 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpark Transformer: Reactivating Sparsity in FFN and Attention
Jun 07, 2025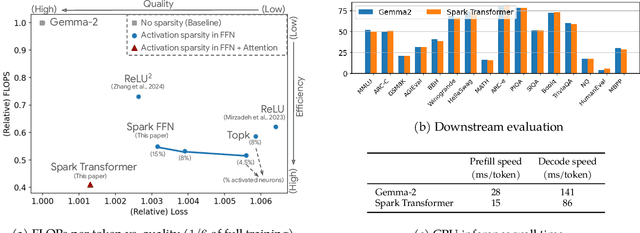
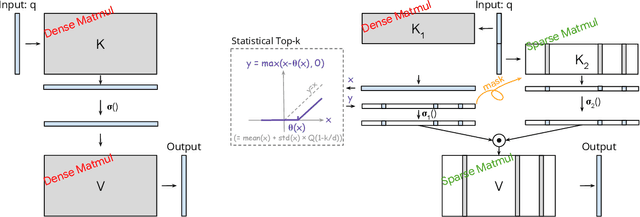
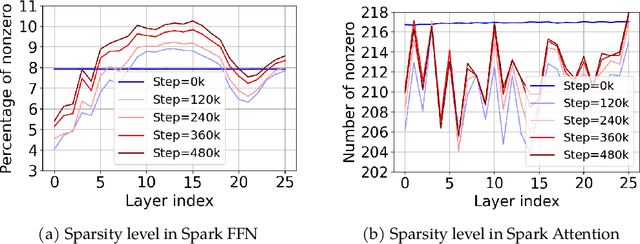
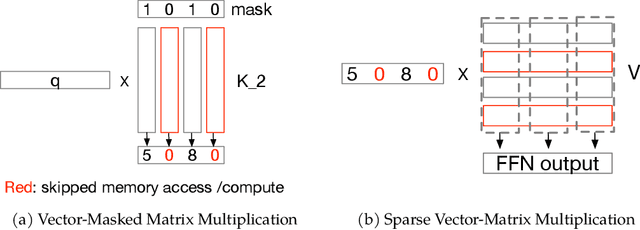
The discovery of the lazy neuron phenomenon in trained Transformers, where the vast majority of neurons in their feed-forward networks (FFN) are inactive for each token, has spurred tremendous interests in activation sparsity for enhancing large model efficiency. While notable progress has been made in translating such sparsity to wall-time benefits, modern Transformers have moved away from the ReLU activation function crucial to this phenomenon. Existing efforts on re-introducing activation sparsity often degrade model quality, increase parameter count, complicate or slow down training. Sparse attention, the application of sparse activation to the attention mechanism, often faces similar challenges. This paper introduces the Spark Transformer, a novel architecture that achieves a high level of activation sparsity in both FFN and the attention mechanism while maintaining model quality, parameter count, and standard training procedures. Our method realizes sparsity via top-k masking for explicit control over sparsity level. Crucially, we introduce statistical top-k, a hardware-accelerator-friendly, linear-time approximate algorithm that avoids costly sorting and mitigates significant training slowdown from standard top-$k$ operators. Furthermore, Spark Transformer reallocates existing FFN parameters and attention key embeddings to form a low-cost predictor for identifying activated entries. This design not only mitigates quality loss from enforced sparsity, but also enhances wall-time benefit. Pretrained with the Gemma-2 recipe, Spark Transformer demonstrates competitive performance on standard benchmarks while exhibiting significant sparsity: only 8% of FFN neurons are activated, and each token attends to a maximum of 256 tokens. This sparsity translates to a 2.5x reduction in FLOPs, leading to decoding wall-time speedups of up to 1.79x on CPU and 1.40x on GPU.
Vectorized and performance-portable Quicksort
May 12, 2022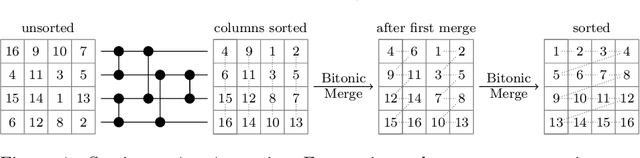

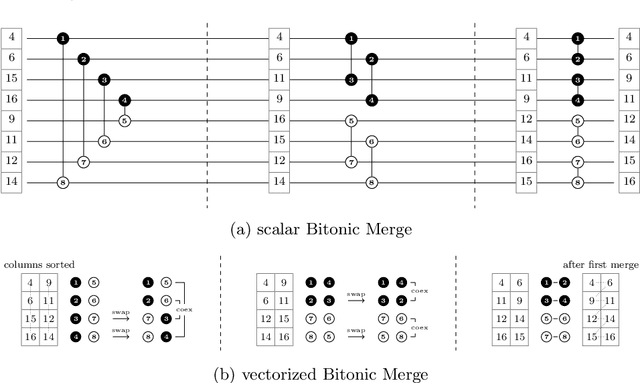

Recent works showed that implementations of Quicksort using vector CPU instructions can outperform the non-vectorized algorithms in widespread use. However, these implementations are typically single-threaded, implemented for a particular instruction set, and restricted to a small set of key types. We lift these three restrictions: our proposed 'vqsort' algorithm integrates into the state-of-the-art parallel sorter 'ips4o', with a geometric mean speedup of 1.59. The same implementation works on seven instruction sets (including SVE and RISC-V V) across four platforms. It also supports floating-point and 16-128 bit integer keys. To the best of our knowledge, this is the fastest sort for non-tuple keys on CPUs, up to 20 times as fast as the sorting algorithms implemented in standard libraries. This paper focuses on the practical engineering aspects enabling the speed and portability, which we have not yet seen demonstrated for a Quicksort implementation. Furthermore, we introduce compact and transpose-free sorting networks for in-register sorting of small arrays, and a vector-friendly pivot sampling strategy that is robust against adversarial input.
Noise generation for compression algorithms
Mar 24, 2018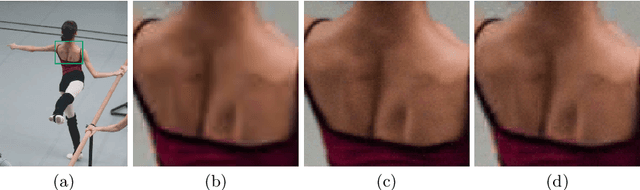
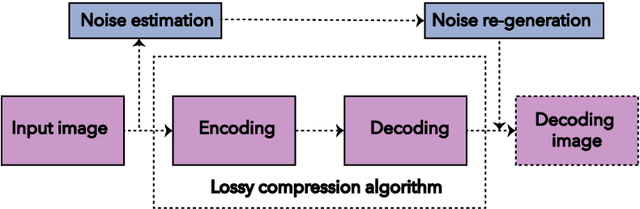
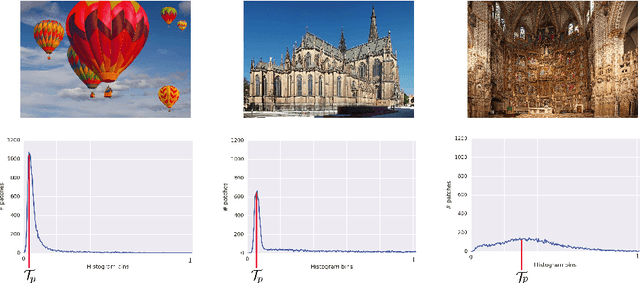
In various Computer Vision and Signal Processing applications, noise is typically perceived as a drawback of the image capturing system that ought to be removed. We, on the other hand, claim that image noise, just as texture, is important for visual perception and, therefore, critical for lossy compression algorithms that tend to make decompressed images look less realistic by removing small image details. In this paper we propose a physically and biologically inspired technique that learns a noise model at the encoding step of the compression algorithm and then generates the appropriate amount of additive noise at the decoding step. Our method can significantly increase the realism of the decompressed image at the cost of few bytes of additional memory space regardless of the original image size. The implementation of our method is open-sourced and available at https://github.com/google/pik.
Guetzli: Perceptually Guided JPEG Encoder
Mar 13, 2017



Guetzli is a new JPEG encoder that aims to produce visually indistinguishable images at a lower bit-rate than other common JPEG encoders. It optimizes both the JPEG global quantization tables and the DCT coefficient values in each JPEG block using a closed-loop optimizer. Guetzli uses Butteraugli, our perceptual distance metric, as the source of feedback in its optimization process. We reach a 29-45% reduction in data size for a given perceptual distance, according to Butteraugli, in comparison to other compressors we tried. Guetzli's computation is currently extremely slow, which limits its applicability to compressing static content and serving as a proof- of-concept that we can achieve significant reductions in size by combining advanced psychovisual models with lossy compression techniques.
Users prefer Guetzli JPEG over same-sized libjpeg
Mar 13, 2017We report on pairwise comparisons by human raters of JPEG images from libjpeg and our new Guetzli encoder. Although both files are size-matched, 75% of ratings are in favor of Guetzli. This implies the Butteraugli psychovisual image similarity metric which guides Guetzli is reasonably close to human perception at high quality levels. We provide access to the raw ratings and source images for further analysis and study.