 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDense Gaussian Processes for Few-Shot Segmentation
Oct 07, 2021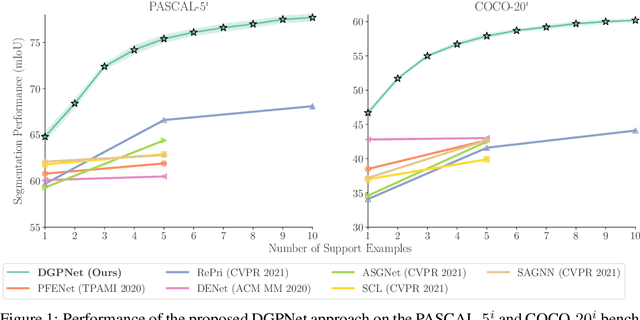
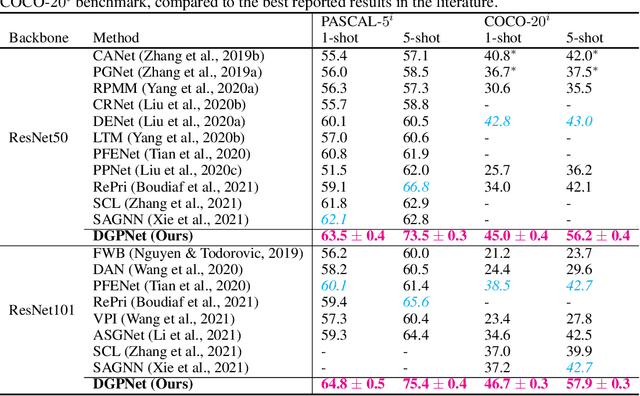
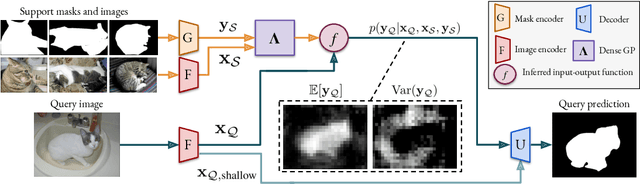

Few-shot segmentation is a challenging dense prediction task, which entails segmenting a novel query image given only a small annotated support set. The key problem is thus to design a method that aggregates detailed information from the support set, while being robust to large variations in appearance and context. To this end, we propose a few-shot segmentation method based on dense Gaussian process (GP) regression. Given the support set, our dense GP learns the mapping from local deep image features to mask values, capable of capturing complex appearance distributions. Furthermore, it provides a principled means of capturing uncertainty, which serves as another powerful cue for the final segmentation, obtained by a CNN decoder. Instead of a one-dimensional mask output, we further exploit the end-to-end learning capabilities of our approach to learn a high-dimensional output space for the GP. Our approach sets a new state-of-the-art for both 1-shot and 5-shot FSS on the PASCAL-5$^i$ and COCO-20$^i$ benchmarks, achieving an absolute gain of $+14.9$ mIoU in the COCO-20$^i$ 5-shot setting. Furthermore, the segmentation quality of our approach scales gracefully when increasing the support set size, while achieving robust cross-dataset transfer.
PDC-Net+: Enhanced Probabilistic Dense Correspondence Network
Sep 29, 2021
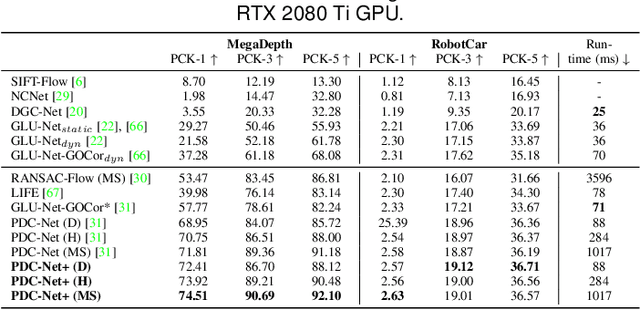
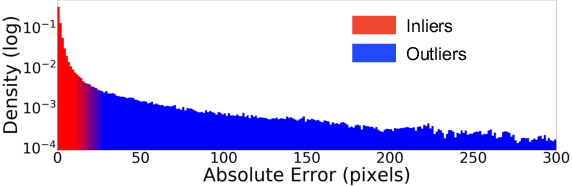
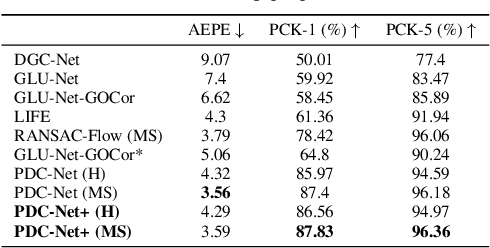
Establishing robust and accurate correspondences between a pair of images is a long-standing computer vision problem with numerous applications. While classically dominated by sparse methods, emerging dense approaches offer a compelling alternative paradigm that avoids the keypoint detection step. However, dense flow estimation is often inaccurate in the case of large displacements, occlusions, or homogeneous regions. In order to apply dense methods to real-world applications, such as pose estimation, image manipulation, or 3D reconstruction, it is therefore crucial to estimate the confidence of the predicted matches. We propose the Enhanced Probabilistic Dense Correspondence Network, PDC-Net+, capable of estimating accurate dense correspondences along with a reliable confidence map. We develop a flexible probabilistic approach that jointly learns the flow prediction and its uncertainty. In particular, we parametrize the predictive distribution as a constrained mixture model, ensuring better modelling of both accurate flow predictions and outliers. Moreover, we develop an architecture and an enhanced training strategy tailored for robust and generalizable uncertainty prediction in the context of self-supervised training. Our approach obtains state-of-the-art results on multiple challenging geometric matching and optical flow datasets. We further validate the usefulness of our probabilistic confidence estimation for the tasks of pose estimation, 3D reconstruction, image-based localization, and image retrieval. Code and models are available at https://github.com/PruneTruong/DenseMatching.
TADA: Taxonomy Adaptive Domain Adaptation
Sep 10, 2021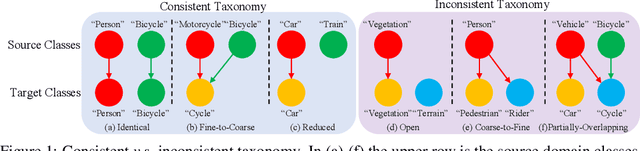
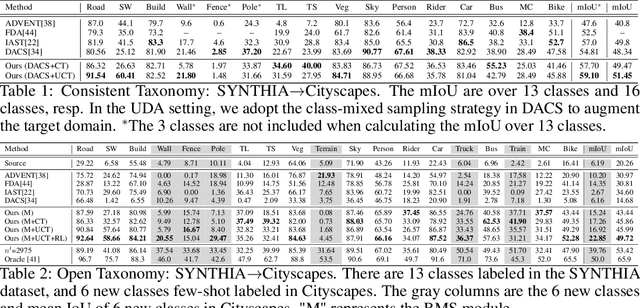
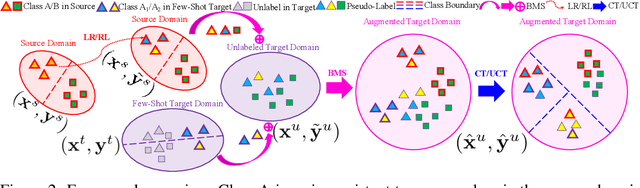
Traditional domain adaptation addresses the task of adapting a model to a novel target domain under limited or no additional supervision. While tackling the input domain gap, the standard domain adaptation settings assume no domain change in the output space. In semantic prediction tasks, different datasets are often labeled according to different semantic taxonomies. In many real-world settings, the target domain task requires a different taxonomy than the one imposed by the source domain. We therefore introduce the more general taxonomy adaptive domain adaptation (TADA) problem, allowing for inconsistent taxonomies between the two domains. We further propose an approach that jointly addresses the image-level and label-level domain adaptation. On the label-level, we employ a bilateral mixed sampling strategy to augment the target domain, and a relabelling method to unify and align the label spaces. We address the image-level domain gap by proposing an uncertainty-rectified contrastive learning method, leading to more domain-invariant and class discriminative features. We extensively evaluate the effectiveness of our framework under different TADA settings: open taxonomy, coarse-to-fine taxonomy, and partially-overlapping taxonomy. Our framework outperforms previous state-of-the-art by a large margin, while capable of adapting to new target domain taxonomies.
Deep Reparametrization of Multi-Frame Super-Resolution and Denoising
Aug 18, 2021
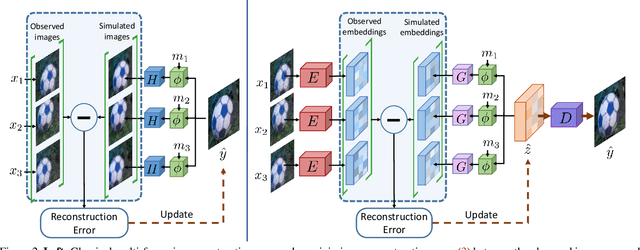


We propose a deep reparametrization of the maximum a posteriori formulation commonly employed in multi-frame image restoration tasks. Our approach is derived by introducing a learned error metric and a latent representation of the target image, which transforms the MAP objective to a deep feature space. The deep reparametrization allows us to directly model the image formation process in the latent space, and to integrate learned image priors into the prediction. Our approach thereby leverages the advantages of deep learning, while also benefiting from the principled multi-frame fusion provided by the classical MAP formulation. We validate our approach through comprehensive experiments on burst denoising and burst super-resolution datasets. Our approach sets a new state-of-the-art for both tasks, demonstrating the generality and effectiveness of the proposed formulation.
Hierarchical Conditional Flow: A Unified Framework for Image Super-Resolution and Image Rescaling
Aug 11, 2021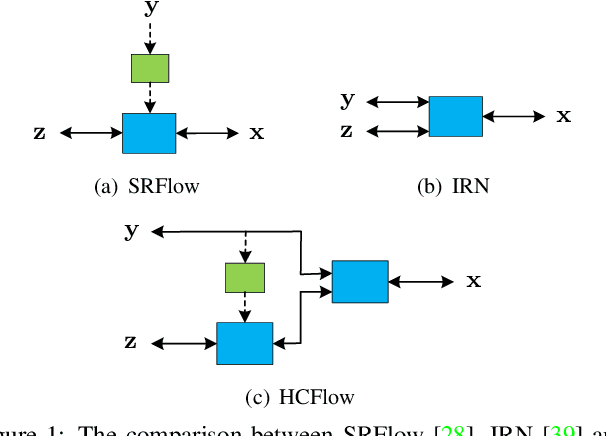

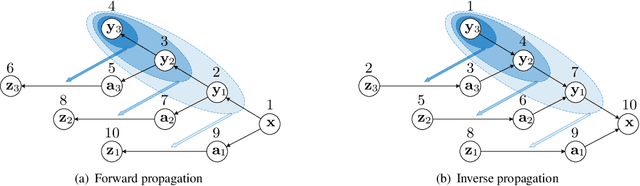
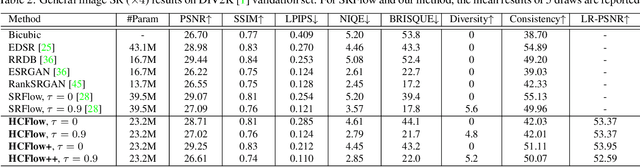
Normalizing flows have recently demonstrated promising results for low-level vision tasks. For image super-resolution (SR), it learns to predict diverse photo-realistic high-resolution (HR) images from the low-resolution (LR) image rather than learning a deterministic mapping. For image rescaling, it achieves high accuracy by jointly modelling the downscaling and upscaling processes. While existing approaches employ specialized techniques for these two tasks, we set out to unify them in a single formulation. In this paper, we propose the hierarchical conditional flow (HCFlow) as a unified framework for image SR and image rescaling. More specifically, HCFlow learns a bijective mapping between HR and LR image pairs by modelling the distribution of the LR image and the rest high-frequency component simultaneously. In particular, the high-frequency component is conditional on the LR image in a hierarchical manner. To further enhance the performance, other losses such as perceptual loss and GAN loss are combined with the commonly used negative log-likelihood loss in training. Extensive experiments on general image SR, face image SR and image rescaling have demonstrated that the proposed HCFlow achieves state-of-the-art performance in terms of both quantitative metrics and visual quality.
Prototypical Cross-Attention Networks for Multiple Object Tracking and Segmentation
Jun 22, 2021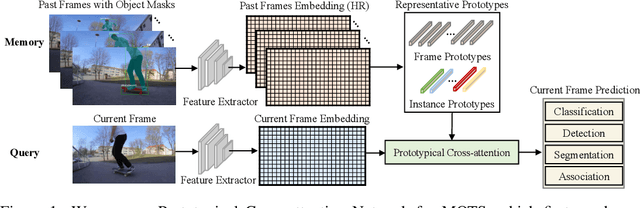
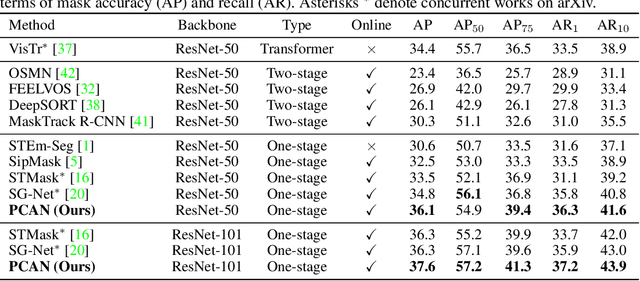
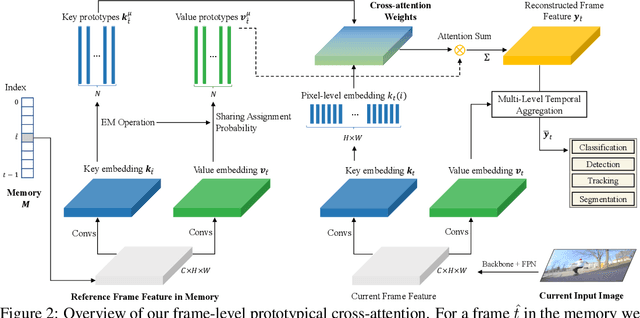

Multiple object tracking and segmentation requires detecting, tracking, and segmenting objects belonging to a set of given classes. Most approaches only exploit the temporal dimension to address the association problem, while relying on single frame predictions for the segmentation mask itself. We propose Prototypical Cross-Attention Network (PCAN), capable of leveraging rich spatio-temporal information for online multiple object tracking and segmentation. PCAN first distills a space-time memory into a set of prototypes and then employs cross-attention to retrieve rich information from the past frames. To segment each object, PCAN adopts a prototypical appearance module to learn a set of contrastive foreground and background prototypes, which are then propagated over time. Extensive experiments demonstrate that PCAN outperforms current video instance tracking and segmentation competition winners on both Youtube-VIS and BDD100K datasets, and shows efficacy to both one-stage and two-stage segmentation frameworks. Code will be available at http://vis.xyz/pub/pcan.
NTIRE 2021 Challenge on Burst Super-Resolution: Methods and Results
Jun 07, 2021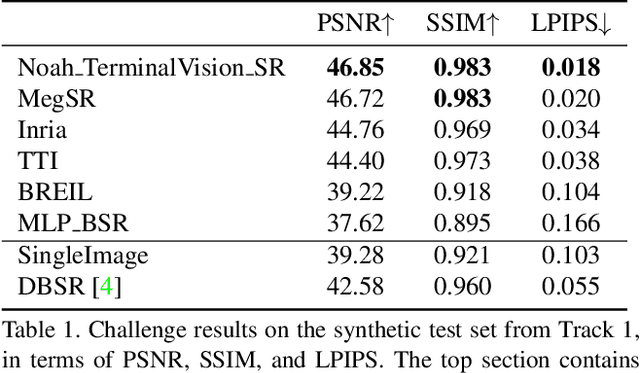

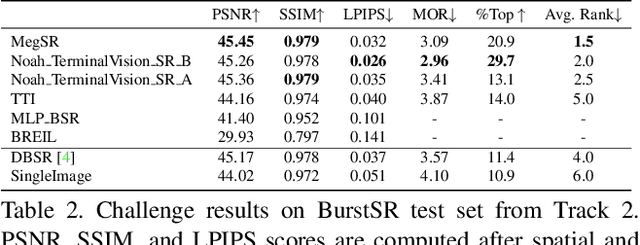

This paper reviews the NTIRE2021 challenge on burst super-resolution. Given a RAW noisy burst as input, the task in the challenge was to generate a clean RGB image with 4 times higher resolution. The challenge contained two tracks; Track 1 evaluating on synthetically generated data, and Track 2 using real-world bursts from mobile camera. In the final testing phase, 6 teams submitted results using a diverse set of solutions. The top-performing methods set a new state-of-the-art for the burst super-resolution task.
Learnable Online Graph Representations for 3D Multi-Object Tracking
Apr 23, 2021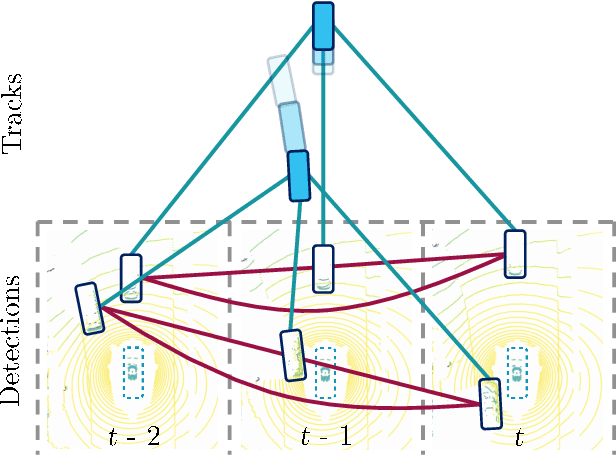

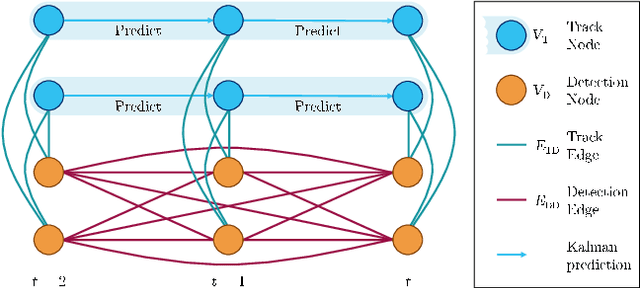
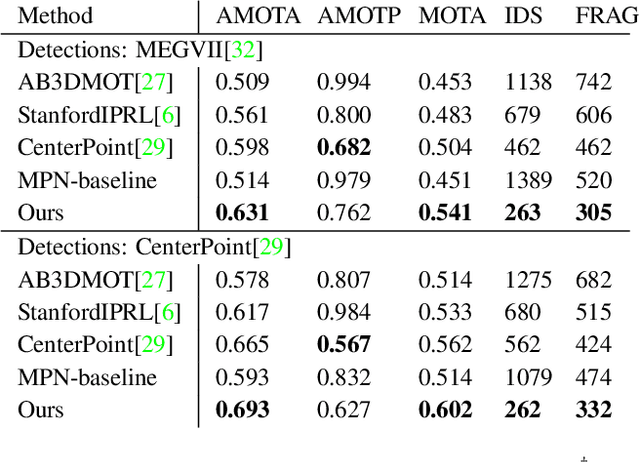
Tracking of objects in 3D is a fundamental task in computer vision that finds use in a wide range of applications such as autonomous driving, robotics or augmented reality. Most recent approaches for 3D multi object tracking (MOT) from LIDAR use object dynamics together with a set of handcrafted features to match detections of objects. However, manually designing such features and heuristics is cumbersome and often leads to suboptimal performance. In this work, we instead strive towards a unified and learning based approach to the 3D MOT problem. We design a graph structure to jointly process detection and track states in an online manner. To this end, we employ a Neural Message Passing network for data association that is fully trainable. Our approach provides a natural way for track initialization and handling of false positive detections, while significantly improving track stability. We show the merit of the proposed approach on the publicly available nuScenes dataset by achieving state-of-the-art performance of 65.6% AMOTA and 58% fewer ID-switches.
Warp Consistency for Unsupervised Learning of Dense Correspondences
Apr 08, 2021
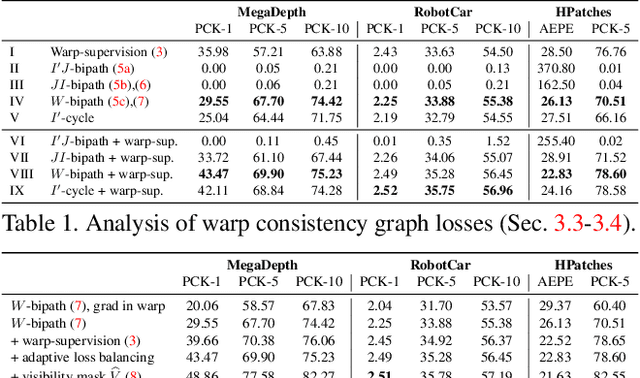

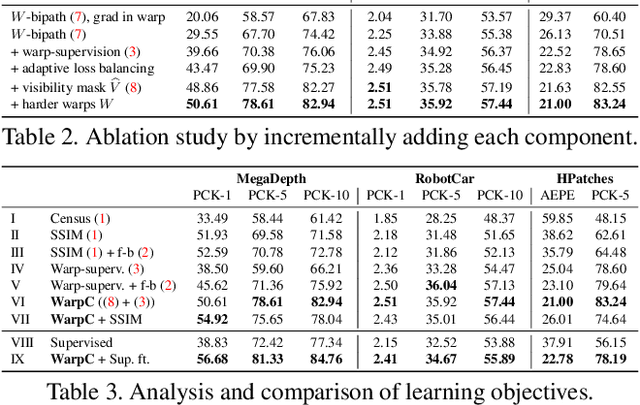
The key challenge in learning dense correspondences lies in the lack of ground-truth matches for real image pairs. While photometric consistency losses provide unsupervised alternatives, they struggle with large appearance changes, which are ubiquitous in geometric and semantic matching tasks. Moreover, methods relying on synthetic training pairs often suffer from poor generalisation to real data. We propose Warp Consistency, an unsupervised learning objective for dense correspondence regression. Our objective is effective even in settings with large appearance and view-point changes. Given a pair of real images, we first construct an image triplet by applying a randomly sampled warp to one of the original images. We derive and analyze all flow-consistency constraints arising between the triplet. From our observations and empirical results, we design a general unsupervised objective employing two of the derived constraints. We validate our warp consistency loss by training three recent dense correspondence networks for the geometric and semantic matching tasks. Our approach sets a new state-of-the-art on several challenging benchmarks, including MegaDepth, RobotCar and TSS. Code and models will be released at https://github.com/PruneTruong/DenseMatching.
Learning Target Candidate Association to Keep Track of What Not to Track
Mar 30, 2021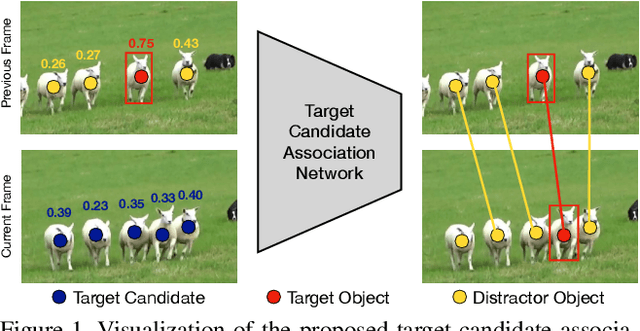

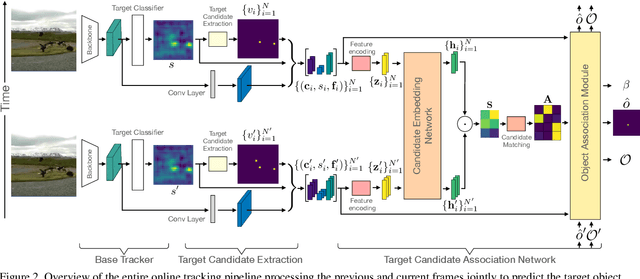

The presence of objects that are confusingly similar to the tracked target, poses a fundamental challenge in appearance-based visual tracking. Such distractor objects are easily misclassified as the target itself, leading to eventual tracking failure. While most methods strive to suppress distractors through more powerful appearance models, we take an alternative approach. We propose to keep track of distractor objects in order to continue tracking the target. To this end, we introduce a learned association network, allowing us to propagate the identities of all target candidates from frame-to-frame. To tackle the problem of lacking ground-truth correspondences between distractor objects in visual tracking, we propose a training strategy that combines partial annotations with self-supervision. We conduct comprehensive experimental validation and analysis of our approach on several challenging datasets. Our tracker sets a new state-of-the-art on six benchmarks, achieving an AUC score of 67.2% on LaSOT and a +6.1% absolute gain on the OxUvA long-term dataset.