 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Optimal Caching and Model Multiplexing for Large Model Inference
Jun 03, 2023Large Language Models (LLMs) and other large foundation models have achieved noteworthy success, but their size exacerbates existing resource consumption and latency challenges. In particular, the large-scale deployment of these models is hindered by the significant resource requirements during inference. In this paper, we study two approaches for mitigating these challenges: employing a cache to store previous queries and learning a model multiplexer to choose from an ensemble of models for query processing. Theoretically, we provide an optimal algorithm for jointly optimizing both approaches to reduce the inference cost in both offline and online tabular settings. By combining a caching algorithm, namely Greedy Dual Size with Frequency (GDSF) or Least Expected Cost (LEC), with a model multiplexer, we achieve optimal rates in both offline and online settings. Empirically, simulations show that the combination of our caching and model multiplexing algorithms greatly improves over the baselines, with up to $50\times$ improvement over the baseline when the ratio between the maximum cost and minimum cost is $100$. Experiments on real datasets show a $4.3\times$ improvement in FLOPs over the baseline when the ratio for FLOPs is $10$, and a $1.8\times$ improvement in latency when the ratio for average latency is $1.85$.
High-throughput Generative Inference of Large Language Models with a Single GPU
Mar 13, 2023



The high computational and memory requirements of large language model (LLM) inference traditionally make it feasible only with multiple high-end accelerators. Motivated by the emerging demand for latency-insensitive tasks with batched processing, this paper initiates the study of high-throughput LLM inference using limited resources, such as a single commodity GPU. We present FlexGen, a high-throughput generation engine for running LLMs with limited GPU memory. FlexGen can be flexibly configured under various hardware resource constraints by aggregating memory and computation from the GPU, CPU, and disk. Through a linear programming optimizer, it searches for efficient patterns to store and access tensors. FlexGen further compresses these weights and the attention cache to 4 bits with negligible accuracy loss. These techniques enable FlexGen to have a larger space of batch size choices and thus significantly increase maximum throughput. As a result, when running OPT-175B on a single 16GB GPU, FlexGen achieves significantly higher throughput compared to state-of-the-art offloading systems, reaching a generation throughput of 1 token/s for the first time with an effective batch size of 144. On the HELM benchmark, FlexGen can benchmark a 30B model with a 16GB GPU on 7 representative sub-scenarios in 21 hours. The code is available at https://github.com/FMInference/FlexGen
AlpaServe: Statistical Multiplexing with Model Parallelism for Deep Learning Serving
Feb 22, 2023Model parallelism is conventionally viewed as a method to scale a single large deep learning model beyond the memory limits of a single device. In this paper, we demonstrate that model parallelism can be additionally used for the statistical multiplexing of multiple devices when serving multiple models, even when a single model can fit into a single device. Our work reveals a fundamental trade-off between the overhead introduced by model parallelism and the opportunity to exploit statistical multiplexing to reduce serving latency in the presence of bursty workloads. We explore the new trade-off space and present a novel serving system, AlpaServe, that determines an efficient strategy for placing and parallelizing collections of large deep learning models across a distributed cluster. Evaluation results on production workloads show that AlpaServe can process requests at up to 10x higher rates or 6x more burstiness while staying within latency constraints for more than 99% of requests.
On Optimizing the Communication of Model Parallelism
Nov 10, 2022

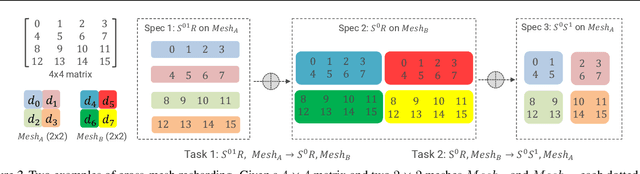
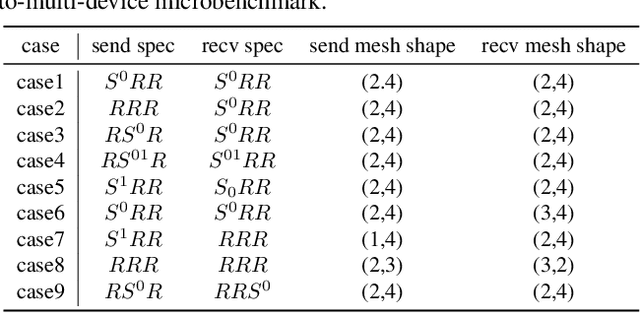
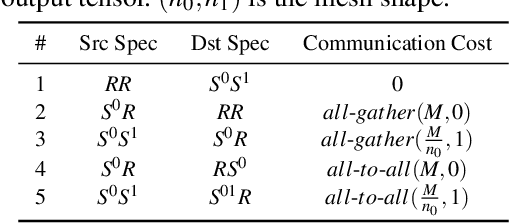
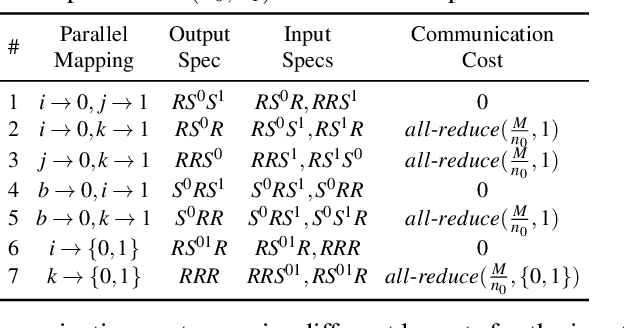
We study a novel and important communication pattern in large-scale model-parallel deep learning (DL), which we call cross-mesh resharding. This pattern emerges when the two paradigms of model parallelism - intra-operator and inter-operator parallelism - are combined to support large models on large clusters. In cross-mesh resharding, a sharded tensor needs to be sent from a source device mesh to a destination device mesh, on which the tensor may be distributed with the same or different layouts. We formalize this as a many-to-many multicast communication problem, and show that existing approaches either are sub-optimal or do not generalize to different network topologies or tensor layouts, which result from different model architectures and parallelism strategies. We then propose two contributions to address cross-mesh resharding: an efficient broadcast-based communication system, and an "overlapping-friendly" pipeline schedule. On microbenchmarks, our overall system outperforms existing ones by up to 10x across various tensor and mesh layouts. On end-to-end training of two large models, GPT-3 and U-Transformer, we improve throughput by 10% and 50%, respectively.
TensorIR: An Abstraction for Automatic Tensorized Program Optimization
Jul 09, 2022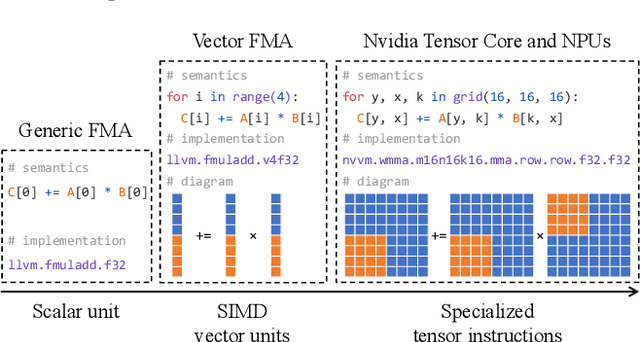

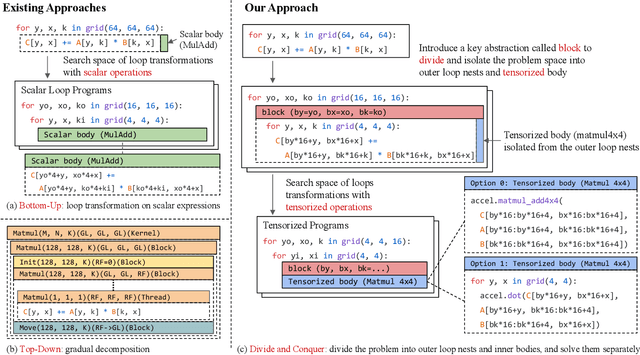
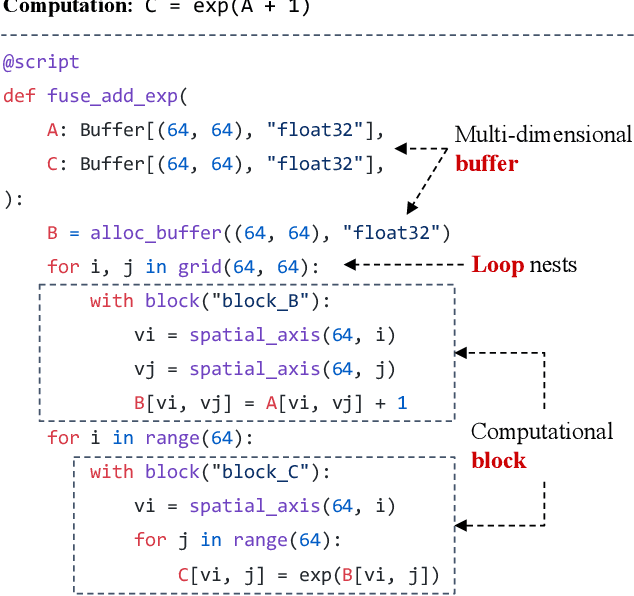
Deploying deep learning models on various devices has become an important topic. The wave of hardware specialization brings a diverse set of acceleration primitives for multi-dimensional tensor computations. These new acceleration primitives, along with the emerging machine learning models, bring tremendous engineering challenges. In this paper, we present TensorIR, a compiler abstraction for optimizing programs with these tensor computation primitives. TensorIR generalizes the loop nest representation used in existing machine learning compilers to bring tensor computation as the first-class citizen. Finally, we build an end-to-end framework on top of our abstraction to automatically optimize deep learning models for given tensor computation primitives. Experimental results show that TensorIR compilation automatically uses the tensor computation primitives for given hardware backends and delivers performance that is competitive to state-of-art hand-optimized systems across platforms.
NumS: Scalable Array Programming for the Cloud
Jun 28, 2022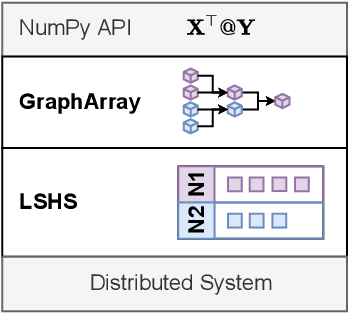

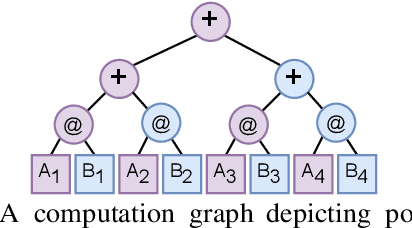
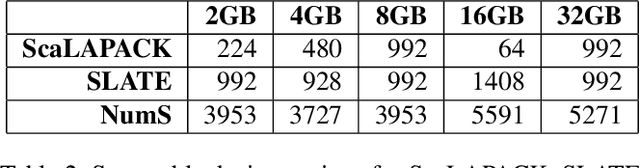
Scientists increasingly rely on Python tools to perform scalable distributed memory array operations using rich, NumPy-like expressions. However, many of these tools rely on dynamic schedulers optimized for abstract task graphs, which often encounter memory and network bandwidth-related bottlenecks due to sub-optimal data and operator placement decisions. Tools built on the message passing interface (MPI), such as ScaLAPACK and SLATE, have better scaling properties, but these solutions require specialized knowledge to use. In this work, we present NumS, an array programming library which optimizes NumPy-like expressions on task-based distributed systems. This is achieved through a novel scheduler called Load Simulated Hierarchical Scheduling (LSHS). LSHS is a local search method which optimizes operator placement by minimizing maximum memory and network load on any given node within a distributed system. Coupled with a heuristic for load balanced data layouts, our approach is capable of attaining communication lower bounds on some common numerical operations, and our empirical study shows that LSHS enhances performance on Ray by decreasing network load by a factor of 2x, requiring 4x less memory, and reducing execution time by 10x on the logistic regression problem. On terabyte-scale data, NumS achieves competitive performance to SLATE on DGEMM, up to 20x speedup over Dask on a key operation for tensor factorization, and a 2x speedup on logistic regression compared to Dask ML and Spark's MLlib.
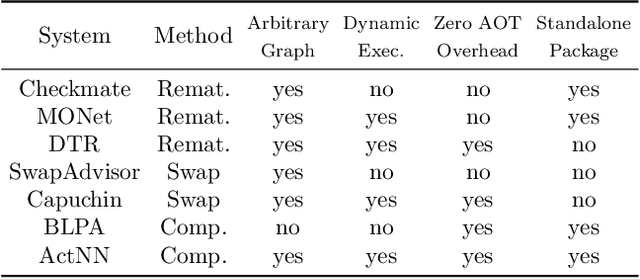
GACT: Activation Compressed Training for General Architectures
Jun 28, 2022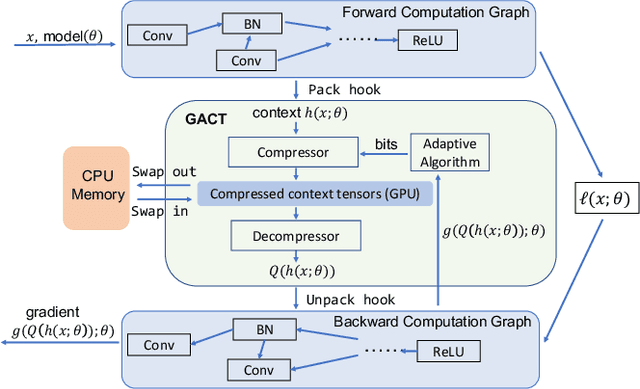
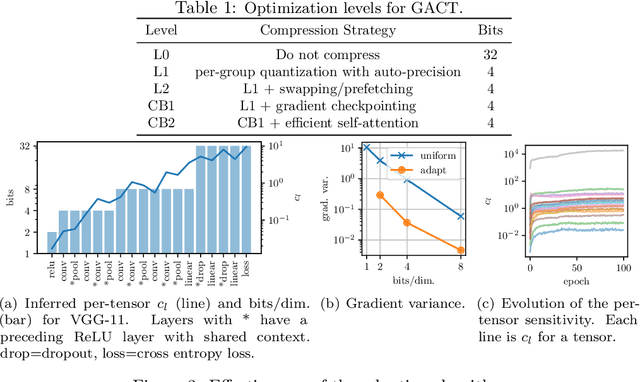

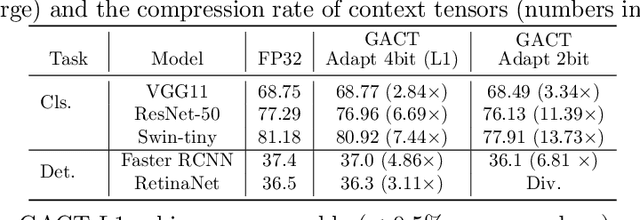
Training large neural network (NN) models requires extensive memory resources, and Activation Compressed Training (ACT) is a promising approach to reduce training memory footprint. This paper presents GACT, an ACT framework to support a broad range of machine learning tasks for generic NN architectures with limited domain knowledge. By analyzing a linearized version of ACT's approximate gradient, we prove the convergence of GACT without prior knowledge on operator type or model architecture. To make training stable, we propose an algorithm that decides the compression ratio for each tensor by estimating its impact on the gradient at run time. We implement GACT as a PyTorch library that readily applies to any NN architecture. GACT reduces the activation memory for convolutional NNs, transformers, and graph NNs by up to 8.1x, enabling training with a 4.2x to 24.7x larger batch size, with negligible accuracy loss.
Alpa: Automating Inter- and Intra-Operator Parallelism for Distributed Deep Learning
Jan 28, 2022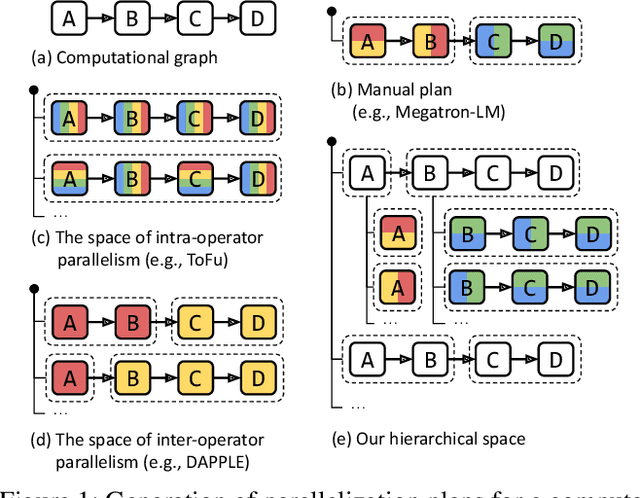

Alpa automates model-parallel training of large deep learning (DL) models by generating execution plans that unify data, operator, and pipeline parallelism. Existing model-parallel training systems either require users to manually create a parallelization plan or automatically generate one from a limited space of model parallelism configurations, which does not suffice to scale out complex DL models on distributed compute devices. Alpa distributes the training of large DL models by viewing parallelisms as two hierarchical levels: inter-operator and intra-operator parallelisms. Based on it, Alpa constructs a new hierarchical space for massive model-parallel execution plans. Alpa designs a number of compilation passes to automatically derive the optimal parallel execution plan in each independent parallelism level and implements an efficient runtime to orchestrate the two-level parallel execution on distributed compute devices. Our evaluation shows Alpa generates parallelization plans that match or outperform hand-tuned model-parallel training systems even on models they are designed for. Unlike specialized systems, Alpa also generalizes to models with heterogeneous architectures and models without manually-designed plans.
ActNN: Reducing Training Memory Footprint via 2-Bit Activation Compressed Training
Apr 29, 2021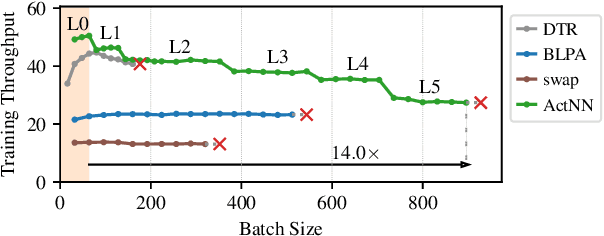

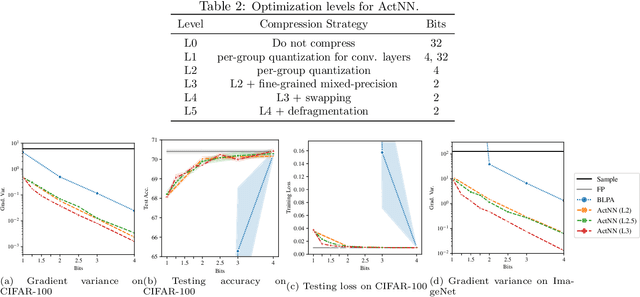
The increasing size of neural network models has been critical for improvements in their accuracy, but device memory is not growing at the same rate. This creates fundamental challenges for training neural networks within limited memory environments. In this work, we propose ActNN, a memory-efficient training framework that stores randomly quantized activations for back propagation. We prove the convergence of ActNN for general network architectures, and we characterize the impact of quantization on the convergence via an exact expression for the gradient variance. Using our theory, we propose novel mixed-precision quantization strategies that exploit the activation's heterogeneity across feature dimensions, samples, and layers. These techniques can be readily applied to existing dynamic graph frameworks, such as PyTorch, simply by substituting the layers. We evaluate ActNN on mainstream computer vision models for classification, detection, and segmentation tasks. On all these tasks, ActNN compresses the activation to 2 bits on average, with negligible accuracy loss. ActNN reduces the memory footprint of the activation by 12x, and it enables training with a 6.6x to 14x larger batch size.
Ansor : Generating High-Performance Tensor Programs for Deep Learning
Jun 15, 2020

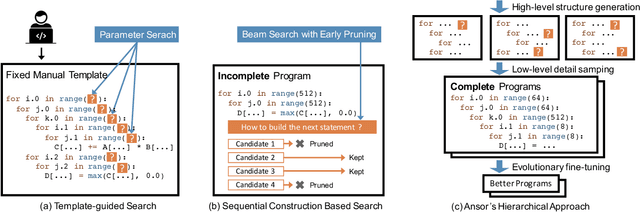
High-performance tensor programs are crucial to guarantee efficient execution of deep learning models. However, obtaining performant tensor programs for different operators on various hardware platforms is notoriously difficult. Currently, deep learning systems rely on vendor-provided kernel libraries or various search strategies to get performant tensor programs. These approaches either require significant engineering efforts in developing platform-specific optimization code or fall short in finding high-performance programs due to restricted search space and ineffective exploration strategy. We present Ansor, a tensor program generation framework for deep learning applications. Compared with existing search strategies, Ansor explores much more optimization combinations by sampling programs from a hierarchical representation of the search space. Ansor then fine-tunes the sampled programs with evolutionary search and a learned cost model to identify the best programs. Ansor can find high-performance programs that are outside the search space of existing state-of-the-art approaches. Besides, Ansor utilizes a scheduler to simultaneously optimize multiple subgraphs in a set of deep neural networks. Our evaluation shows that Ansor improves the execution performance of deep neural networks on the Intel CPU, ARM CPU, and NVIDIA GPU by up to $3.8\times$, $2.6\times$, and $1.7 \times$, respectively.