 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficiently Programming Large Language Models using SGLang
Dec 12, 2023Large language models (LLMs) are increasingly used for complex tasks requiring multiple chained generation calls, advanced prompting techniques, control flow, and interaction with external environments. However, efficient systems for programming and executing these applications are lacking. To bridge this gap, we introduce SGLang, a Structured Generation Language for LLMs. SGLang is designed for the efficient programming of LLMs and incorporates primitives for common LLM programming patterns. We have implemented SGLang as a domain-specific language embedded in Python, and we developed an interpreter, a compiler, and a high-performance runtime for SGLang. These components work together to enable optimizations such as parallelism, batching, caching, sharing, and other compilation techniques. Additionally, we propose RadixAttention, a novel technique that maintains a Least Recently Used (LRU) cache of the Key-Value (KV) cache for all requests in a radix tree, enabling automatic KV cache reuse across multiple generation calls at runtime. SGLang simplifies the writing of LLM programs and boosts execution efficiency. Our experiments demonstrate that SGLang can speed up common LLM tasks by up to 5x, while reducing code complexity and enhancing control.
Efficient Memory Management for Large Language Model Serving with PagedAttention
Sep 12, 2023



High throughput serving of large language models (LLMs) requires batching sufficiently many requests at a time. However, existing systems struggle because the key-value cache (KV cache) memory for each request is huge and grows and shrinks dynamically. When managed inefficiently, this memory can be significantly wasted by fragmentation and redundant duplication, limiting the batch size. To address this problem, we propose PagedAttention, an attention algorithm inspired by the classical virtual memory and paging techniques in operating systems. On top of it, we build vLLM, an LLM serving system that achieves (1) near-zero waste in KV cache memory and (2) flexible sharing of KV cache within and across requests to further reduce memory usage. Our evaluations show that vLLM improves the throughput of popular LLMs by 2-4$\times$ with the same level of latency compared to the state-of-the-art systems, such as FasterTransformer and Orca. The improvement is more pronounced with longer sequences, larger models, and more complex decoding algorithms. vLLM's source code is publicly available at https://github.com/vllm-project/vllm
RAF: Holistic Compilation for Deep Learning Model Training
Mar 08, 2023



As deep learning is pervasive in modern applications, many deep learning frameworks are presented for deep learning practitioners to develop and train DNN models rapidly. Meanwhile, as training large deep learning models becomes a trend in recent years, the training throughput and memory footprint are getting crucial. Accordingly, optimizing training workloads with compiler optimizations is inevitable and getting more and more attentions. However, existing deep learning compilers (DLCs) mainly target inference and do not incorporate holistic optimizations, such as automatic differentiation and automatic mixed precision, in training workloads. In this paper, we present RAF, a deep learning compiler for training. Unlike existing DLCs, RAF accepts a forward model and in-house generates a training graph. Accordingly, RAF is able to systematically consolidate graph optimizations for performance, memory and distributed training. In addition, to catch up to the state-of-the-art performance with hand-crafted kernel libraries as well as tensor compilers, RAF proposes an operator dialect mechanism to seamlessly integrate all possible kernel implementations. We demonstrate that by in-house training graph generation and operator dialect mechanism, we are able to perform holistic optimizations and achieve either better training throughput or larger batch size against PyTorch (eager and torchscript mode), XLA, and DeepSpeed for popular transformer models on GPUs.
Decoupled Model Schedule for Deep Learning Training
Feb 16, 2023Recent years have seen an increase in the development of large deep learning (DL) models, which makes training efficiency crucial. Common practice is struggling with the trade-off between usability and performance. On one hand, DL frameworks such as PyTorch use dynamic graphs to facilitate model developers at a price of sub-optimal model training performance. On the other hand, practitioners propose various approaches to improving the training efficiency by sacrificing some of the flexibility, ranging from making the graph static for more thorough optimization (e.g., XLA) to customizing optimization towards large-scale distributed training (e.g., DeepSpeed and Megatron-LM). In this paper, we aim to address the tension between usability and training efficiency through separation of concerns. Inspired by DL compilers that decouple the platform-specific optimizations of a tensor-level operator from its arithmetic definition, this paper proposes a schedule language to decouple model execution from definition. Specifically, the schedule works on a PyTorch model and uses a set of schedule primitives to convert the model for common model training optimizations such as high-performance kernels, effective 3D parallelism, and efficient activation checkpointing. Compared to existing optimization solutions, we optimize the model as-needed through high-level primitives, and thus preserving programmability and debuggability for users to a large extent. Our evaluation results show that by scheduling the existing hand-crafted optimizations in a systematic way, we are able to improve training throughput by up to 3.35x on a single machine with 8 NVIDIA V100 GPUs, and by up to 1.32x on multiple machines with up to 64 GPUs, when compared to the out-of-the-box performance of DeepSpeed and Megatron-LM.
Hidet: Task Mapping Programming Paradigm for Deep Learning Tensor Programs
Oct 18, 2022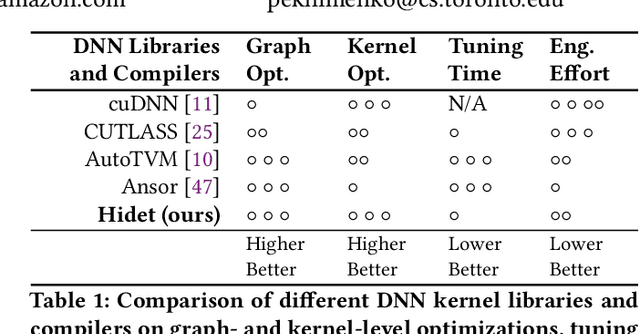
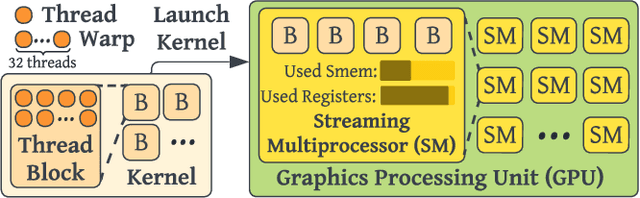

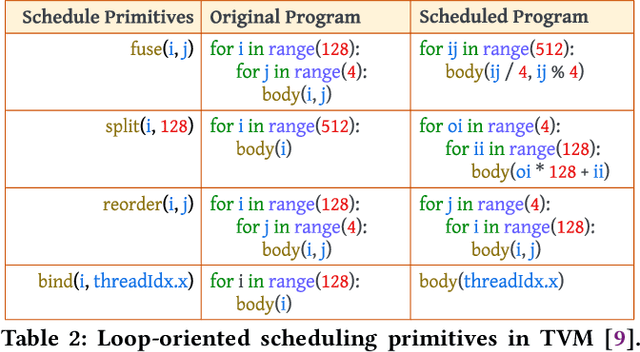
As deep learning models nowadays are widely adopted by both cloud services and edge devices, the latency of deep learning model inferences becomes crucial to provide efficient model serving. However, it is challenging to develop efficient tensor programs for deep learning operators due to the high complexity of modern accelerators (e.g., NVIDIA GPUs and Google TPUs) and the rapidly growing number of operators. Deep learning compilers, such as Apache TVM, adopt declarative scheduling primitives to lower the bar of developing tensor programs. However, we show that this approach is insufficient to cover state-of-the-art tensor program optimizations (e.g., double buffering). In this paper, we propose to embed the scheduling process into tensor programs and use dedicated mappings, called task mappings, to define the computation assignment and ordering directly in the tensor programs. This new approach greatly enriches the expressible optimizations by allowing developers to manipulate tensor programs at a much finer granularity (e.g., allowing program statement-level optimizations). We call the proposed method the task-mapping-oriented programming paradigm. With the proposed paradigm, we implement a deep learning compiler - Hidet. Extensive experiments on modern convolution and transformer models show that Hidet outperforms state-of-the-art DNN inference framework, ONNX Runtime, and compiler, TVM equipped with scheduler AutoTVM and Ansor, by up to 1.48x (1.22x on average) with enriched optimizations. It also reduces the tuning time by 20x and 11x compared with AutoTVM and Ansor, respectively.
TensorIR: An Abstraction for Automatic Tensorized Program Optimization
Jul 09, 2022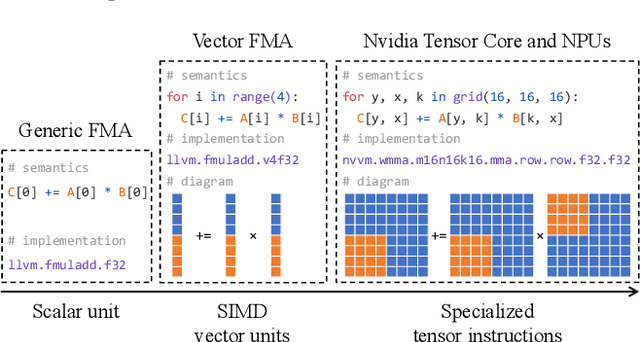

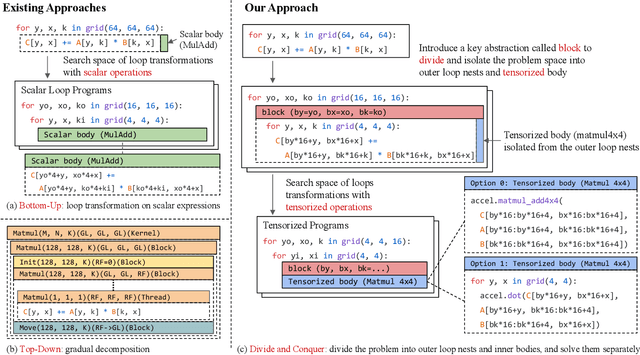
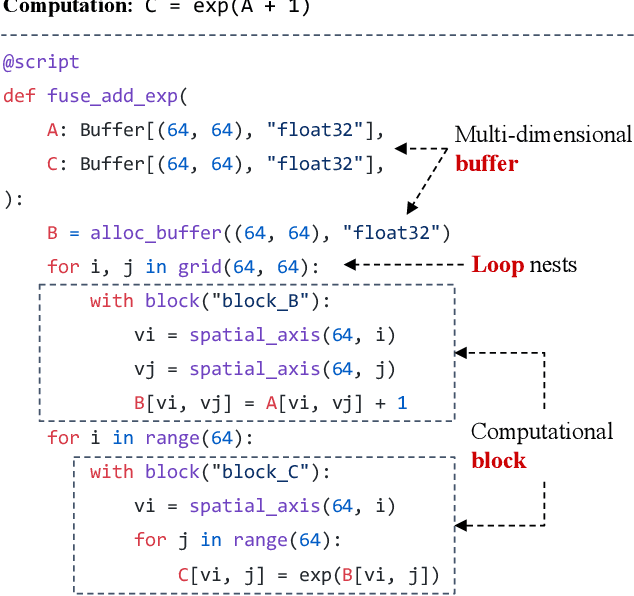
Deploying deep learning models on various devices has become an important topic. The wave of hardware specialization brings a diverse set of acceleration primitives for multi-dimensional tensor computations. These new acceleration primitives, along with the emerging machine learning models, bring tremendous engineering challenges. In this paper, we present TensorIR, a compiler abstraction for optimizing programs with these tensor computation primitives. TensorIR generalizes the loop nest representation used in existing machine learning compilers to bring tensor computation as the first-class citizen. Finally, we build an end-to-end framework on top of our abstraction to automatically optimize deep learning models for given tensor computation primitives. Experimental results show that TensorIR compilation automatically uses the tensor computation primitives for given hardware backends and delivers performance that is competitive to state-of-art hand-optimized systems across platforms.
Tensor Program Optimization with Probabilistic Programs
May 26, 2022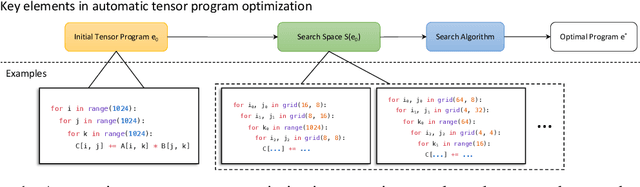

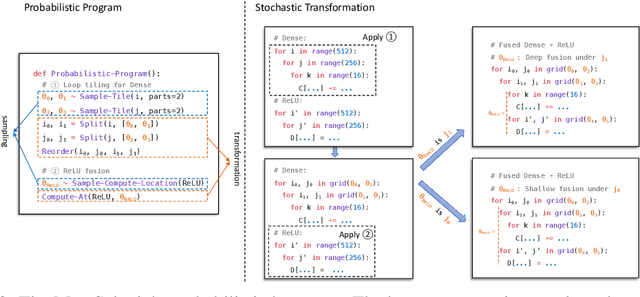
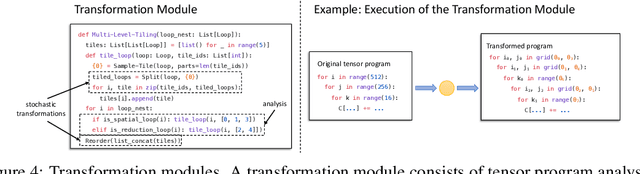
Automatic optimization for tensor programs becomes increasingly important as we deploy deep learning in various environments, and efficient optimization relies on a rich search space and effective search. Most existing efforts adopt a search space which lacks the ability to efficiently enable domain experts to grow the search space. This paper introduces MetaSchedule, a domain-specific probabilistic programming language abstraction to construct a rich search space of tensor programs. Our abstraction allows domain experts to analyze the program, and easily propose stochastic choices in a modular way to compose program transformation accordingly. We also build an end-to-end learning-driven framework to find an optimized program for a given search space. Experimental results show that MetaSchedule can cover the search space used in the state-of-the-art tensor program optimization frameworks in a modular way. Additionally, it empowers domain experts to conveniently grow the search space and modularly enhance the system, which brings 48% speedup on end-to-end deep learning workloads.
Bring Your Own Codegen to Deep Learning Compiler
May 03, 2021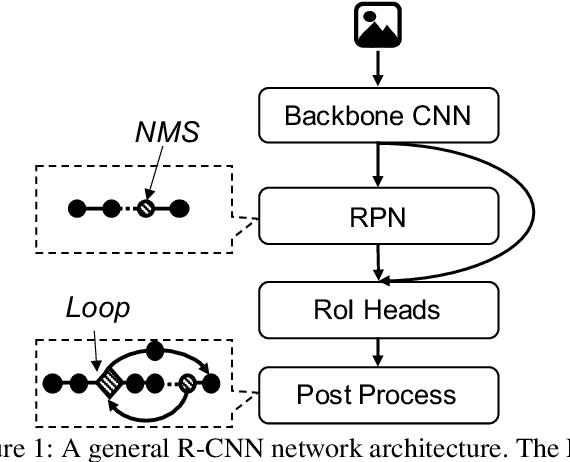
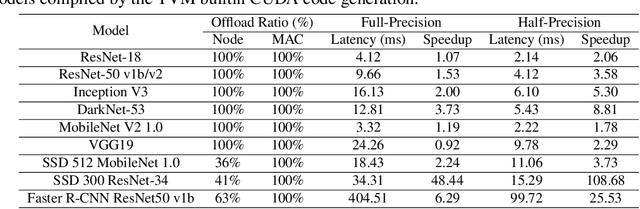

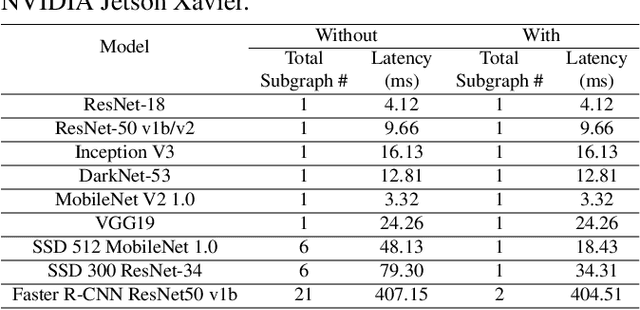
Deep neural networks (DNNs) have been ubiquitously applied in many applications, and accelerators are emerged as an enabler to support the fast and efficient inference tasks of these applications. However, to achieve high model coverage with high performance, each accelerator vendor has to develop a full compiler stack to ingest, optimize, and execute the DNNs. This poses significant challenges in the development and maintenance of the software stack. In addition, the vendors have to contiguously update their hardware and/or software to cope with the rapid evolution of the DNN model architectures and operators. To address these issues, this paper proposes an open source framework that enables users to only concentrate on the development of their proprietary code generation tools by reusing as many as possible components in the existing deep learning compilers. Our framework provides users flexible and easy-to-use interfaces to partition their models into segments that can be executed on "the best" processors to take advantage of the powerful computation capability of accelerators. Our case study shows that our framework has been deployed in multiple commercial vendors' compiler stacks with only a few thousand lines of code.
Ansor : Generating High-Performance Tensor Programs for Deep Learning
Jun 15, 2020

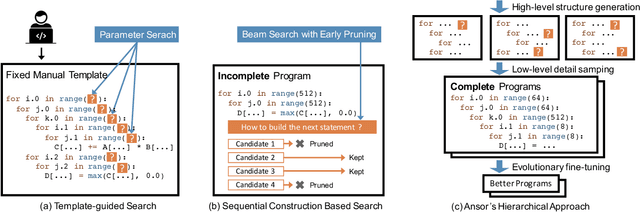
High-performance tensor programs are crucial to guarantee efficient execution of deep learning models. However, obtaining performant tensor programs for different operators on various hardware platforms is notoriously difficult. Currently, deep learning systems rely on vendor-provided kernel libraries or various search strategies to get performant tensor programs. These approaches either require significant engineering efforts in developing platform-specific optimization code or fall short in finding high-performance programs due to restricted search space and ineffective exploration strategy. We present Ansor, a tensor program generation framework for deep learning applications. Compared with existing search strategies, Ansor explores much more optimization combinations by sampling programs from a hierarchical representation of the search space. Ansor then fine-tunes the sampled programs with evolutionary search and a learned cost model to identify the best programs. Ansor can find high-performance programs that are outside the search space of existing state-of-the-art approaches. Besides, Ansor utilizes a scheduler to simultaneously optimize multiple subgraphs in a set of deep neural networks. Our evaluation shows that Ansor improves the execution performance of deep neural networks on the Intel CPU, ARM CPU, and NVIDIA GPU by up to $3.8\times$, $2.6\times$, and $1.7 \times$, respectively.