 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFair Deepfake Detectors Can Generalize
Jul 03, 2025Deepfake detection models face two critical challenges: generalization to unseen manipulations and demographic fairness among population groups. However, existing approaches often demonstrate that these two objectives are inherently conflicting, revealing a trade-off between them. In this paper, we, for the first time, uncover and formally define a causal relationship between fairness and generalization. Building on the back-door adjustment, we show that controlling for confounders (data distribution and model capacity) enables improved generalization via fairness interventions. Motivated by this insight, we propose Demographic Attribute-insensitive Intervention Detection (DAID), a plug-and-play framework composed of: i) Demographic-aware data rebalancing, which employs inverse-propensity weighting and subgroup-wise feature normalization to neutralize distributional biases; and ii) Demographic-agnostic feature aggregation, which uses a novel alignment loss to suppress sensitive-attribute signals. Across three cross-domain benchmarks, DAID consistently achieves superior performance in both fairness and generalization compared to several state-of-the-art detectors, validating both its theoretical foundation and practical effectiveness.
KEPLA: A Knowledge-Enhanced Deep Learning Framework for Accurate Protein-Ligand Binding Affinity Prediction
Jun 16, 2025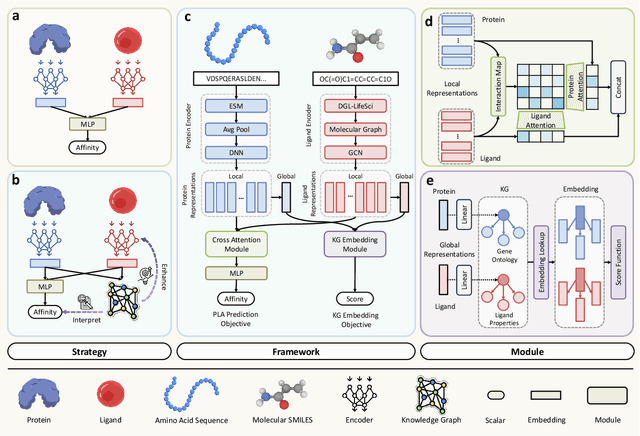
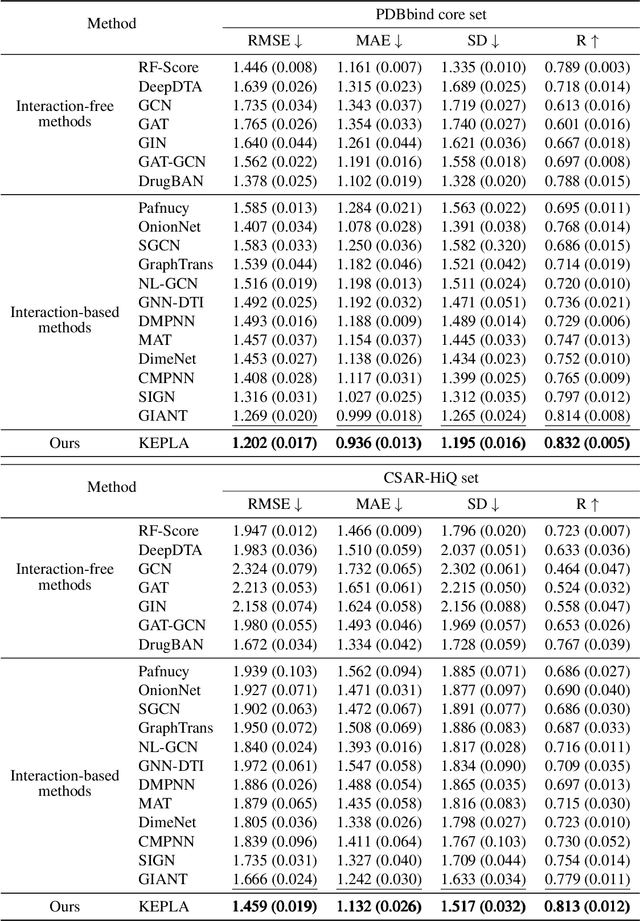
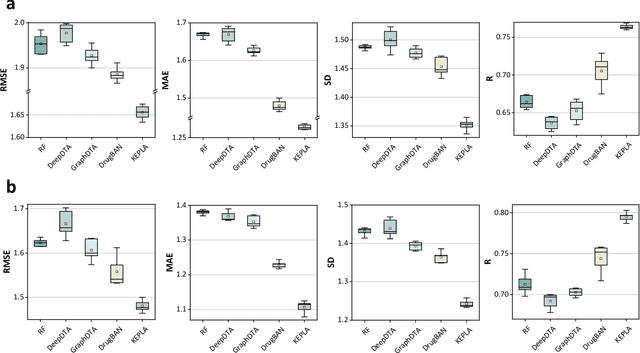
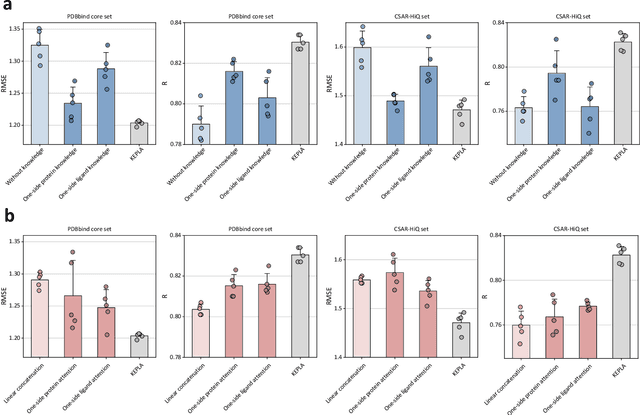
Accurate prediction of protein-ligand binding affinity is critical for drug discovery. While recent deep learning approaches have demonstrated promising results, they often rely solely on structural features, overlooking valuable biochemical knowledge associated with binding affinity. To address this limitation, we propose KEPLA, a novel deep learning framework that explicitly integrates prior knowledge from Gene Ontology and ligand properties of proteins and ligands to enhance prediction performance. KEPLA takes protein sequences and ligand molecular graphs as input and optimizes two complementary objectives: (1) aligning global representations with knowledge graph relations to capture domain-specific biochemical insights, and (2) leveraging cross attention between local representations to construct fine-grained joint embeddings for prediction. Experiments on two benchmark datasets across both in-domain and cross-domain scenarios demonstrate that KEPLA consistently outperforms state-of-the-art baselines. Furthermore, interpretability analyses based on knowledge graph relations and cross attention maps provide valuable insights into the underlying predictive mechanisms.
Mitigating Hallucination Through Theory-Consistent Symmetric Multimodal Preference Optimization
Jun 13, 2025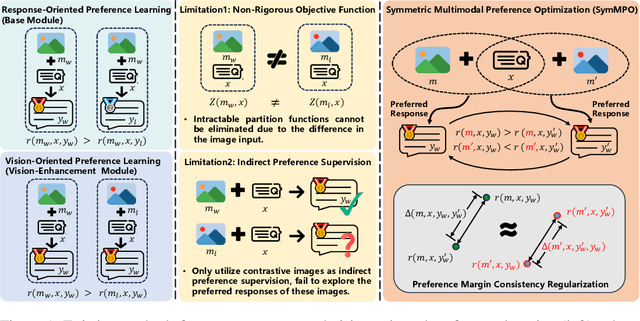

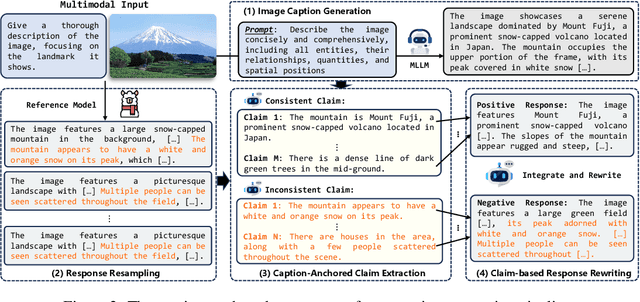

Direct Preference Optimization (DPO) has emerged as an effective approach for mitigating hallucination in Multimodal Large Language Models (MLLMs). Although existing methods have achieved significant progress by utilizing vision-oriented contrastive objectives for enhancing MLLMs' attention to visual inputs and hence reducing hallucination, they suffer from non-rigorous optimization objective function and indirect preference supervision. To address these limitations, we propose a Symmetric Multimodal Preference Optimization (SymMPO), which conducts symmetric preference learning with direct preference supervision (i.e., response pairs) for visual understanding enhancement, while maintaining rigorous theoretical alignment with standard DPO. In addition to conventional ordinal preference learning, SymMPO introduces a preference margin consistency loss to quantitatively regulate the preference gap between symmetric preference pairs. Comprehensive evaluation across five benchmarks demonstrate SymMPO's superior performance, validating its effectiveness in hallucination mitigation of MLLMs.
Optimus-3: Towards Generalist Multimodal Minecraft Agents with Scalable Task Experts
Jun 12, 2025



Recently, agents based on multimodal large language models (MLLMs) have achieved remarkable progress across various domains. However, building a generalist agent with capabilities such as perception, planning, action, grounding, and reflection in open-world environments like Minecraft remains challenges: insufficient domain-specific data, interference among heterogeneous tasks, and visual diversity in open-world settings. In this paper, we address these challenges through three key contributions. 1) We propose a knowledge-enhanced data generation pipeline to provide scalable and high-quality training data for agent development. 2) To mitigate interference among heterogeneous tasks, we introduce a Mixture-of-Experts (MoE) architecture with task-level routing. 3) We develop a Multimodal Reasoning-Augmented Reinforcement Learning approach to enhance the agent's reasoning ability for visual diversity in Minecraft. Built upon these innovations, we present Optimus-3, a general-purpose agent for Minecraft. Extensive experimental results demonstrate that Optimus-3 surpasses both generalist multimodal large language models and existing state-of-the-art agents across a wide range of tasks in the Minecraft environment. Project page: https://cybertronagent.github.io/Optimus-3.github.io/
Mirage-1: Augmenting and Updating GUI Agent with Hierarchical Multimodal Skills
Jun 12, 2025



Recent efforts to leverage the Multi-modal Large Language Model (MLLM) as GUI agents have yielded promising outcomes. However, these agents still struggle with long-horizon tasks in online environments, primarily due to insufficient knowledge and the inherent gap between offline and online domains. In this paper, inspired by how humans generalize knowledge in open-ended environments, we propose a Hierarchical Multimodal Skills (HMS) module to tackle the issue of insufficient knowledge. It progressively abstracts trajectories into execution skills, core skills, and ultimately meta-skills, providing a hierarchical knowledge structure for long-horizon task planning. To bridge the domain gap, we propose the Skill-Augmented Monte Carlo Tree Search (SA-MCTS) algorithm, which efficiently leverages skills acquired in offline environments to reduce the action search space during online tree exploration. Building on HMS, we propose Mirage-1, a multimodal, cross-platform, plug-and-play GUI agent. To validate the performance of Mirage-1 in real-world long-horizon scenarios, we constructed a new benchmark, AndroidLH. Experimental results show that Mirage-1 outperforms previous agents by 32\%, 19\%, 15\%, and 79\% on AndroidWorld, MobileMiniWob++, Mind2Web-Live, and AndroidLH, respectively. Project page: https://cybertronagent.github.io/Mirage-1.github.io/
PCDVQ: Enhancing Vector Quantization for Large Language Models via Polar Coordinate Decoupling
Jun 05, 2025Large Language Models (LLMs) face significant challenges in edge deployment due to their massive parameter scale. Vector Quantization (VQ), a clustering-based quantization method, serves as a prevalent solution to this issue for its extremely low-bit (even at 2-bit) and considerable accuracy. Since a vector is a quantity in mathematics and physics that has both direction and magnitude, existing VQ works typically quantize them in a coupled manner. However, we find that direction exhibits significantly greater sensitivity to quantization compared to the magnitude. For instance, when separately clustering the directions and magnitudes of weight vectors in LLaMA-2-7B, the accuracy drop of zero-shot tasks are 46.5\% and 2.3\%, respectively. This gap even increases with the reduction of clustering centers. Further, Euclidean distance, a common metric to access vector similarities in current VQ works, places greater emphasis on reducing the magnitude error. This property is contrary to the above finding, unavoidably leading to larger quantization errors. To these ends, this paper proposes Polar Coordinate Decoupled Vector Quantization (PCDVQ), an effective and efficient VQ framework consisting of two key modules: 1) Polar Coordinate Decoupling (PCD), which transforms vectors into their polar coordinate representations and perform independent quantization of the direction and magnitude parameters.2) Distribution Aligned Codebook Construction (DACC), which optimizes the direction and magnitude codebooks in accordance with the source distribution. Experimental results show that PCDVQ outperforms baseline methods at 2-bit level by at least 1.5\% zero-shot accuracy, establishing a novel paradigm for accurate and highly compressed LLMs.
STAR: Learning Diverse Robot Skill Abstractions through Rotation-Augmented Vector Quantization
Jun 04, 2025
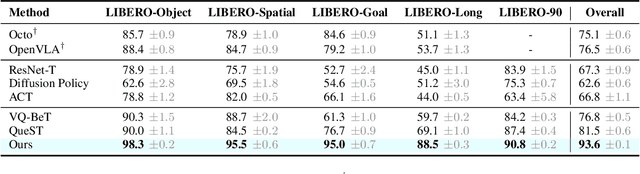
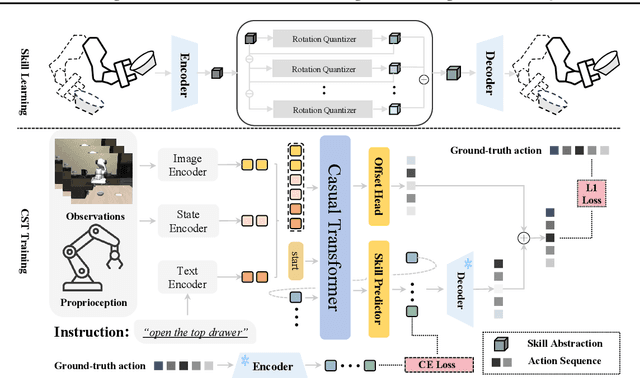

Transforming complex actions into discrete skill abstractions has demonstrated strong potential for robotic manipulation. Existing approaches mainly leverage latent variable models, e.g., VQ-VAE, to learn skill abstractions through learned vectors (codebooks), while they suffer from codebook collapse and modeling the causal relationship between learned skills. To address these limitations, we present \textbf{S}kill \textbf{T}raining with \textbf{A}ugmented \textbf{R}otation (\textbf{STAR}), a framework that advances both skill learning and composition to complete complex behaviors. Specifically, to prevent codebook collapse, we devise rotation-augmented residual skill quantization (RaRSQ). It encodes relative angles between encoder outputs into the gradient flow by rotation-based gradient mechanism. Points within the same skill code are forced to be either pushed apart or pulled closer together depending on gradient directions. Further, to capture the causal relationship between skills, we present causal skill transformer (CST) which explicitly models dependencies between skill representations through an autoregressive mechanism for coherent action generation. Extensive experiments demonstrate the superiority of STAR on both LIBERO benchmark and realworld tasks, with around 12\% improvement over the baselines.
* Accepted by ICML 2025 Spotlight
Train with Perturbation, Infer after Merging: A Two-Stage Framework for Continual Learning
May 29, 2025Continual Learning (CL) aims to enable models to continuously acquire new knowledge from a sequence of tasks with avoiding the forgetting of learned information. However, existing CL methods only rely on the parameters of the most recent task for inference, which makes them susceptible to catastrophic forgetting. Inspired by the recent success of model merging techniques, we propose \textbf{Perturb-and-Merge (P\&M)}, a novel continual learning framework that integrates model merging into the CL paradigm to mitigate forgetting. Specifically, after training on each task, P\&M constructs a new model by forming a convex combination of the previous model and the newly trained task-specific model. Through theoretical analysis, we minimize the total loss increase across all tasks and derive an analytical solution for the optimal merging coefficient. To further improve the performance of the merged model, we observe that the degradation introduced during merging can be alleviated by a regularization term composed of the task vector and the Hessian matrix of the loss function. Interestingly, we show that this term can be efficiently approximated using second-order symmetric finite differences, and a stochastic perturbation strategy along the task vector direction is accordingly devised which incurs no additional forward or backward passes while providing an effective approximation of the regularization term. Finally, we combine P\&M with LoRA, a parameter-efficient fine-tuning method, to reduce memory overhead. Our proposed approach achieves state-of-the-art performance on several continual learning benchmark datasets.
SplitLoRA: Balancing Stability and Plasticity in Continual Learning Through Gradient Space Splitting
May 29, 2025Continual Learning requires a model to learn multiple tasks in sequence while maintaining both stability:preserving knowledge from previously learned tasks, and plasticity:effectively learning new tasks. Gradient projection has emerged as an effective and popular paradigm in CL, where it partitions the gradient space of previously learned tasks into two orthogonal subspaces: a primary subspace and a minor subspace. New tasks are learned effectively within the minor subspace, thereby reducing interference with previously acquired knowledge. However, existing Gradient Projection methods struggle to achieve an optimal balance between plasticity and stability, as it is hard to appropriately partition the gradient space. In this work, we consider a continual learning paradigm based on Low-Rank Adaptation, which has gained considerable attention due to its efficiency and wide applicability, and propose a novel approach for continual learning, called SplitLoRA. We first provide a theoretical analysis of how subspace partitioning affects model stability and plasticity. Informed by this analysis, we then introduce an effective method that derives the optimal partition of the gradient space for previously learned tasks. This approach effectively balances stability and plasticity in continual learning. Experimental results on multiple datasets demonstrate that the proposed method achieves state-of-the-art performance.
HCQA-1.5 @ Ego4D EgoSchema Challenge 2025
May 27, 2025In this report, we present the method that achieves third place for Ego4D EgoSchema Challenge in CVPR 2025. To improve the reliability of answer prediction in egocentric video question answering, we propose an effective extension to the previously proposed HCQA framework. Our approach introduces a multi-source aggregation strategy to generate diverse predictions, followed by a confidence-based filtering mechanism that selects high-confidence answers directly. For low-confidence cases, we incorporate a fine-grained reasoning module that performs additional visual and contextual analysis to refine the predictions. Evaluated on the EgoSchema blind test set, our method achieves 77% accuracy on over 5,000 human-curated multiple-choice questions, outperforming last year's winning solution and the majority of participating teams. Our code will be added at https://github.com/Hyu-Zhang/HCQA.