 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIncreRTL: Traceability-Guided Incremental RTL Generation under Requirement Evolution
Mar 26, 2026Large language models (LLMs) have shown promise in generating RTL code from natural-language descriptions, but existing methods remain static and struggle to adapt to evolving design requirements, potentially causing structural drift and costly full regeneration. We propose IncreRTL, a LLM-driven framework for incremental RTL generation under requirement evolution. By constructing requirement-code traceability links to locate and regenerate affected code segments, IncreRTL achieves accurate and consistent updates. Evaluated on our newly constructed EvoRTL-Bench, IncreRTL demonstrates notable improvements in regeneration consistency and efficiency, advancing LLM-based RTL generation toward practical engineering deployment.
DynAlign: Unsupervised Dynamic Taxonomy Alignment for Cross-Domain Segmentation
Jan 27, 2025

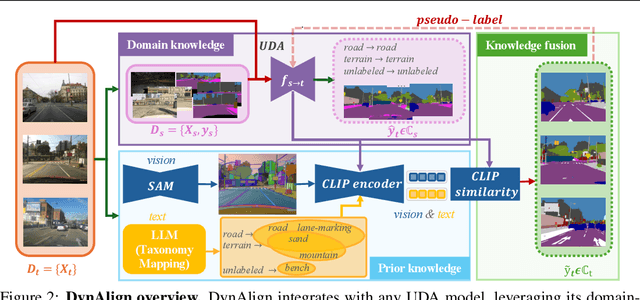
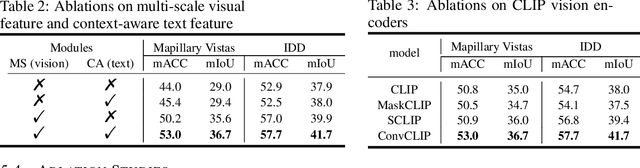
Current unsupervised domain adaptation (UDA) methods for semantic segmentation typically assume identical class labels between the source and target domains. This assumption ignores the label-level domain gap, which is common in real-world scenarios, thus limiting their ability to identify finer-grained or novel categories without requiring extensive manual annotation. A promising direction to address this limitation lies in recent advancements in foundation models, which exhibit strong generalization abilities due to their rich prior knowledge. However, these models often struggle with domain-specific nuances and underrepresented fine-grained categories. To address these challenges, we introduce DynAlign, a framework that integrates UDA with foundation models to bridge both the image-level and label-level domain gaps. Our approach leverages prior semantic knowledge to align source categories with target categories that can be novel, more fine-grained, or named differently (e.g., vehicle to {car, truck, bus}). Foundation models are then employed for precise segmentation and category reassignment. To further enhance accuracy, we propose a knowledge fusion approach that dynamically adapts to varying scene contexts. DynAlign generates accurate predictions in a new target label space without requiring any manual annotations, allowing seamless adaptation to new taxonomies through either model retraining or direct inference. Experiments on the street scene semantic segmentation benchmarks GTA to Mapillary Vistas and GTA to IDD validate the effectiveness of our approach, achieving a significant improvement over existing methods. Our code will be publicly available.
Learning Intra-view and Cross-view Geometric Knowledge for Stereo Matching
Mar 06, 2024Geometric knowledge has been shown to be beneficial for the stereo matching task. However, prior attempts to integrate geometric insights into stereo matching algorithms have largely focused on geometric knowledge from single images while crucial cross-view factors such as occlusion and matching uniqueness have been overlooked. To address this gap, we propose a novel Intra-view and Cross-view Geometric knowledge learning Network (ICGNet), specifically crafted to assimilate both intra-view and cross-view geometric knowledge. ICGNet harnesses the power of interest points to serve as a channel for intra-view geometric understanding. Simultaneously, it employs the correspondences among these points to capture cross-view geometric relationships. This dual incorporation empowers the proposed ICGNet to leverage both intra-view and cross-view geometric knowledge in its learning process, substantially improving its ability to estimate disparities. Our extensive experiments demonstrate the superiority of the ICGNet over contemporary leading models.
Prompting Diffusion Representations for Cross-Domain Semantic Segmentation
Jul 05, 2023While originally designed for image generation, diffusion models have recently shown to provide excellent pretrained feature representations for semantic segmentation. Intrigued by this result, we set out to explore how well diffusion-pretrained representations generalize to new domains, a crucial ability for any representation. We find that diffusion-pretraining achieves extraordinary domain generalization results for semantic segmentation, outperforming both supervised and self-supervised backbone networks. Motivated by this, we investigate how to utilize the model's unique ability of taking an input prompt, in order to further enhance its cross-domain performance. We introduce a scene prompt and a prompt randomization strategy to help further disentangle the domain-invariant information when training the segmentation head. Moreover, we propose a simple but highly effective approach for test-time domain adaptation, based on learning a scene prompt on the target domain in an unsupervised manner. Extensive experiments conducted on four synthetic-to-real and clear-to-adverse weather benchmarks demonstrate the effectiveness of our approaches. Without resorting to any complex techniques, such as image translation, augmentation, or rare-class sampling, we set a new state-of-the-art on all benchmarks. Our implementation will be publicly available at \url{https://github.com/ETHRuiGong/PTDiffSeg}.
SF-FSDA: Source-Free Few-Shot Domain Adaptive Object Detection with Efficient Labeled Data Factory
Jun 07, 2023Domain adaptive object detection aims to leverage the knowledge learned from a labeled source domain to improve the performance on an unlabeled target domain. Prior works typically require the access to the source domain data for adaptation, and the availability of sufficient data on the target domain. However, these assumptions may not hold due to data privacy and rare data collection. In this paper, we propose and investigate a more practical and challenging domain adaptive object detection problem under both source-free and few-shot conditions, named as SF-FSDA. To overcome this problem, we develop an efficient labeled data factory based approach. Without accessing the source domain, the data factory renders i) infinite amount of synthesized target-domain like images, under the guidance of the few-shot image samples and text description from the target domain; ii) corresponding bounding box and category annotations, only demanding minimum human effort, i.e., a few manually labeled examples. On the one hand, the synthesized images mitigate the knowledge insufficiency brought by the few-shot condition. On the other hand, compared to the popular pseudo-label technique, the generated annotations from data factory not only get rid of the reliance on the source pretrained object detection model, but also alleviate the unavoidably pseudo-label noise due to domain shift and source-free condition. The generated dataset is further utilized to adapt the source pretrained object detection model, realizing the robust object detection under SF-FSDA. The experiments on different settings showcase that our proposed approach outperforms other state-of-the-art methods on SF-FSDA problem. Our codes and models will be made publicly available.
One-Shot Domain Adaptive and Generalizable Semantic Segmentation with Class-Aware Cross-Domain Transformers
Dec 14, 2022Unsupervised sim-to-real domain adaptation (UDA) for semantic segmentation aims to improve the real-world test performance of a model trained on simulated data. It can save the cost of manually labeling data in real-world applications such as robot vision and autonomous driving. Traditional UDA often assumes that there are abundant unlabeled real-world data samples available during training for the adaptation. However, such an assumption does not always hold in practice owing to the collection difficulty and the scarcity of the data. Thus, we aim to relieve this need on a large number of real data, and explore the one-shot unsupervised sim-to-real domain adaptation (OSUDA) and generalization (OSDG) problem, where only one real-world data sample is available. To remedy the limited real data knowledge, we first construct the pseudo-target domain by stylizing the simulated data with the one-shot real data. To mitigate the sim-to-real domain gap on both the style and spatial structure level and facilitate the sim-to-real adaptation, we further propose to use class-aware cross-domain transformers with an intermediate domain randomization strategy to extract the domain-invariant knowledge, from both the simulated and pseudo-target data. We demonstrate the effectiveness of our approach for OSUDA and OSDG on different benchmarks, outperforming the state-of-the-art methods by a large margin, 10.87, 9.59, 13.05 and 15.91 mIoU on GTA, SYNTHIA$\rightarrow$Cityscapes, Foggy Cityscapes, respectively.
GGViT:Multistream Vision Transformer Network in Face2Face Facial Reenactment Detection
Oct 12, 2022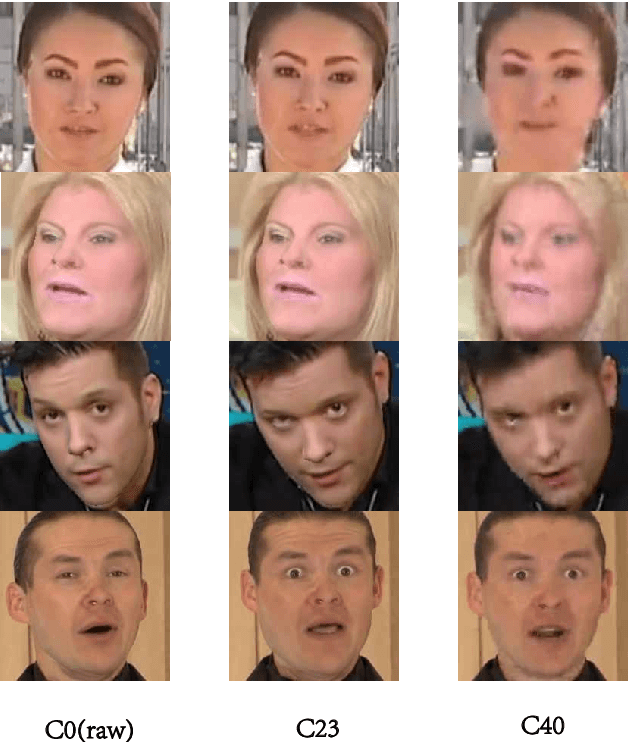

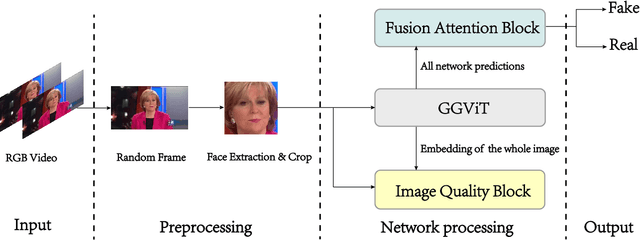
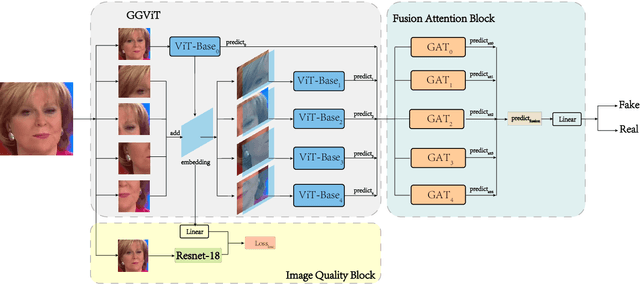
Detecting manipulated facial images and videos on social networks has been an urgent problem to be solved. The compression of videos on social media has destroyed some pixel details that could be used to detect forgeries. Hence, it is crucial to detect manipulated faces in videos of different quality. We propose a new multi-stream network architecture named GGViT, which utilizes global information to improve the generalization of the model. The embedding of the whole face extracted by ViT will guide each stream network. Through a large number of experiments, we have proved that our proposed model achieves state-of-the-art classification accuracy on FF++ dataset, and has been greatly improved on scenarios of different compression rates. The accuracy of Raw/C23, Raw/C40 and C23/C40 was increased by 24.34%, 15.08% and 10.14% respectively.
TADA: Taxonomy Adaptive Domain Adaptation
Sep 10, 2021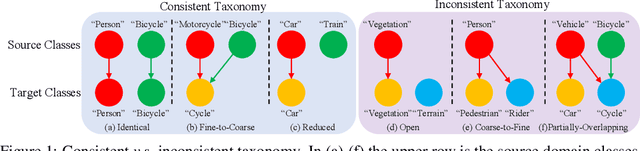
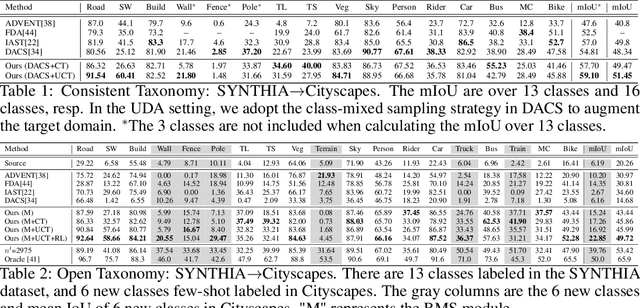
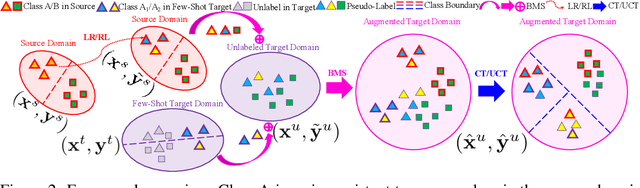
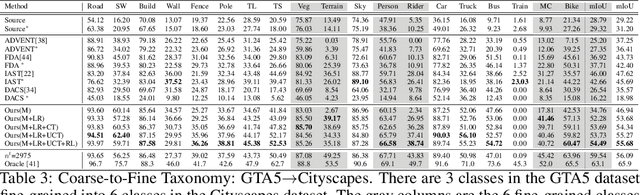
Traditional domain adaptation addresses the task of adapting a model to a novel target domain under limited or no additional supervision. While tackling the input domain gap, the standard domain adaptation settings assume no domain change in the output space. In semantic prediction tasks, different datasets are often labeled according to different semantic taxonomies. In many real-world settings, the target domain task requires a different taxonomy than the one imposed by the source domain. We therefore introduce the more general taxonomy adaptive domain adaptation (TADA) problem, allowing for inconsistent taxonomies between the two domains. We further propose an approach that jointly addresses the image-level and label-level domain adaptation. On the label-level, we employ a bilateral mixed sampling strategy to augment the target domain, and a relabelling method to unify and align the label spaces. We address the image-level domain gap by proposing an uncertainty-rectified contrastive learning method, leading to more domain-invariant and class discriminative features. We extensively evaluate the effectiveness of our framework under different TADA settings: open taxonomy, coarse-to-fine taxonomy, and partially-overlapping taxonomy. Our framework outperforms previous state-of-the-art by a large margin, while capable of adapting to new target domain taxonomies.
Self-Supervised Pretraining and Controlled Augmentation Improve Rare Wildlife Recognition in UAV Images
Aug 17, 2021



Automated animal censuses with aerial imagery are a vital ingredient towards wildlife conservation. Recent models are generally based on deep learning and thus require vast amounts of training data. Due to their scarcity and minuscule size, annotating animals in aerial imagery is a highly tedious process. In this project, we present a methodology to reduce the amount of required training data by resorting to self-supervised pretraining. In detail, we examine a combination of recent contrastive learning methodologies like Momentum Contrast (MoCo) and Cross-Level Instance-Group Discrimination (CLD) to condition our model on the aerial images without the requirement for labels. We show that a combination of MoCo, CLD, and geometric augmentations outperforms conventional models pre-trained on ImageNet by a large margin. Crucially, our method still yields favorable results even if we reduce the number of training animals to just 10%, at which point our best model scores double the recall of the baseline at similar precision. This effectively allows reducing the number of required annotations to a fraction while still being able to train high-accuracy models in such highly challenging settings.
A Plant Root System Algorithm Based on Swarm Intelligence for One-dimensional Biomedical Signal Feature Engineering
Jul 31, 2021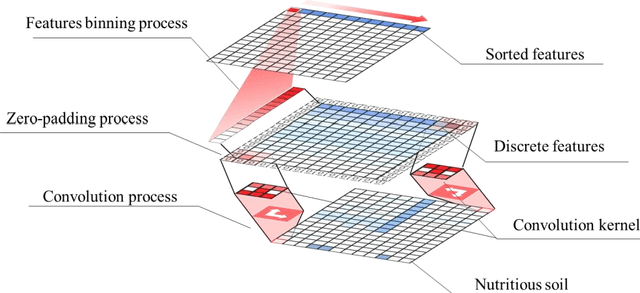
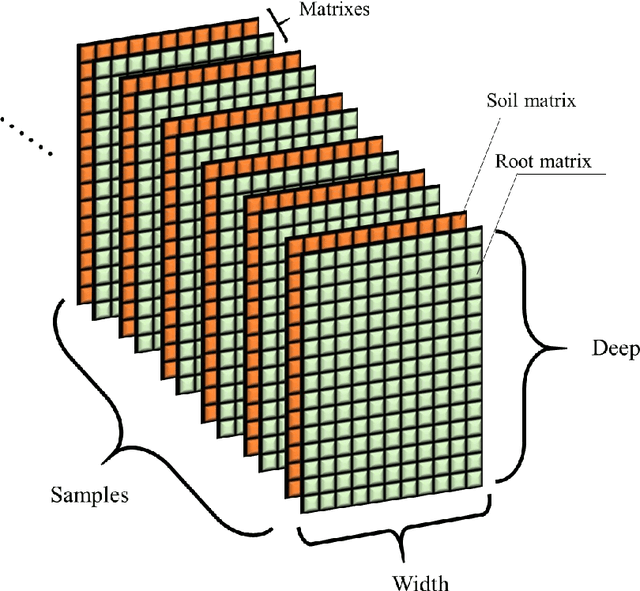

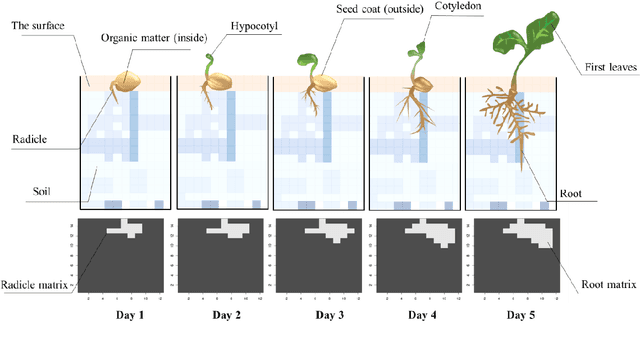
To date, very few biomedical signals have transitioned from research applications to clinical applications. This is largely due to the lack of trust in the diagnostic ability of non-stationary signals. To reach the level of clinical diagnostic application, classification using high-quality signal features is necessary. While there has been considerable progress in machine learning in recent years, especially deep learning, progress has been quite limited in the field of feature engineering. This study proposes a feature extraction algorithm based on group intelligence which we call a Plant Root System (PRS) algorithm. Importantly, the correlation between features produced by this PRS algorithm and traditional features is low, and the accuracy of several widely-used classifiers was found to be substantially improved with the addition of PRS features. It is expected that more biomedical signals can be applied to clinical diagnosis using the proposed algorithm.