 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePCDVQ: Enhancing Vector Quantization for Large Language Models via Polar Coordinate Decoupling
Jun 05, 2025Large Language Models (LLMs) face significant challenges in edge deployment due to their massive parameter scale. Vector Quantization (VQ), a clustering-based quantization method, serves as a prevalent solution to this issue for its extremely low-bit (even at 2-bit) and considerable accuracy. Since a vector is a quantity in mathematics and physics that has both direction and magnitude, existing VQ works typically quantize them in a coupled manner. However, we find that direction exhibits significantly greater sensitivity to quantization compared to the magnitude. For instance, when separately clustering the directions and magnitudes of weight vectors in LLaMA-2-7B, the accuracy drop of zero-shot tasks are 46.5\% and 2.3\%, respectively. This gap even increases with the reduction of clustering centers. Further, Euclidean distance, a common metric to access vector similarities in current VQ works, places greater emphasis on reducing the magnitude error. This property is contrary to the above finding, unavoidably leading to larger quantization errors. To these ends, this paper proposes Polar Coordinate Decoupled Vector Quantization (PCDVQ), an effective and efficient VQ framework consisting of two key modules: 1) Polar Coordinate Decoupling (PCD), which transforms vectors into their polar coordinate representations and perform independent quantization of the direction and magnitude parameters.2) Distribution Aligned Codebook Construction (DACC), which optimizes the direction and magnitude codebooks in accordance with the source distribution. Experimental results show that PCDVQ outperforms baseline methods at 2-bit level by at least 1.5\% zero-shot accuracy, establishing a novel paradigm for accurate and highly compressed LLMs.
RWKVQuant: Quantizing the RWKV Family with Proxy Guided Hybrid of Scalar and Vector Quantization
May 02, 2025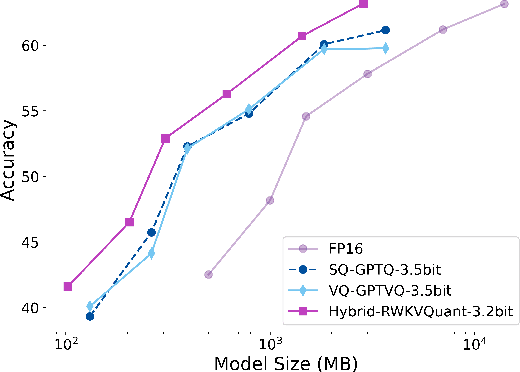
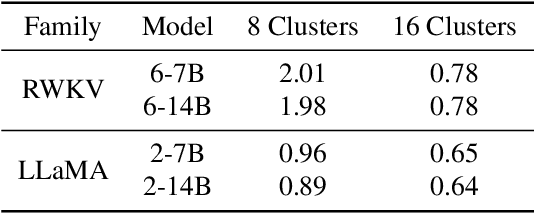
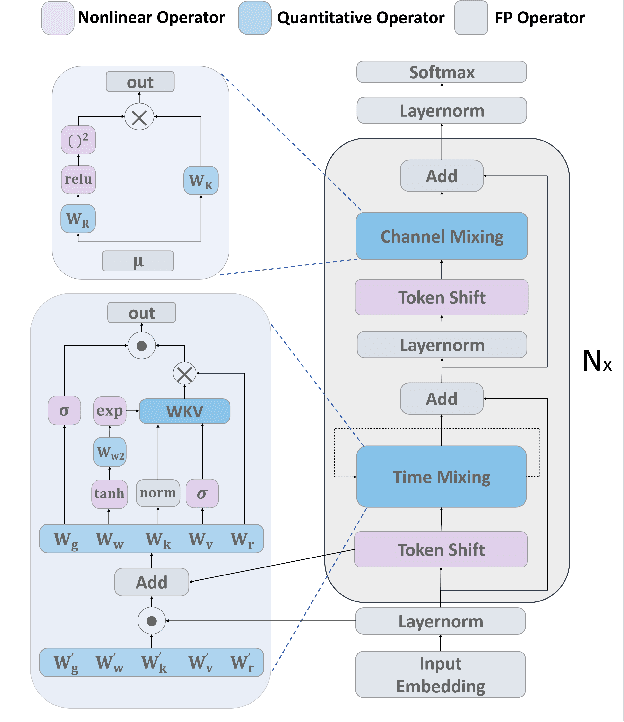
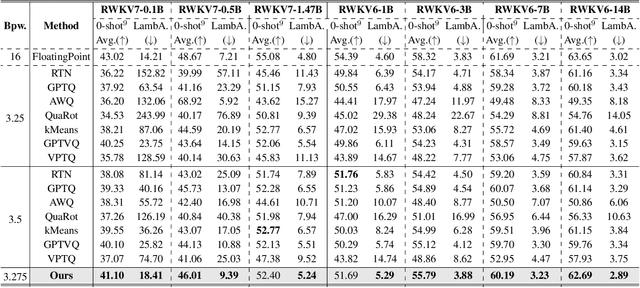
RWKV is a modern RNN architecture with comparable performance to Transformer, but still faces challenges when deployed to resource-constrained devices. Post Training Quantization (PTQ), which is a an essential technique to reduce model size and inference latency, has been widely used in Transformer models. However, it suffers significant degradation of performance when applied to RWKV. This paper investigates and identifies two key constraints inherent in the properties of RWKV: (1) Non-linear operators hinder the parameter-fusion of both smooth- and rotation-based quantization, introducing extra computation overhead. (2) The larger amount of uniformly distributed weights poses challenges for cluster-based quantization, leading to reduced accuracy. To this end, we propose RWKVQuant, a PTQ framework tailored for RWKV models, consisting of two novel techniques: (1) a coarse-to-fine proxy capable of adaptively selecting different quantization approaches by assessing the uniformity and identifying outliers in the weights, and (2) a codebook optimization algorithm that enhances the performance of cluster-based quantization methods for element-wise multiplication in RWKV. Experiments show that RWKVQuant can quantize RWKV-6-14B into about 3-bit with less than 1% accuracy loss and 2.14x speed up.
WKVQuant: Quantizing Weight and Key/Value Cache for Large Language Models Gains More
Feb 20, 2024Large Language Models (LLMs) face significant deployment challenges due to their substantial memory requirements and the computational demands of auto-regressive text generation process. This paper addresses these challenges by focusing on the quantization of LLMs, a technique that reduces memory consumption by converting model parameters and activations into low-bit integers. We critically analyze the existing quantization approaches, identifying their limitations in balancing the accuracy and efficiency of the quantized LLMs. To advance beyond these limitations, we propose WKVQuant, a PTQ framework especially designed for quantizing weights and the key/value (KV) cache of LLMs. Specifically, we incorporates past-only quantization to improve the computation of attention. Additionally, we introduce two-dimensional quantization strategy to handle the distribution of KV cache, along with a cross-block reconstruction regularization for parameter optimization. Experiments show that WKVQuant achieves almost comparable memory savings to weight-activation quantization, while also approaching the performance of weight-only quantization.