 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnergy-Efficient Velocity Profile Optimization for Movable Antenna-Enabled Sensing Systems
Mar 29, 2026Movable antennas (MAs) enable the reconfiguration of array geometry within a bounded region to exploit sub-wavelength spatial degrees of freedom in wireless communication and sensing systems. However, most prior research has predominantly focused on the communication and sensing performance, overlooking the mechanical power consumption inherent in antenna movement. To bridge this gap, this paper investigates a velocity profile optimization framework for MA-assisted direction-of-arrival (DoA) estimation, explicitly balancing sensing accuracy with mechanical energy consumption of MAs. We first establish a Newtonian-based mechanical energy model, and formulate a functional optimization problem for sensing energy efficiency (EE) maximization. By applying the calculus of variations, this formulation is transformed into an infinite-dimensional problem defined by the Euler-Lagrange equation. To solve it, we propose a spectral discretization framework based on the Galerkin method, which expands the velocity profile over a sinusoidal basis. In the regime where energy consumption is dominated by linear damping, we prove that the optimal velocity profile follows a closed-form sinusoidal shape. For more general scenarios involving strong nonlinear aerodynamic drag, we leverage the Markov-Lukács theorem to transform the kinematic constraints into strictly convex sum-of-squares (SOS) conditions. Consequently, the infinite-dimensional problem is reformulated as a tractable finite-dimensional nonlinear algebraic system, which is solved by a two-layer algorithm combining Dinkelbach's method with successive convex approximation (SCA). Numerical results demonstrate that our optimized velocity profile significantly outperforms baselines in terms of EE across various system configurations. Insights into the optimized velocity profiles and practical design guidelines are also provided.
Feature Resemblance: On the Theoretical Understanding of Analogical Reasoning in Transformers
Mar 05, 2026Understanding reasoning in large language models is complicated by evaluations that conflate multiple reasoning types. We isolate analogical reasoning (inferring shared properties between entities based on known similarities) and analyze its emergence in transformers. We theoretically prove three key results: (1) Joint training on similarity and attribution premises enables analogical reasoning through aligned representations; (2) Sequential training succeeds only when similarity structure is learned before specific attributes, revealing a necessary curriculum; (3) Two-hop reasoning ($a \to b, b \to c \implies a \to c$) reduces to analogical reasoning with identity bridges ($b = b$), which must appear explicitly in training data. These results reveal a unified mechanism: transformers encode entities with similar properties into similar representations, enabling property transfer through feature alignment. Experiments with architectures up to 1.5B parameters validate our theory and demonstrate how representational geometry shapes inductive reasoning capabilities.
FedCova: Robust Federated Covariance Learning Against Noisy Labels
Mar 04, 2026Noisy labels in distributed datasets induce severe local overfitting and consequently compromise the global model in federated learning (FL). Most existing solutions rely on selecting clean devices or aligning with public clean datasets, rather than endowing the model itself with robustness. In this paper, we propose FedCova, a dependency-free federated covariance learning framework that eliminates such external reliances by enhancing the model's intrinsic robustness via a new perspective on feature covariances. Specifically, FedCova encodes data into a discriminative but resilient feature space to tolerate label noise. Built on mutual information maximization, we design a novel objective for federated lossy feature encoding that relies solely on class feature covariances with an error tolerance term. Leveraging feature subspaces characterized by covariances, we construct a subspace-augmented federated classifier. FedCova unifies three key processes through the covariance: (1) training the network for feature encoding, (2) constructing a classifier directly from the learned features, and (3) correcting noisy labels based on feature subspaces. We implement FedCova across both symmetric and asymmetric noisy settings under heterogeneous data distribution. Experimental results on CIFAR-10/100 and real-world noisy dataset Clothing1M demonstrate the superior robustness of FedCova compared with the state-of-the-art methods.
Training-Free Rate-Distortion-Perception Traversal With Diffusion
Mar 04, 2026The rate-distortion-perception (RDP) tradeoff characterizes the fundamental limits of lossy compression by jointly considering bitrate, reconstruction fidelity, and perceptual quality. While recent neural compression methods have improved perceptual performance, they typically operate at fixed points on the RDP surface, requiring retraining to target different tradeoffs. In this work, we propose a training-free framework that leverages pre-trained diffusion models to traverse the entire RDP surface. Our approach integrates a reverse channel coding (RCC) module with a novel score-scaled probability flow ODE decoder. We theoretically prove that the proposed diffusion decoder is optimal for the distortion-perception tradeoff under AWGN observations and that the overall framework with the RCC module achieves the optimal RDP function in the Gaussian case. Empirical results across multiple datasets demonstrate the framework's flexibility and effectiveness in navigating the ternary RDP tradeoff using pre-trained diffusion models. Our results establish a practical and theoretically grounded approach to adaptive, perception-aware compression.
Tackling Privacy Heterogeneity in Differentially Private Federated Learning
Feb 26, 2026Differentially private federated learning (DP-FL) enables clients to collaboratively train machine learning models while preserving the privacy of their local data. However, most existing DP-FL approaches assume that all clients share a uniform privacy budget, an assumption that does not hold in real-world scenarios where privacy requirements vary widely. This privacy heterogeneity poses a significant challenge: conventional client selection strategies, which typically rely on data quantity, cannot distinguish between clients providing high-quality updates and those introducing substantial noise due to strict privacy constraints. To address this gap, we present the first systematic study of privacy-aware client selection in DP-FL. We establish a theoretical foundation by deriving a convergence analysis that quantifies the impact of privacy heterogeneity on training error. Building on this analysis, we propose a privacy-aware client selection strategy, formulated as a convex optimization problem, that adaptively adjusts selection probabilities to minimize training error. Extensive experiments on benchmark datasets demonstrate that our approach achieves up to a 10% improvement in test accuracy on CIFAR-10 compared to existing baselines under heterogeneous privacy budgets. These results highlight the importance of incorporating privacy heterogeneity into client selection for practical and effective federated learning.
JSAM: Privacy Straggler-Resilient Joint Client Selection and Incentive Mechanism Design in Differentially Private Federated Learning
Feb 25, 2026Differentially private federated learning faces a fundamental tension: privacy protection mechanisms that safeguard client data simultaneously create quantifiable privacy costs that discourage participation, undermining the collaborative training process. Existing incentive mechanisms rely on unbiased client selection, forcing servers to compensate even the most privacy-sensitive clients ("privacy stragglers"), leading to systemic inefficiency and suboptimal resource allocation. We introduce JSAM (Joint client Selection and privacy compensAtion Mechanism), a Bayesian-optimal framework that simultaneously optimizes client selection probabilities and privacy compensation to maximize training effectiveness under budget constraints. Our approach transforms a complex 2N-dimensional optimization problem into an efficient three-dimensional formulation through novel theoretical characterization of optimal selection strategies. We prove that servers should preferentially select privacy-tolerant clients while excluding high-sensitivity participants, and uncover the counter-intuitive insight that clients with minimal privacy sensitivity may incur the highest cumulative costs due to frequent participation. Extensive evaluations on MNIST and CIFAR-10 demonstrate that JSAM achieves up to 15% improvement in test accuracy compared to existing unbiased selection mechanisms while maintaining cost efficiency across varying data heterogeneity levels.
FISMO: Fisher-Structured Momentum-Orthogonalized Optimizer
Jan 29, 2026Training large-scale neural networks requires solving nonconvex optimization where the choice of optimizer fundamentally determines both convergence behavior and computational efficiency. While adaptive methods like Adam have long dominated practice, the recently proposed Muon optimizer achieves superior performance through orthogonalized momentum updates that enforce isotropic geometry with uniform singular values. However, this strict isotropy discards potentially valuable curvature information encoded in gradient spectra, motivating optimization methods that balance geometric structure with adaptivity. We introduce FISMO (Fisher-Structured Momentum-Orthogonalized) optimizer, which generalizes isotropic updates to incorporate anisotropic curvature information through Fisher information geometry. By reformulating the optimizer update as a trust-region problem constrained by a Kronecker-factored Fisher metric, FISMO achieves structured preconditioning that adapts to local loss landscape geometry while maintaining computational tractability. We establish convergence guarantees for FISMO in stochastic nonconvex settings, proving an $\mathcal{O}(1/\sqrt{T})$ rate for the expected squared gradient norm with explicit characterization of variance reduction through mini-batching. Empirical evaluation on image classification and language modeling benchmarks demonstrates that FISMO achieves superior training efficiency and final performance compared to established baselines.
Near-Field Multi-User Communications via Polar-Domain Beamfocusing: Analytical Framework and Performance Analysis
Dec 19, 2025As wireless systems evolve toward higher frequencies and extremely large antenna arrays, near-field (NF) propagation becomes increasingly dominant. Unlike far-field (FF) communication, which relies on a planar-wavefront model and is limited to angular-domain beamsteering, NF propagation exhibits spherical wavefronts that enable beamfocusing in both angle and distance, i.e., the polar domain, offering new opportunities for spatial multiple access. This paper develops an analytical stochastic geometry (SG) framework for a multi-user system assisted by polar-domain beamfocusing, which jointly captures NF propagation characteristics and the spatial randomness of user locations. The intrinsic coupling between angle and distance in the NF antenna pattern renders inter-user interference analysis intractable. To address this challenge, we propose a tractable near-field multi-level antenna pattern (NF-MLAP) approximation, which enables computationally efficient expressions and tight upper bounds for key performance metrics, including coverage probability, spectrum efficiency, and area spectrum efficiency. Analytical and simulation results demonstrate that the proposed framework accurately captures performance trends and reveals fundamental trade-offs between hardware configuration (including the number of antennas and radio frequency chains) and system performance (in terms of spatial resource reuse and interference mitigation).
Near-Field Position and Orientation Tracking With Hybrid ELAA Architecture
Dec 19, 2025



This paper investigates near-field (NF) position and orientation tracking of a multi-antenna mobile station (MS) using an extremely large antenna array (ELAA)-equipped base station (BS) with a limited number of radio frequency (RF) chains. Under this hybrid array architecture, the received uplink pilot signal at the BS is first combined by analog phase shifters, producing a low-dimensional observation before digital processing. Such analog compression provides only partial access to the ELAA measurement, making it essential to design an analog combiner that can preserve pose-relevant signal components despite channel uncertainty and unit-modulus hardware constraints. To address this, we propose a predictive analog combining-assisted extended Kalman filter (PAC-EKF) framework, where the analog combiner can leverage the temporal correlation in the MS pose variation to capture the most informative signal components predictively. We then analyze fundamental performance limits via Bayesian Cramér-Rao bound and Fisher information matrix, explicitly quantifying how the analog combiner, array size, signal-to-noise ratio, and MS pose influence the pose information contained in the uplink observation. Building on these insights, we develop two methods for designing a low-complexity analog combiner. Numerical results show that the proposed predictive analog combining approach significantly improves tracking accuracy, even with fewer RF chains and lower transmit power.
Near-Field Beam Training Through Beam Diverging
Sep 19, 2025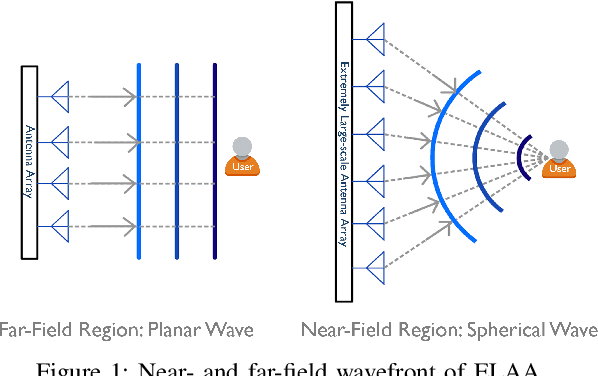
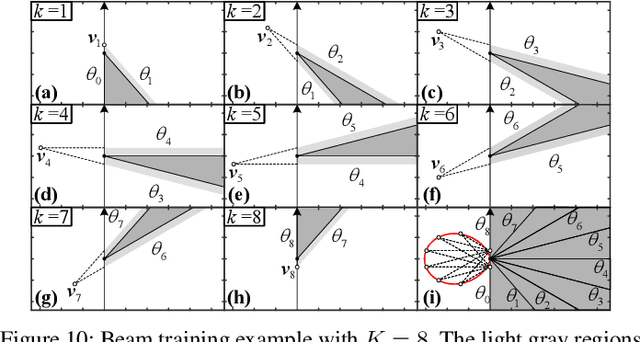
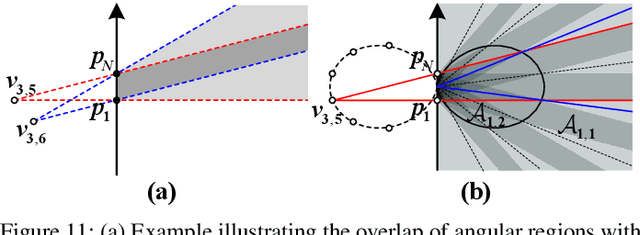
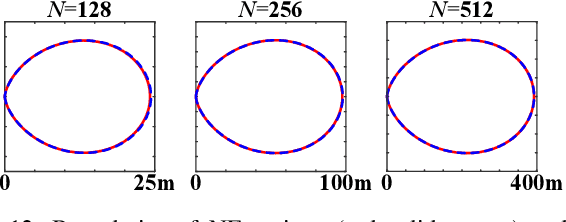
This paper investigates beam training techniques for near-field (NF) extremely large-scale antenna arrays (ELAAs). Existing NF beam training methods predominantly rely on beam focusing, where the base station (BS) transmits highly spatially selective beams to locate the user equipment (UE). However, these beam-focusing-based schemes suffer from both high beam sweeping overhead and limited accuracy in the NF, primarily due to the narrow beams' high susceptibility to misalignment. To address this, we propose a novel NF beam training paradigm using diverging beams. Specifically, we introduce the beam diverging effect and exploit it for low-overhead, high-accuracy beam training. First, we design a diverging codeword to induce the beam diverging effect with a single radio frequency (RF) chain. Next, we develop a diverging polar-domain codebook (DPC) along with a hierarchical method that enables angular-domain localization of the UE with only 2 log_2(N) pilots, where N denotes the number of antennas. Finally, we enhance beam training performance through two additional techniques: a DPC angular range reduction strategy to improve the effectiveness of beam diverging, and a pilot set expansion method to increase overall beam training accuracy. Numerical results show that our algorithm achieves near-optimal accuracy with a small pilot overhead, outperforming existing methods.