 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpark Transformer: Reactivating Sparsity in FFN and Attention
Jun 07, 2025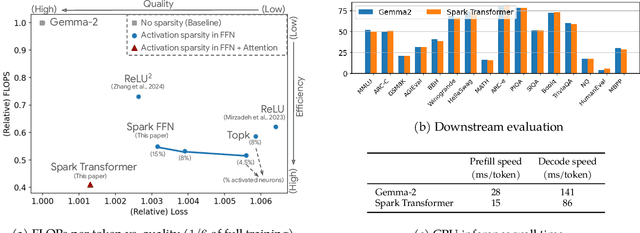
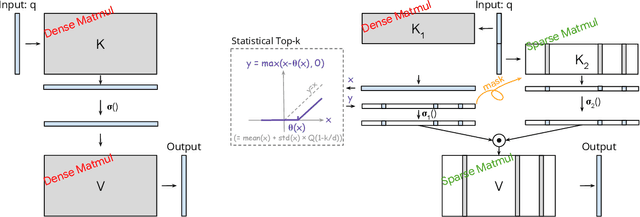
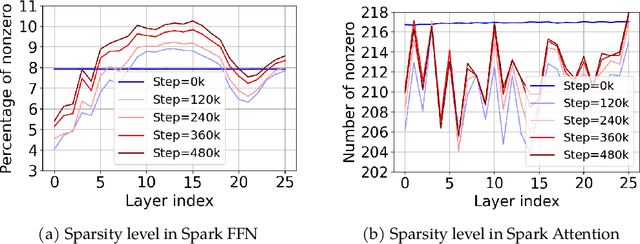
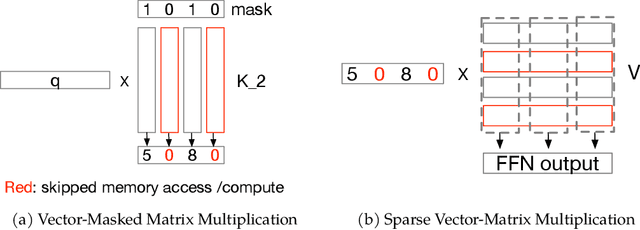
The discovery of the lazy neuron phenomenon in trained Transformers, where the vast majority of neurons in their feed-forward networks (FFN) are inactive for each token, has spurred tremendous interests in activation sparsity for enhancing large model efficiency. While notable progress has been made in translating such sparsity to wall-time benefits, modern Transformers have moved away from the ReLU activation function crucial to this phenomenon. Existing efforts on re-introducing activation sparsity often degrade model quality, increase parameter count, complicate or slow down training. Sparse attention, the application of sparse activation to the attention mechanism, often faces similar challenges. This paper introduces the Spark Transformer, a novel architecture that achieves a high level of activation sparsity in both FFN and the attention mechanism while maintaining model quality, parameter count, and standard training procedures. Our method realizes sparsity via top-k masking for explicit control over sparsity level. Crucially, we introduce statistical top-k, a hardware-accelerator-friendly, linear-time approximate algorithm that avoids costly sorting and mitigates significant training slowdown from standard top-$k$ operators. Furthermore, Spark Transformer reallocates existing FFN parameters and attention key embeddings to form a low-cost predictor for identifying activated entries. This design not only mitigates quality loss from enforced sparsity, but also enhances wall-time benefit. Pretrained with the Gemma-2 recipe, Spark Transformer demonstrates competitive performance on standard benchmarks while exhibiting significant sparsity: only 8% of FFN neurons are activated, and each token attends to a maximum of 256 tokens. This sparsity translates to a 2.5x reduction in FLOPs, leading to decoding wall-time speedups of up to 1.79x on CPU and 1.40x on GPU.