 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContext-Agent: Dynamic Discourse Trees for Non-Linear Dialogue
Apr 07, 2026Large Language Models demonstrate outstanding performance in many language tasks but still face fundamental challenges in managing the non-linear flow of human conversation. The prevalent approach of treating dialogue history as a flat, linear sequence is misaligned with the intrinsically hierarchical and branching structure of natural discourse, leading to inefficient context utilization and a loss of coherence during extended interactions involving topic shifts or instruction refinements. To address this limitation, we introduce Context-Agent, a novel framework that models multi-turn dialogue history as a dynamic tree structure. This approach mirrors the inherent non-linearity of conversation, enabling the model to maintain and navigate multiple dialogue branches corresponding to different topics. Furthermore, to facilitate robust evaluation, we introduce the Non-linear Task Multi-turn Dialogue (NTM) benchmark, specifically designed to assess model performance in long-horizon, non-linear scenarios. Our experiments demonstrate that Context-Agent enhances task completion rates and improves token efficiency across various LLMs, underscoring the value of structured context management for complex, dynamic dialogues. The dataset and code is available at GitHub.
VideoTemp-o3: Harmonizing Temporal Grounding and Video Understanding in Agentic Thinking-with-Videos
Feb 08, 2026In long-video understanding, conventional uniform frame sampling often fails to capture key visual evidence, leading to degraded performance and increased hallucinations. To address this, recent agentic thinking-with-videos paradigms have emerged, adopting a localize-clip-answer pipeline in which the model actively identifies relevant video segments, performs dense sampling within those clips, and then produces answers. However, existing methods remain inefficient, suffer from weak localization, and adhere to rigid workflows. To solve these issues, we propose VideoTemp-o3, a unified agentic thinking-with-videos framework that jointly models video grounding and question answering. VideoTemp-o3 exhibits strong localization capability, supports on-demand clipping, and can refine inaccurate localizations. Specifically, in the supervised fine-tuning stage, we design a unified masking mechanism that encourages exploration while preventing noise. For reinforcement learning, we introduce dedicated rewards to mitigate reward hacking. Besides, from the data perspective, we develop an effective pipeline to construct high-quality long video grounded QA data, along with a corresponding benchmark for systematic evaluation across various video durations. Experimental results demonstrate that our method achieves remarkable performance on both long video understanding and grounding.
Mitigating Hallucination Through Theory-Consistent Symmetric Multimodal Preference Optimization
Jun 13, 2025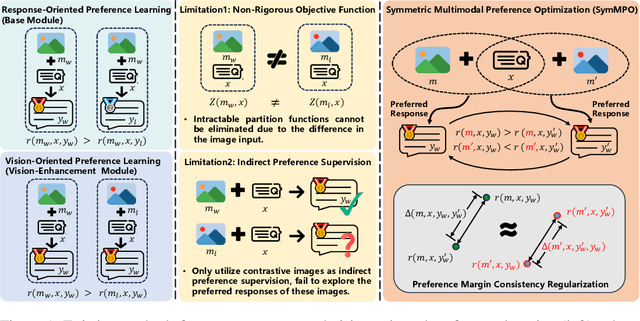

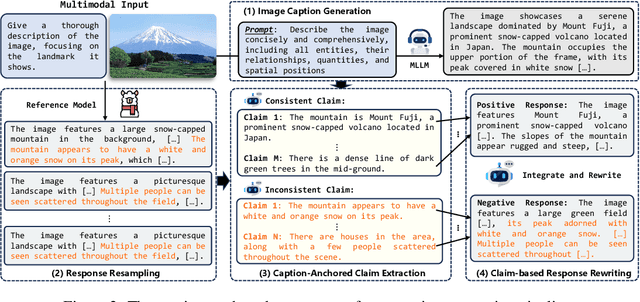

Direct Preference Optimization (DPO) has emerged as an effective approach for mitigating hallucination in Multimodal Large Language Models (MLLMs). Although existing methods have achieved significant progress by utilizing vision-oriented contrastive objectives for enhancing MLLMs' attention to visual inputs and hence reducing hallucination, they suffer from non-rigorous optimization objective function and indirect preference supervision. To address these limitations, we propose a Symmetric Multimodal Preference Optimization (SymMPO), which conducts symmetric preference learning with direct preference supervision (i.e., response pairs) for visual understanding enhancement, while maintaining rigorous theoretical alignment with standard DPO. In addition to conventional ordinal preference learning, SymMPO introduces a preference margin consistency loss to quantitatively regulate the preference gap between symmetric preference pairs. Comprehensive evaluation across five benchmarks demonstrate SymMPO's superior performance, validating its effectiveness in hallucination mitigation of MLLMs.
SparseNet: A Sparse DenseNet for Image Classification
Apr 15, 2018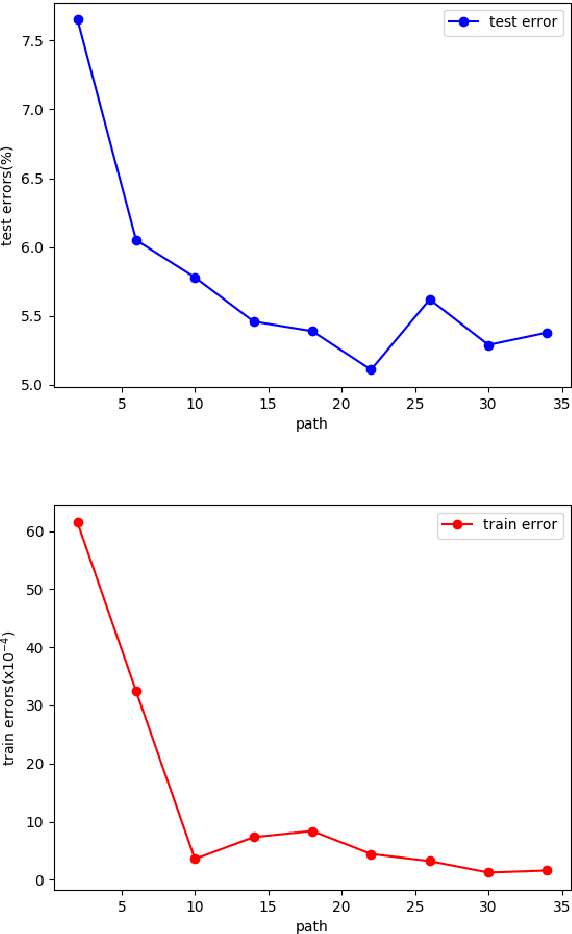
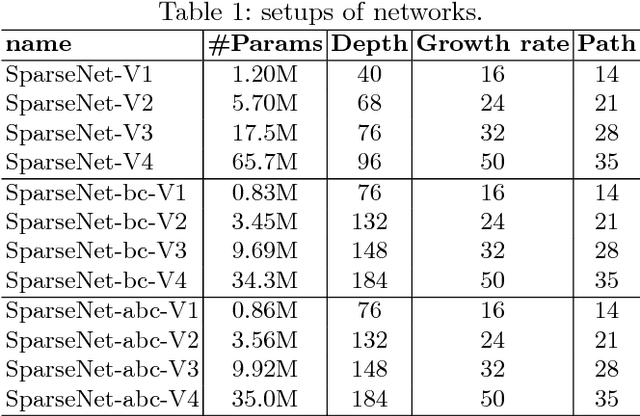
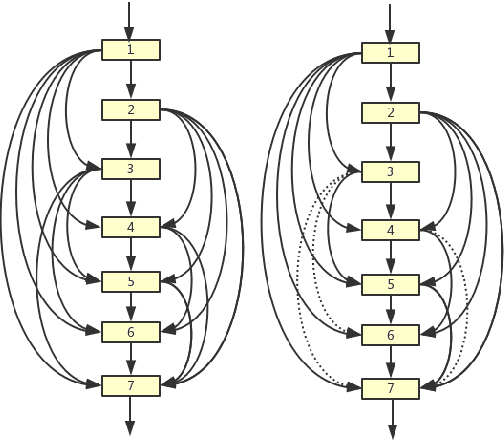
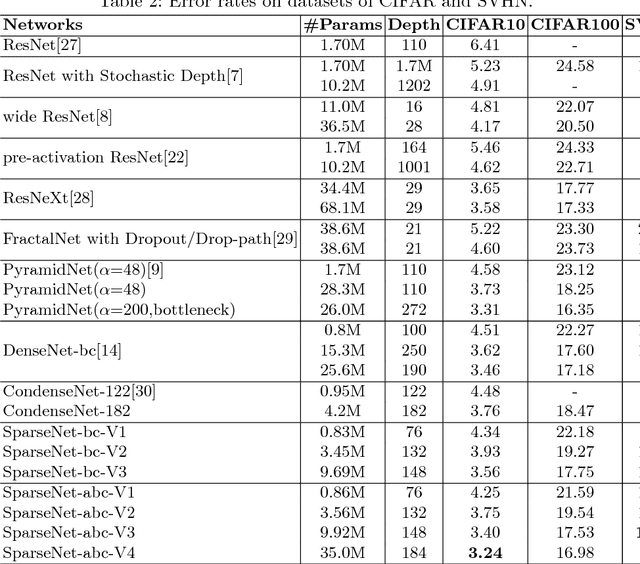
Deep neural networks have made remarkable progresses on various computer vision tasks. Recent works have shown that depth, width and shortcut connections of networks are all vital to their performances. In this paper, we introduce a method to sparsify DenseNet which can reduce connections of a L-layer DenseNet from O(L^2) to O(L), and thus we can simultaneously increase depth, width and connections of neural networks in a more parameter-efficient and computation-efficient way. Moreover, an attention module is introduced to further boost our network's performance. We denote our network as SparseNet. We evaluate SparseNet on datasets of CIFAR(including CIFAR10 and CIFAR100) and SVHN. Experiments show that SparseNet can obtain improvements over the state-of-the-art on CIFAR10 and SVHN. Furthermore, while achieving comparable performances as DenseNet on these datasets, SparseNet is x2.6 smaller and x3.7 faster than the original DenseNet.