 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNear-Field Multi-User Communications via Polar-Domain Beamfocusing: Analytical Framework and Performance Analysis
Dec 19, 2025As wireless systems evolve toward higher frequencies and extremely large antenna arrays, near-field (NF) propagation becomes increasingly dominant. Unlike far-field (FF) communication, which relies on a planar-wavefront model and is limited to angular-domain beamsteering, NF propagation exhibits spherical wavefronts that enable beamfocusing in both angle and distance, i.e., the polar domain, offering new opportunities for spatial multiple access. This paper develops an analytical stochastic geometry (SG) framework for a multi-user system assisted by polar-domain beamfocusing, which jointly captures NF propagation characteristics and the spatial randomness of user locations. The intrinsic coupling between angle and distance in the NF antenna pattern renders inter-user interference analysis intractable. To address this challenge, we propose a tractable near-field multi-level antenna pattern (NF-MLAP) approximation, which enables computationally efficient expressions and tight upper bounds for key performance metrics, including coverage probability, spectrum efficiency, and area spectrum efficiency. Analytical and simulation results demonstrate that the proposed framework accurately captures performance trends and reveals fundamental trade-offs between hardware configuration (including the number of antennas and radio frequency chains) and system performance (in terms of spatial resource reuse and interference mitigation).
ECCENTRIC: Edge-Cloud Collaboration Framework for Distributed Inference Using Knowledge Adaptation
Nov 12, 2025The massive growth in the utilization of edge AI has made the applications of machine learning models ubiquitous in different domains. Despite the computation and communication efficiency of these systems, due to limited computation resources on edge devices, relying on more computationally rich systems on the cloud side is inevitable in most cases. Cloud inference systems can achieve the best performance while the computation and communication cost is dramatically increasing by the expansion of a number of edge devices relying on these systems. Hence, there is a trade-off between the computation, communication, and performance of these systems. In this paper, we propose a novel framework, dubbed as Eccentric that learns models with different levels of trade-offs between these conflicting objectives. This framework, based on an adaptation of knowledge from the edge model to the cloud one, reduces the computation and communication costs of the system during inference while achieving the best performance possible. The Eccentric framework can be considered as a new form of compression method suited for edge-cloud inference systems to reduce both computation and communication costs. Empirical studies on classification and object detection tasks corroborate the efficacy of this framework.
Graph2Eval: Automatic Multimodal Task Generation for Agents via Knowledge Graphs
Oct 01, 2025



As multimodal LLM-driven agents continue to advance in autonomy and generalization, evaluation based on static datasets can no longer adequately assess their true capabilities in dynamic environments and diverse tasks. Existing LLM-based synthetic data methods are largely designed for LLM training and evaluation, and thus cannot be directly applied to agent tasks that require tool use and interactive capabilities. While recent studies have explored automatic agent task generation with LLMs, most efforts remain limited to text or image analysis, without systematically modeling multi-step interactions in web environments. To address these challenges, we propose Graph2Eval, a knowledge graph-based framework that automatically generates both multimodal document comprehension tasks and web interaction tasks, enabling comprehensive evaluation of agents' reasoning, collaboration, and interactive capabilities. In our approach, knowledge graphs constructed from multi-source external data serve as the task space, where we translate semantic relations into structured multimodal tasks using subgraph sampling, task templates, and meta-paths. A multi-stage filtering pipeline based on node reachability, LLM scoring, and similarity analysis is applied to guarantee the quality and executability of the generated tasks. Furthermore, Graph2Eval supports end-to-end evaluation of multiple agent types (Single-Agent, Multi-Agent, Web Agent) and measures reasoning, collaboration, and interaction capabilities. We instantiate the framework with Graph2Eval-Bench, a curated dataset of 1,319 tasks spanning document comprehension and web interaction scenarios. Experiments show that Graph2Eval efficiently generates tasks that differentiate agent and model performance, revealing gaps in reasoning, collaboration, and web interaction across different settings and offering a new perspective for agent evaluation.
FlowRL: Matching Reward Distributions for LLM Reasoning
Sep 18, 2025We propose FlowRL: matching the full reward distribution via flow balancing instead of maximizing rewards in large language model (LLM) reinforcement learning (RL). Recent advanced reasoning models adopt reward-maximizing methods (\eg, PPO and GRPO), which tend to over-optimize dominant reward signals while neglecting less frequent but valid reasoning paths, thus reducing diversity. In contrast, we transform scalar rewards into a normalized target distribution using a learnable partition function, and then minimize the reverse KL divergence between the policy and the target distribution. We implement this idea as a flow-balanced optimization method that promotes diverse exploration and generalizable reasoning trajectories. We conduct experiments on math and code reasoning tasks: FlowRL achieves a significant average improvement of $10.0\%$ over GRPO and $5.1\%$ over PPO on math benchmarks, and performs consistently better on code reasoning tasks. These results highlight reward distribution-matching as a key step toward efficient exploration and diverse reasoning in LLM reinforcement learning.
Towards Adaptive ML Benchmarks: Web-Agent-Driven Construction, Domain Expansion, and Metric Optimization
Sep 11, 2025Recent advances in large language models (LLMs) have enabled the emergence of general-purpose agents for automating end-to-end machine learning (ML) workflows, including data analysis, feature engineering, model training, and competition solving. However, existing benchmarks remain limited in task coverage, domain diversity, difficulty modeling, and evaluation rigor, failing to capture the full capabilities of such agents in realistic settings. We present TAM Bench, a diverse, realistic, and structured benchmark for evaluating LLM-based agents on end-to-end ML tasks. TAM Bench features three key innovations: (1) A browser automation and LLM-based task acquisition system that automatically collects and structures ML challenges from platforms such as Kaggle, AIcrowd, and Biendata, spanning multiple task types and data modalities (e.g., tabular, text, image, graph, audio); (2) A leaderboard-driven difficulty modeling mechanism that estimates task complexity using participant counts and score dispersion, enabling scalable and objective task calibration; (3) A multi-dimensional evaluation framework incorporating performance, format compliance, constraint adherence, and task generalization. Based on 150 curated AutoML tasks, we construct three benchmark subsets of different sizes -- Lite, Medium, and Full -- designed for varying evaluation scenarios. The Lite version, with 18 tasks and balanced coverage across modalities and difficulty levels, serves as a practical testbed for daily benchmarking and comparative studies.
Breaking Obfuscation: Cluster-Aware Graph with LLM-Aided Recovery for Malicious JavaScript Detection
Jul 30, 2025With the rapid expansion of web-based applications and cloud services, malicious JavaScript code continues to pose significant threats to user privacy, system integrity, and enterprise security. But, detecting such threats remains challenging due to sophisticated code obfuscation techniques and JavaScript's inherent language characteristics, particularly its nested closure structures and syntactic flexibility. In this work, we propose DeCoda, a hybrid defense framework that combines large language model (LLM)-based deobfuscation with code graph learning: (1) We first construct a sophisticated prompt-learning pipeline with multi-stage refinement, where the LLM progressively reconstructs the original code structure from obfuscated inputs and then generates normalized Abstract Syntax Tree (AST) representations; (2) In JavaScript ASTs, dynamic typing scatters semantically similar nodes while deeply nested functions fracture scope capturing, introducing structural noise and semantic ambiguity. To address these challenges, we then propose to learn hierarchical code graph representations via a Cluster-wise Graph that synergistically integrates graph transformer network, node clustering, and node-to-cluster attention to simultaneously capture both local node-level semantics and global cluster-induced structural relationships from AST graph. Experimental results demonstrate that our method achieves F1-scores of 94.64% and 97.71% on two benchmark datasets, demonstrating absolute improvements of 10.74% and 13.85% over state-of-the-art baselines. In false-positive control evaluation at fixed FPR levels (0.0001, 0.001, 0.01), our approach delivers 4.82, 5.91, and 2.53 higher TPR respectively compared to the best-performing baseline. These results highlight the effectiveness of LLM-based deobfuscation and underscore the importance of modeling cluster-level relationships in detecting malicious code.
SmartHome-Bench: A Comprehensive Benchmark for Video Anomaly Detection in Smart Homes Using Multi-Modal Large Language Models
Jun 15, 2025



Video anomaly detection (VAD) is essential for enhancing safety and security by identifying unusual events across different environments. Existing VAD benchmarks, however, are primarily designed for general-purpose scenarios, neglecting the specific characteristics of smart home applications. To bridge this gap, we introduce SmartHome-Bench, the first comprehensive benchmark specially designed for evaluating VAD in smart home scenarios, focusing on the capabilities of multi-modal large language models (MLLMs). Our newly proposed benchmark consists of 1,203 videos recorded by smart home cameras, organized according to a novel anomaly taxonomy that includes seven categories, such as Wildlife, Senior Care, and Baby Monitoring. Each video is meticulously annotated with anomaly tags, detailed descriptions, and reasoning. We further investigate adaptation methods for MLLMs in VAD, assessing state-of-the-art closed-source and open-source models with various prompting techniques. Results reveal significant limitations in the current models' ability to detect video anomalies accurately. To address these limitations, we introduce the Taxonomy-Driven Reflective LLM Chain (TRLC), a new LLM chaining framework that achieves a notable 11.62% improvement in detection accuracy. The benchmark dataset and code are publicly available at https://github.com/Xinyi-0724/SmartHome-Bench-LLM.
Spark Transformer: Reactivating Sparsity in FFN and Attention
Jun 07, 2025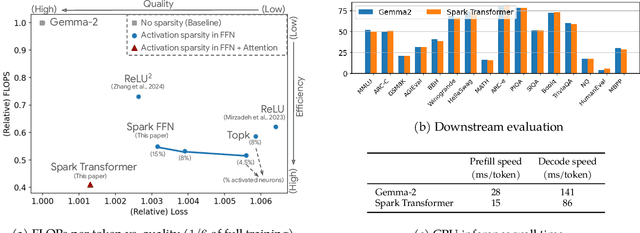
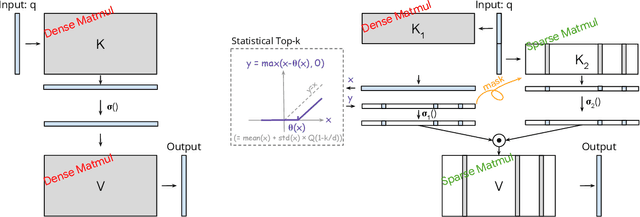
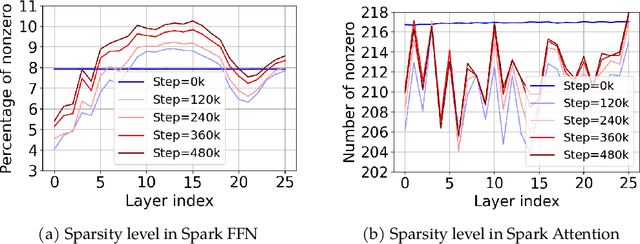
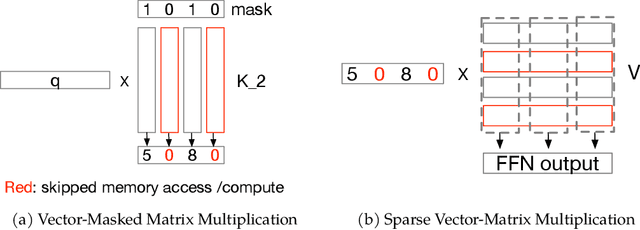
The discovery of the lazy neuron phenomenon in trained Transformers, where the vast majority of neurons in their feed-forward networks (FFN) are inactive for each token, has spurred tremendous interests in activation sparsity for enhancing large model efficiency. While notable progress has been made in translating such sparsity to wall-time benefits, modern Transformers have moved away from the ReLU activation function crucial to this phenomenon. Existing efforts on re-introducing activation sparsity often degrade model quality, increase parameter count, complicate or slow down training. Sparse attention, the application of sparse activation to the attention mechanism, often faces similar challenges. This paper introduces the Spark Transformer, a novel architecture that achieves a high level of activation sparsity in both FFN and the attention mechanism while maintaining model quality, parameter count, and standard training procedures. Our method realizes sparsity via top-k masking for explicit control over sparsity level. Crucially, we introduce statistical top-k, a hardware-accelerator-friendly, linear-time approximate algorithm that avoids costly sorting and mitigates significant training slowdown from standard top-$k$ operators. Furthermore, Spark Transformer reallocates existing FFN parameters and attention key embeddings to form a low-cost predictor for identifying activated entries. This design not only mitigates quality loss from enforced sparsity, but also enhances wall-time benefit. Pretrained with the Gemma-2 recipe, Spark Transformer demonstrates competitive performance on standard benchmarks while exhibiting significant sparsity: only 8% of FFN neurons are activated, and each token attends to a maximum of 256 tokens. This sparsity translates to a 2.5x reduction in FLOPs, leading to decoding wall-time speedups of up to 1.79x on CPU and 1.40x on GPU.
VRAG-RL: Empower Vision-Perception-Based RAG for Visually Rich Information Understanding via Iterative Reasoning with Reinforcement Learning
May 28, 2025Effectively retrieving, reasoning and understanding visually rich information remains a challenge for RAG methods. Traditional text-based methods cannot handle visual-related information. On the other hand, current vision-based RAG approaches are often limited by fixed pipelines and frequently struggle to reason effectively due to the insufficient activation of the fundamental capabilities of models. As RL has been proven to be beneficial for model reasoning, we introduce VRAG-RL, a novel RL framework tailored for complex reasoning across visually rich information. With this framework, VLMs interact with search engines, autonomously sampling single-turn or multi-turn reasoning trajectories with the help of visual perception tokens and undergoing continual optimization based on these samples. Our approach highlights key limitations of RL in RAG domains: (i) Prior Multi-modal RAG approaches tend to merely incorporate images into the context, leading to insufficient reasoning token allocation and neglecting visual-specific perception; and (ii) When models interact with search engines, their queries often fail to retrieve relevant information due to the inability to articulate requirements, thereby leading to suboptimal performance. To address these challenges, we define an action space tailored for visually rich inputs, with actions including cropping and scaling, allowing the model to gather information from a coarse-to-fine perspective. Furthermore, to bridge the gap between users' original inquiries and the retriever, we employ a simple yet effective reward that integrates query rewriting and retrieval performance with a model-based reward. Our VRAG-RL optimizes VLMs for RAG tasks using specially designed RL strategies, aligning the model with real-world applications. The code is available at \hyperlink{https://github.com/Alibaba-NLP/VRAG}{https://github.com/Alibaba-NLP/VRAG}.
Prototype Embedding Optimization for Human-Object Interaction Detection in Livestreaming
May 28, 2025Livestreaming often involves interactions between streamers and objects, which is critical for understanding and regulating web content. While human-object interaction (HOI) detection has made some progress in general-purpose video downstream tasks, when applied to recognize the interaction behaviors between a streamer and different objects in livestreaming, it tends to focuses too much on the objects and neglects their interactions with the streamer, which leads to object bias. To solve this issue, we propose a prototype embedding optimization for human-object interaction detection (PeO-HOI). First, the livestreaming is preprocessed using object detection and tracking techniques to extract features of the human-object (HO) pairs. Then, prototype embedding optimization is adopted to mitigate the effect of object bias on HOI. Finally, after modelling the spatio-temporal context between HO pairs, the HOI detection results are obtained by the prediction head. The experimental results show that the detection accuracy of the proposed PeO-HOI method has detection accuracies of 37.19%@full, 51.42%@non-rare, 26.20%@rare on the publicly available dataset VidHOI, 45.13%@full, 62.78%@non-rare and 30.37%@rare on the self-built dataset BJUT-HOI, which effectively improves the HOI detection performance in livestreaming.