrate that our method outperforms existing state-of-the-art methods on various datasets.