 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding What Is Not Said:Referring Remote Sensing Image Segmentation with Scarce Expressions
Oct 26, 2025Referring Remote Sensing Image Segmentation (RRSIS) aims to segment instances in remote sensing images according to referring expressions. Unlike Referring Image Segmentation on general images, acquiring high-quality referring expressions in the remote sensing domain is particularly challenging due to the prevalence of small, densely distributed objects and complex backgrounds. This paper introduces a new learning paradigm, Weakly Referring Expression Learning (WREL) for RRSIS, which leverages abundant class names as weakly referring expressions together with a small set of accurate ones to enable efficient training under limited annotation conditions. Furthermore, we provide a theoretical analysis showing that mixed-referring training yields a provable upper bound on the performance gap relative to training with fully annotated referring expressions, thereby establishing the validity of this new setting. We also propose LRB-WREL, which integrates a Learnable Reference Bank (LRB) to refine weakly referring expressions through sample-specific prompt embeddings that enrich coarse class-name inputs. Combined with a teacher-student optimization framework using dynamically scheduled EMA updates, LRB-WREL stabilizes training and enhances cross-modal generalization under noisy weakly referring supervision. Extensive experiments on our newly constructed benchmark with varying weakly referring data ratios validate both the theoretical insights and the practical effectiveness of WREL and LRB-WREL, demonstrating that they can approach or even surpass models trained with fully annotated referring expressions.
SCOUT: Semi-supervised Camouflaged Object Detection by Utilizing Text and Adaptive Data Selection
Aug 25, 2025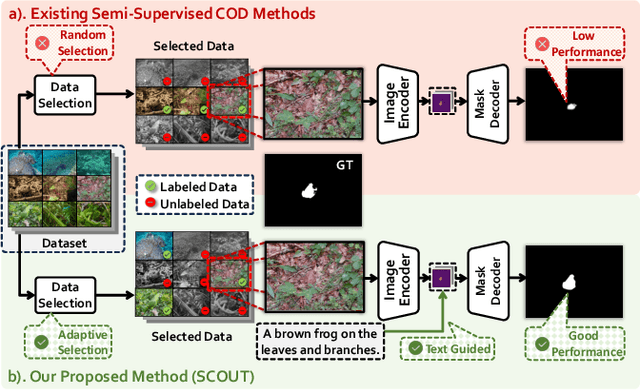

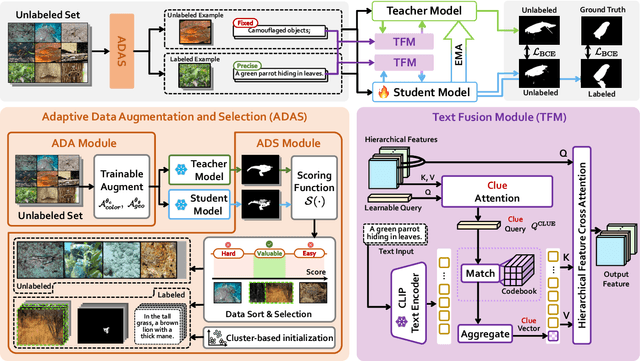

The difficulty of pixel-level annotation has significantly hindered the development of the Camouflaged Object Detection (COD) field. To save on annotation costs, previous works leverage the semi-supervised COD framework that relies on a small number of labeled data and a large volume of unlabeled data. We argue that there is still significant room for improvement in the effective utilization of unlabeled data. To this end, we introduce a Semi-supervised Camouflaged Object Detection by Utilizing Text and Adaptive Data Selection (SCOUT). It includes an Adaptive Data Augment and Selection (ADAS) module and a Text Fusion Module (TFM). The ADSA module selects valuable data for annotation through an adversarial augment and sampling strategy. The TFM module further leverages the selected valuable data by combining camouflage-related knowledge and text-visual interaction. To adapt to this work, we build a new dataset, namely RefTextCOD. Extensive experiments show that the proposed method surpasses previous semi-supervised methods in the COD field and achieves state-of-the-art performance. Our code will be released at https://github.com/Heartfirey/SCOUT.
MIHBench: Benchmarking and Mitigating Multi-Image Hallucinations in Multimodal Large Language Models
Aug 01, 2025Despite growing interest in hallucination in Multimodal Large Language Models, existing studies primarily focus on single-image settings, leaving hallucination in multi-image scenarios largely unexplored. To address this gap, we conduct the first systematic study of hallucinations in multi-image MLLMs and propose MIHBench, a benchmark specifically tailored for evaluating object-related hallucinations across multiple images. MIHBench comprises three core tasks: Multi-Image Object Existence Hallucination, Multi-Image Object Count Hallucination, and Object Identity Consistency Hallucination, targeting semantic understanding across object existence, quantity reasoning, and cross-view identity consistency. Through extensive evaluation, we identify key factors associated with the occurrence of multi-image hallucinations, including: a progressive relationship between the number of image inputs and the likelihood of hallucination occurrences; a strong correlation between single-image hallucination tendencies and those observed in multi-image contexts; and the influence of same-object image ratios and the positional placement of negative samples within image sequences on the occurrence of object identity consistency hallucination. To address these challenges, we propose a Dynamic Attention Balancing mechanism that adjusts inter-image attention distributions while preserving the overall visual attention proportion. Experiments across multiple state-of-the-art MLLMs demonstrate that our method effectively reduces hallucination occurrences and enhances semantic integration and reasoning stability in multi-image scenarios.
RIS-LAD: A Benchmark and Model for Referring Low-Altitude Drone Image Segmentation
Jul 28, 2025Referring Image Segmentation (RIS), which aims to segment specific objects based on natural language descriptions, plays an essential role in vision-language understanding. Despite its progress in remote sensing applications, RIS in Low-Altitude Drone (LAD) scenarios remains underexplored. Existing datasets and methods are typically designed for high-altitude and static-view imagery. They struggle to handle the unique characteristics of LAD views, such as diverse viewpoints and high object density. To fill this gap, we present RIS-LAD, the first fine-grained RIS benchmark tailored for LAD scenarios. This dataset comprises 13,871 carefully annotated image-text-mask triplets collected from realistic drone footage, with a focus on small, cluttered, and multi-viewpoint scenes. It highlights new challenges absent in previous benchmarks, such as category drift caused by tiny objects and object drift under crowded same-class objects. To tackle these issues, we propose the Semantic-Aware Adaptive Reasoning Network (SAARN). Rather than uniformly injecting all linguistic features, SAARN decomposes and routes semantic information to different stages of the network. Specifically, the Category-Dominated Linguistic Enhancement (CDLE) aligns visual features with object categories during early encoding, while the Adaptive Reasoning Fusion Module (ARFM) dynamically selects semantic cues across scales to improve reasoning in complex scenes. The experimental evaluation reveals that RIS-LAD presents substantial challenges to state-of-the-art RIS algorithms, and also demonstrates the effectiveness of our proposed model in addressing these challenges. The dataset and code will be publicly released soon at: https://github.com/AHideoKuzeA/RIS-LAD/.
DeOcc-1-to-3: 3D De-Occlusion from a Single Image via Self-Supervised Multi-View Diffusion
Jun 26, 2025Reconstructing 3D objects from a single image is a long-standing challenge, especially under real-world occlusions. While recent diffusion-based view synthesis models can generate consistent novel views from a single RGB image, they generally assume fully visible inputs and fail when parts of the object are occluded. This leads to inconsistent views and degraded 3D reconstruction quality. To overcome this limitation, we propose an end-to-end framework for occlusion-aware multi-view generation. Our method directly synthesizes six structurally consistent novel views from a single partially occluded image, enabling downstream 3D reconstruction without requiring prior inpainting or manual annotations. We construct a self-supervised training pipeline using the Pix2Gestalt dataset, leveraging occluded-unoccluded image pairs and pseudo-ground-truth views to teach the model structure-aware completion and view consistency. Without modifying the original architecture, we fully fine-tune the view synthesis model to jointly learn completion and multi-view generation. Additionally, we introduce the first benchmark for occlusion-aware reconstruction, encompassing diverse occlusion levels, object categories, and mask patterns. This benchmark provides a standardized protocol for evaluating future methods under partial occlusions. Our code is available at https://github.com/Quyans/DeOcc123.
UCOD-DPL: Unsupervised Camouflaged Object Detection via Dynamic Pseudo-label Learning
Jun 08, 2025Unsupervised Camoflaged Object Detection (UCOD) has gained attention since it doesn't need to rely on extensive pixel-level labels. Existing UCOD methods typically generate pseudo-labels using fixed strategies and train 1 x1 convolutional layers as a simple decoder, leading to low performance compared to fully-supervised methods. We emphasize two drawbacks in these approaches: 1). The model is prone to fitting incorrect knowledge due to the pseudo-label containing substantial noise. 2). The simple decoder fails to capture and learn the semantic features of camouflaged objects, especially for small-sized objects, due to the low-resolution pseudo-labels and severe confusion between foreground and background pixels. To this end, we propose a UCOD method with a teacher-student framework via Dynamic Pseudo-label Learning called UCOD-DPL, which contains an Adaptive Pseudo-label Module (APM), a Dual-Branch Adversarial (DBA) decoder, and a Look-Twice mechanism. The APM module adaptively combines pseudo-labels generated by fixed strategies and the teacher model to prevent the model from overfitting incorrect knowledge while preserving the ability for self-correction; the DBA decoder takes adversarial learning of different segmentation objectives, guides the model to overcome the foreground-background confusion of camouflaged objects, and the Look-Twice mechanism mimics the human tendency to zoom in on camouflaged objects and performs secondary refinement on small-sized objects. Extensive experiments show that our method demonstrates outstanding performance, even surpassing some existing fully supervised methods. The code is available now.
What You Perceive Is What You Conceive: A Cognition-Inspired Framework for Open Vocabulary Image Segmentation
May 26, 2025



Open vocabulary image segmentation tackles the challenge of recognizing dynamically adjustable, predefined novel categories at inference time by leveraging vision-language alignment. However, existing paradigms typically perform class-agnostic region segmentation followed by category matching, which deviates from the human visual system's process of recognizing objects based on semantic concepts, leading to poor alignment between region segmentation and target concepts. To bridge this gap, we propose a novel Cognition-Inspired Framework for open vocabulary image segmentation that emulates the human visual recognition process: first forming a conceptual understanding of an object, then perceiving its spatial extent. The framework consists of three core components: (1) A Generative Vision-Language Model (G-VLM) that mimics human cognition by generating object concepts to provide semantic guidance for region segmentation. (2) A Concept-Aware Visual Enhancer Module that fuses textual concept features with global visual representations, enabling adaptive visual perception based on target concepts. (3) A Cognition-Inspired Decoder that integrates local instance features with G-VLM-provided semantic cues, allowing selective classification over a subset of relevant categories. Extensive experiments demonstrate that our framework achieves significant improvements, reaching $27.2$ PQ, $17.0$ mAP, and $35.3$ mIoU on A-150. It further attains $56.2$, $28.2$, $15.4$, $59.2$, $18.7$, and $95.8$ mIoU on Cityscapes, Mapillary Vistas, A-847, PC-59, PC-459, and PAS-20, respectively. In addition, our framework supports vocabulary-free segmentation, offering enhanced flexibility in recognizing unseen categories. Code will be public.
Pseudo-Label Quality Decoupling and Correction for Semi-Supervised Instance Segmentation
May 16, 2025Semi-Supervised Instance Segmentation (SSIS) involves classifying and grouping image pixels into distinct object instances using limited labeled data. This learning paradigm usually faces a significant challenge of unstable performance caused by noisy pseudo-labels of instance categories and pixel masks. We find that the prevalent practice of filtering instance pseudo-labels assessing both class and mask quality with a single score threshold, frequently leads to compromises in the trade-off between the qualities of class and mask labels. In this paper, we introduce a novel Pseudo-Label Quality Decoupling and Correction (PL-DC) framework for SSIS to tackle the above challenges. Firstly, at the instance level, a decoupled dual-threshold filtering mechanism is designed to decouple class and mask quality estimations for instance-level pseudo-labels, thereby independently controlling pixel classifying and grouping qualities. Secondly, at the category level, we introduce a dynamic instance category correction module to dynamically correct the pseudo-labels of instance categories, effectively alleviating category confusion. Lastly, we introduce a pixel-level mask uncertainty-aware mechanism at the pixel level to re-weight the mask loss for different pixels, thereby reducing the impact of noise introduced by pixel-level mask pseudo-labels. Extensive experiments on the COCO and Cityscapes datasets demonstrate that the proposed PL-DC achieves significant performance improvements, setting new state-of-the-art results for SSIS. Notably, our PL-DC shows substantial gains even with minimal labeled data, achieving an improvement of +11.6 mAP with just 1% COCO labeled data and +15.5 mAP with 5% Cityscapes labeled data. The code will be public.
Purifying, Labeling, and Utilizing: A High-Quality Pipeline for Small Object Detection
Apr 29, 2025Small object detection is a broadly investigated research task and is commonly conceptualized as a "pipeline-style" engineering process. In the upstream, images serve as raw materials for processing in the detection pipeline, where pre-trained models are employed to generate initial feature maps. In the midstream, an assigner selects training positive and negative samples. Subsequently, these samples and features are fed into the downstream for classification and regression. Previous small object detection methods often focused on improving isolated stages of the pipeline, thereby neglecting holistic optimization and consequently constraining overall performance gains. To address this issue, we have optimized three key aspects, namely Purifying, Labeling, and Utilizing, in this pipeline, proposing a high-quality Small object detection framework termed PLUSNet. Specifically, PLUSNet comprises three sequential components: the Hierarchical Feature Purifier (HFP) for purifying upstream features, the Multiple Criteria Label Assignment (MCLA) for improving the quality of midstream training samples, and the Frequency Decoupled Head (FDHead) for more effectively exploiting information to accomplish downstream tasks. The proposed PLUS modules are readily integrable into various object detectors, thus enhancing their detection capabilities in multi-scale scenarios. Extensive experiments demonstrate the proposed PLUSNet consistently achieves significant and consistent improvements across multiple datasets for small object detection.
SynergyAmodal: Deocclude Anything with Text Control
Apr 28, 2025

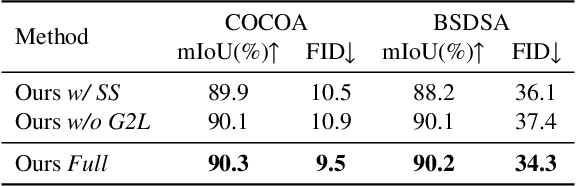
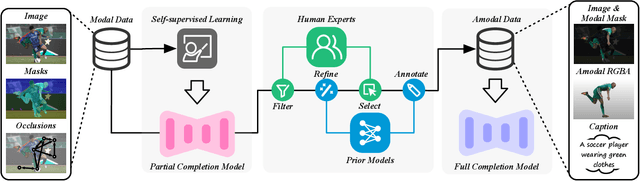
Image deocclusion (or amodal completion) aims to recover the invisible regions (\ie, shape and appearance) of occluded instances in images. Despite recent advances, the scarcity of high-quality data that balances diversity, plausibility, and fidelity remains a major obstacle. To address this challenge, we identify three critical elements: leveraging in-the-wild image data for diversity, incorporating human expertise for plausibility, and utilizing generative priors for fidelity. We propose SynergyAmodal, a novel framework for co-synthesizing in-the-wild amodal datasets with comprehensive shape and appearance annotations, which integrates these elements through a tripartite data-human-model collaboration. First, we design an occlusion-grounded self-supervised learning algorithm to harness the diversity of in-the-wild image data, fine-tuning an inpainting diffusion model into a partial completion diffusion model. Second, we establish a co-synthesis pipeline to iteratively filter, refine, select, and annotate the initial deocclusion results of the partial completion diffusion model, ensuring plausibility and fidelity through human expert guidance and prior model constraints. This pipeline generates a high-quality paired amodal dataset with extensive category and scale diversity, comprising approximately 16K pairs. Finally, we train a full completion diffusion model on the synthesized dataset, incorporating text prompts as conditioning signals. Extensive experiments demonstrate the effectiveness of our framework in achieving zero-shot generalization and textual controllability. Our code, dataset, and models will be made publicly available at https://github.com/imlixinyang/SynergyAmodal.