 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTTOM: Test-Time Optimization and Memorization for Compositional Video Generation
Oct 09, 2025Video Foundation Models (VFMs) exhibit remarkable visual generation performance, but struggle in compositional scenarios (e.g., motion, numeracy, and spatial relation). In this work, we introduce Test-Time Optimization and Memorization (TTOM), a training-free framework that aligns VFM outputs with spatiotemporal layouts during inference for better text-image alignment. Rather than direct intervention to latents or attention per-sample in existing work, we integrate and optimize new parameters guided by a general layout-attention objective. Furthermore, we formulate video generation within a streaming setting, and maintain historical optimization contexts with a parametric memory mechanism that supports flexible operations, such as insert, read, update, and delete. Notably, we found that TTOM disentangles compositional world knowledge, showing powerful transferability and generalization. Experimental results on the T2V-CompBench and Vbench benchmarks establish TTOM as an effective, practical, scalable, and efficient framework to achieve cross-modal alignment for compositional video generation on the fly.
Mitigating Hallucination Through Theory-Consistent Symmetric Multimodal Preference Optimization
Jun 13, 2025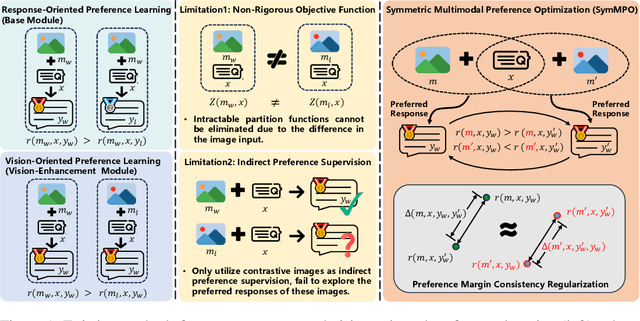

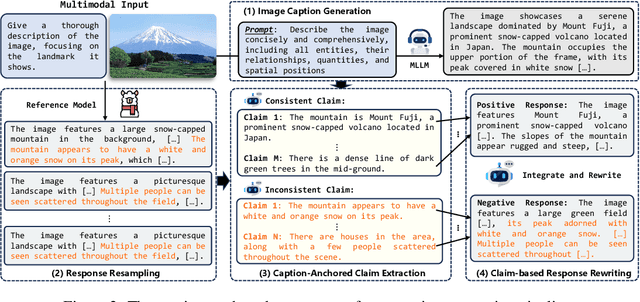

Direct Preference Optimization (DPO) has emerged as an effective approach for mitigating hallucination in Multimodal Large Language Models (MLLMs). Although existing methods have achieved significant progress by utilizing vision-oriented contrastive objectives for enhancing MLLMs' attention to visual inputs and hence reducing hallucination, they suffer from non-rigorous optimization objective function and indirect preference supervision. To address these limitations, we propose a Symmetric Multimodal Preference Optimization (SymMPO), which conducts symmetric preference learning with direct preference supervision (i.e., response pairs) for visual understanding enhancement, while maintaining rigorous theoretical alignment with standard DPO. In addition to conventional ordinal preference learning, SymMPO introduces a preference margin consistency loss to quantitatively regulate the preference gap between symmetric preference pairs. Comprehensive evaluation across five benchmarks demonstrate SymMPO's superior performance, validating its effectiveness in hallucination mitigation of MLLMs.
Modality Reliability Guided Multimodal Recommendation
Apr 23, 2025



Multimodal recommendation faces an issue of the performance degradation that the uni-modal recommendation sometimes achieves the better performance. A possible reason is that the unreliable item modality data hurts the fusion result. Several existing studies have introduced weights for different modalities to reduce the contribution of the unreliable modality data in predicting the final user rating. However, they fail to provide appropriate supervisions for learning the modality weights, making the learned weights imprecise. Therefore, we propose a modality reliability guided multimodal recommendation framework that uniquely learns the modality weights supervised by the modality reliability. Considering that there is no explicit label provided for modality reliability, we resort to automatically identify it through the BPR recommendation objective. In particular, we define a modality reliability vector as the supervision label by the difference between modality-specific user ratings to positive and negative items, where a larger difference indicates a higher reliability of the modality as the BPR objective is better satisfied. Furthermore, to enhance the effectiveness of the supervision, we calculate the confidence level for the modality reliability vector, which dynamically adjusts the supervision strength and eliminates the harmful supervision. Extensive experiments on three real-world datasets show the effectiveness of the proposed method.
VK-G2T: Vision and Context Knowledge enhanced Gloss2Text
Dec 15, 2023Existing sign language translation methods follow a two-stage pipeline: first converting the sign language video to a gloss sequence (i.e. Sign2Gloss) and then translating the generated gloss sequence into a spoken language sentence (i.e. Gloss2Text). While previous studies have focused on boosting the performance of the Sign2Gloss stage, we emphasize the optimization of the Gloss2Text stage. However, this task is non-trivial due to two distinct features of Gloss2Text: (1) isolated gloss input and (2) low-capacity gloss vocabulary. To address these issues, we propose a vision and context knowledge enhanced Gloss2Text model, named VK-G2T, which leverages the visual content of the sign language video to learn the properties of the target sentence and exploit the context knowledge to facilitate the adaptive translation of gloss words. Extensive experiments conducted on a Chinese benchmark validate the superiority of our model.
Dual Preference Distribution Learning for Item Recommendation
Jan 24, 2022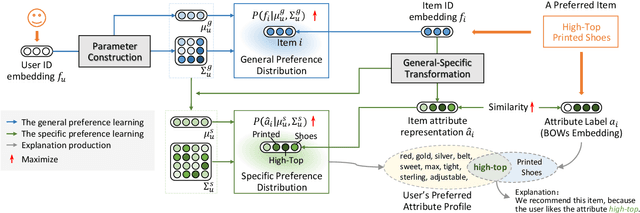
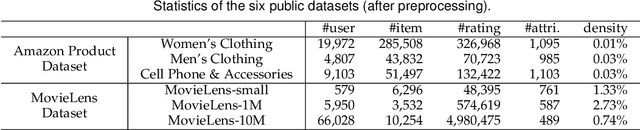
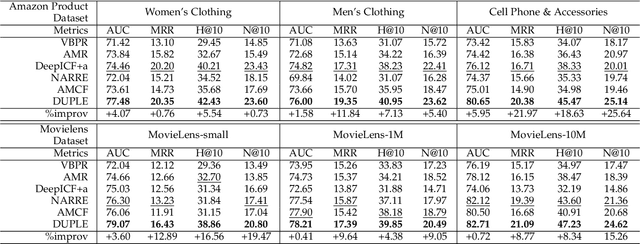
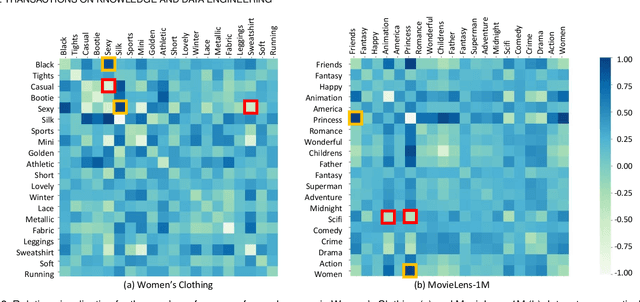
Recommender systems can automatically recommend users items that they probably like, for which the goal is to represent the user and item as well as model their interaction. Existing methods have primarily learned the user's preferences and item's features with vectorized representations, and modeled the user-item interaction by the similarity of their representations. In fact, the user's different preferences are related and capturing such relations could better understand the user's preferences for a better recommendation. Toward this end, we propose to represent the user's preference with multi-variant Gaussian distribution, and model the user-item interaction by calculating the probability density at the item in the user's preference distribution. In this manner, the mean vector of the Gaussian distribution is able to capture the center of the user's preferences, while its covariance matrix captures the relations of these preferences. In particular, in this work, we propose a dual preference distribution learning framework (DUPLE), which captures the user's preferences to both the items and attributes by a Gaussian distribution, respectively. As a byproduct, identifying the user's preference to specific attributes enables us to provide the explanation of recommending an item to the user. Extensive quantitative and qualitative experiments on six public datasets show that DUPLE achieves the best performance over all state-of-the-art recommendation methods.