 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTWLA: Achieving Ternary Weights and Low-Bit Activations for LLMs via Post-Training Quantization
Jun 11, 2026Large language models (LLMs) exhibit exceptional general language processing capabilities, but their memory and compute costs hinder deployment. Ternarization has emerged as a promising compression technique, offering significant reductions in model size and inference complexity. However, existing methods struggle with heavy-tailed activation distributions and therefore keep activations in high precision, fundamentally limiting end-to-end inference acceleration. To overcome this limitation, we propose TWLA, a post-training quantization (PTQ) framework that achieves 1.58-bit weight compression and 4-bit activation quantization while maintaining high accuracy. TWLA comprises three components: (1) Euclidean-to-Manifold Asymmetric Ternary Quantizer (E2M-ATQ) minimizes layer-output error under weight ternarization via a two-stage optimization from Euclidean initialization to manifold relocation; (2) Kronecker Orthogonal Tri-Modal Shaping (KOTMS) applies a Kronecker-structured orthogonal rotation to reshape weights into ternary-friendly tri-modal distributions, while the shared rotation statistically suppresses activation outliers; and (3) Inter-Layer Aware Activation Mixed Precision (ILA-AMP) explicitly introduces adjacent-layer second-order interaction costs in bit allocation and jointly optimizes for the layer-wise disparity of activation quantization gains induced by the shared orthogonal transform, preventing cascades triggered by a few weak layers. Extensive experiments demonstrate that TWLA maintains high accuracy under W1.58A4, while delivering significant inference acceleration. The code is available at <https://github.com/Kishon-zzx/TWLA>.
TORQ: Two-Level Orthogonal Rotation for MXFP4 Quantization
May 19, 2026As Large Language Models (LLMs) advance toward practical deployment, the Microscaling FP4 (MXFP4) format has emerged as a cornerstone for next-generation low-bit inference, owing to its ability to balance high dynamic range with hardware efficiency. However, directly applying MXFP4 to LLM activation quantization inevitably leads to significant accuracy degradation. In this paper, we theoretically analyze the error structure of MXFP4 activation quantization, revealing that the root cause of this performance drop lies in two structural imbalances between activation distributions and the MXFP4 block floating-point format: (1) extreme inter-block variance imbalance and (2) intra-block codebook utilization imbalance. To address these challenges, we propose TORQ (Two-level Orthogonal Rotation for MXFP4 Quantization), a training-free Post-Training Quantization (PTQ) framework designed to reshape the geometric properties of the activation space through optimal coordinate transformations. At the macroscopic level, TORQ leverages the Schur-Horn theorem to redistribute activation energy via inter-block orthogonal rotation, preventing high-variance blocks from driving up shared scaling factors and thereby preserving the precision of small-magnitude elements. At the microscopic level, TORQ employs maximum-entropy-guided intra-block rotation to alleviate codebook collapse and maximize the MXFP4 codebook's information capacity. Experiments on mainstream LLMs such as LLaMA3 and Qwen3 show that TORQ significantly improves the accuracy of MXFP4 activation quantization compared to existing methods: on Qwen3-32B, the perplexity on WikiText is reduced to 8.43 (vs. 7.61 for BF16), and the average accuracy increases from 38.40% with direct RTN to 73.63% (vs. 74.82% for BF16), substantially narrowing the gap between 4-bit floating-point quantization and full-precision inference.
MoBiE: Efficient Inference of Mixture of Binary Experts under Post-Training Quantization
Apr 08, 2026Mixture-of-Experts (MoE) based large language models (LLMs) offer strong performance but suffer from high memory and computation costs. Weight binarization provides extreme efficiency, yet existing binary methods designed for dense LLMs struggle with MoE-specific issues, including cross-expert redundancy, task-agnostic importance estimation, and quantization-induced routing shifts. To this end, we propose MoBiE, the first binarization framework tailored for MoE-based LLMs. MoBiE is built on three core innovations: 1. using joint SVD decomposition to reduce cross-expert redundancy; 2. integrating global loss gradients into local Hessian metrics to enhance weight importance estimation; 3. introducing an error constraint guided by the input null space to mitigate routing distortion. Notably, MoBiE achieves these optimizations while incurring no additional storage overhead, striking a balance between efficiency and model performance. Extensive experiments demonstrate that MoBiE consistently outperforms state-of-the-art binary methods across multiple MoE-based LLMs and benchmarks. For example, on Qwen3-30B-A3B, MoBiE reduces perplexity by 52.2$\%$, improves average zero-shot performance by 43.4$\%$, achieves over 2 $\times$ inference speedup, and further shortens quantization time. The code is available at https://github.com/Kishon-zzx/MoBiE.
SAES-SVD: Self-Adaptive Suppression of Accumulated and Local Errors for SVD-based LLM Compression
Feb 03, 2026The rapid growth in the parameter scale of large language models (LLMs) has created a high demand for efficient compression techniques. As a hardware-agnostic and highly compatible technique, low-rank compression has been widely adopted. However, existing methods typically compress each layer independently by minimizing per-layer reconstruction error, overlooking a critical limitation: the reconstruction error propagates and accumulates through the network, which leads to amplified global deviations from the full-precision baseline. To address this, we propose Self-Adaptive Error Suppression SVD (SAES-SVD), a LLMs compression framework that jointly optimizes intra-layer reconstruction and inter-layer error compensation. SAES-SVD is composed of two novel components: (1) Cumulative Error-Aware Layer Compression (CEALC), which formulates the compression objective as a combination of local reconstruction and weighted cumulative error compensation. Based on it, we derive a closed-form low-rank solution relied on second-order activation statistics, which explicitly aligns each layer's output with its full-precision counterpart to compensate for accumulated errors. (2) Adaptive Collaborative Error Suppression (ACES), which automatically adjusts the weighting coefficient to enhance the low-rank structure of the compression objective in CEALC. Specifically, the coefficient is optimized to maximize the ratio between the Frobenius norm of the compressed layer's output and that of the compression objective under a fixed rank, thus ensuring that the rank budget is utilized effectively. Extensive experiments across multiple LLM architectures and tasks show that, without fine-tuning or mixed-rank strategies, SAES-SVD consistently improves post-compression performance.
PCDVQ: Enhancing Vector Quantization for Large Language Models via Polar Coordinate Decoupling
Jun 05, 2025Large Language Models (LLMs) face significant challenges in edge deployment due to their massive parameter scale. Vector Quantization (VQ), a clustering-based quantization method, serves as a prevalent solution to this issue for its extremely low-bit (even at 2-bit) and considerable accuracy. Since a vector is a quantity in mathematics and physics that has both direction and magnitude, existing VQ works typically quantize them in a coupled manner. However, we find that direction exhibits significantly greater sensitivity to quantization compared to the magnitude. For instance, when separately clustering the directions and magnitudes of weight vectors in LLaMA-2-7B, the accuracy drop of zero-shot tasks are 46.5\% and 2.3\%, respectively. This gap even increases with the reduction of clustering centers. Further, Euclidean distance, a common metric to access vector similarities in current VQ works, places greater emphasis on reducing the magnitude error. This property is contrary to the above finding, unavoidably leading to larger quantization errors. To these ends, this paper proposes Polar Coordinate Decoupled Vector Quantization (PCDVQ), an effective and efficient VQ framework consisting of two key modules: 1) Polar Coordinate Decoupling (PCD), which transforms vectors into their polar coordinate representations and perform independent quantization of the direction and magnitude parameters.2) Distribution Aligned Codebook Construction (DACC), which optimizes the direction and magnitude codebooks in accordance with the source distribution. Experimental results show that PCDVQ outperforms baseline methods at 2-bit level by at least 1.5\% zero-shot accuracy, establishing a novel paradigm for accurate and highly compressed LLMs.
MoEQuant: Enhancing Quantization for Mixture-of-Experts Large Language Models via Expert-Balanced Sampling and Affinity Guidance
May 02, 2025



Mixture-of-Experts (MoE) large language models (LLMs), which leverage dynamic routing and sparse activation to enhance efficiency and scalability, have achieved higher performance while reducing computational costs. However, these models face significant memory overheads, limiting their practical deployment and broader adoption. Post-training quantization (PTQ), a widely used method for compressing LLMs, encounters severe accuracy degradation and diminished generalization performance when applied to MoE models. This paper investigates the impact of MoE's sparse and dynamic characteristics on quantization and identifies two primary challenges: (1) Inter-expert imbalance, referring to the uneven distribution of samples across experts, which leads to insufficient and biased calibration for less frequently utilized experts; (2) Intra-expert imbalance, arising from MoE's unique aggregation mechanism, which leads to varying degrees of correlation between different samples and their assigned experts. To address these challenges, we propose MoEQuant, a novel quantization framework tailored for MoE LLMs. MoE-Quant includes two novel techniques: 1) Expert-Balanced Self-Sampling (EBSS) is an efficient sampling method that efficiently constructs a calibration set with balanced expert distributions by leveraging the cumulative probabilities of tokens and expert balance metrics as guiding factors. 2) Affinity-Guided Quantization (AGQ), which incorporates affinities between experts and samples into the quantization process, thereby accurately assessing the impact of individual samples on different experts within the MoE layer. Experiments demonstrate that MoEQuant achieves substantial performance gains (more than 10 points accuracy gain in the HumanEval for DeepSeekMoE-16B under 4-bit quantization) and boosts efficiency.
RWKVQuant: Quantizing the RWKV Family with Proxy Guided Hybrid of Scalar and Vector Quantization
May 02, 2025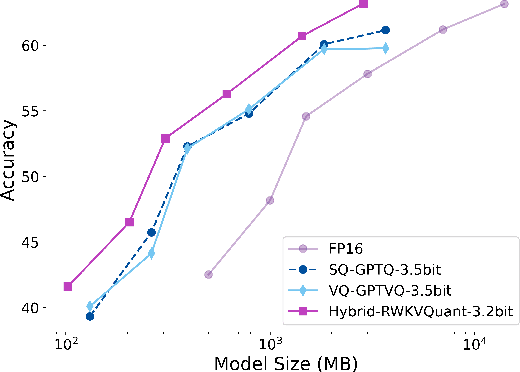
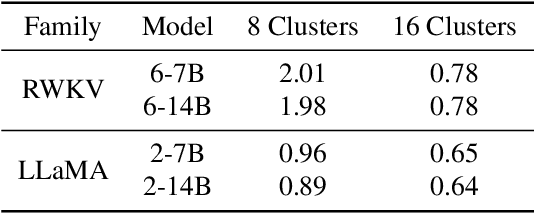
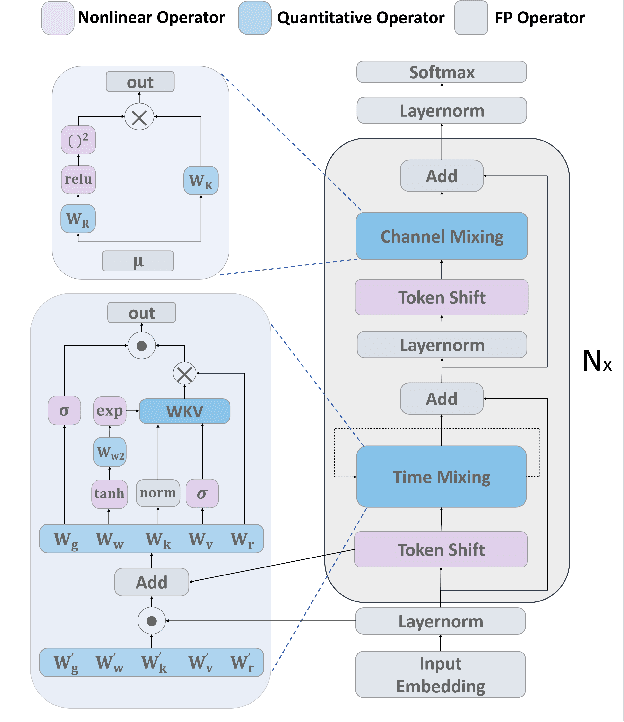
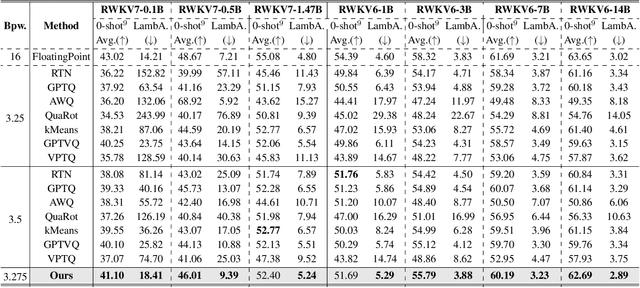
RWKV is a modern RNN architecture with comparable performance to Transformer, but still faces challenges when deployed to resource-constrained devices. Post Training Quantization (PTQ), which is a an essential technique to reduce model size and inference latency, has been widely used in Transformer models. However, it suffers significant degradation of performance when applied to RWKV. This paper investigates and identifies two key constraints inherent in the properties of RWKV: (1) Non-linear operators hinder the parameter-fusion of both smooth- and rotation-based quantization, introducing extra computation overhead. (2) The larger amount of uniformly distributed weights poses challenges for cluster-based quantization, leading to reduced accuracy. To this end, we propose RWKVQuant, a PTQ framework tailored for RWKV models, consisting of two novel techniques: (1) a coarse-to-fine proxy capable of adaptively selecting different quantization approaches by assessing the uniformity and identifying outliers in the weights, and (2) a codebook optimization algorithm that enhances the performance of cluster-based quantization methods for element-wise multiplication in RWKV. Experiments show that RWKVQuant can quantize RWKV-6-14B into about 3-bit with less than 1% accuracy loss and 2.14x speed up.