 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgedUltra: Ultra-Fast Diffusion Language Models via Reinforcement Learning
Dec 24, 2025Masked diffusion language models (MDLMs) offer the potential for parallel token generation, but most open-source MDLMs decode fewer than 5 tokens per model forward pass even with sophisticated sampling strategies. As a result, their sampling speeds are often comparable to AR + speculative decoding schemes, limiting their advantage over mainstream autoregressive approaches. Existing distillation-based accelerators (dParallel, d3LLM) finetune MDLMs on trajectories generated by a base model, which can become off-policy during finetuning and restrict performance to the quality of the base model's samples. We propose \texttt{dUltra}, an on-policy reinforcement learning framework based on Group Relative Policy Optimization (GRPO) that learns unmasking strategies for efficient parallel decoding. dUltra introduces an unmasking planner head that predicts per-token unmasking likelihoods under independent Bernoulli distributions. We jointly optimize the base diffusion LLM and the unmasking order planner using reward signals combining verifiable reward, distillation reward, and the number of unmasking steps. Across mathematical reasoning and code generation tasks, dUltra improves the accuracy--efficiency trade-off over state-of-the-art heuristic and distillation baselines, moving towards achieving ``diffusion supremacy'' over autoregressive models.
NVIDIA Nemotron 3: Efficient and Open Intelligence
Dec 24, 2025We introduce the Nemotron 3 family of models - Nano, Super, and Ultra. These models deliver strong agentic, reasoning, and conversational capabilities. The Nemotron 3 family uses a Mixture-of-Experts hybrid Mamba-Transformer architecture to provide best-in-class throughput and context lengths of up to 1M tokens. Super and Ultra models are trained with NVFP4 and incorporate LatentMoE, a novel approach that improves model quality. The two larger models also include MTP layers for faster text generation. All Nemotron 3 models are post-trained using multi-environment reinforcement learning enabling reasoning, multi-step tool use, and support granular reasoning budget control. Nano, the smallest model, outperforms comparable models in accuracy while remaining extremely cost-efficient for inference. Super is optimized for collaborative agents and high-volume workloads such as IT ticket automation. Ultra, the largest model, provides state-of-the-art accuracy and reasoning performance. Nano is released together with its technical report and this white paper, while Super and Ultra will follow in the coming months. We will openly release the model weights, pre- and post-training software, recipes, and all data for which we hold redistribution rights.
Nemotron 3 Nano: Open, Efficient Mixture-of-Experts Hybrid Mamba-Transformer Model for Agentic Reasoning
Dec 23, 2025We present Nemotron 3 Nano 30B-A3B, a Mixture-of-Experts hybrid Mamba-Transformer language model. Nemotron 3 Nano was pretrained on 25 trillion text tokens, including more than 3 trillion new unique tokens over Nemotron 2, followed by supervised fine tuning and large-scale RL on diverse environments. Nemotron 3 Nano achieves better accuracy than our previous generation Nemotron 2 Nano while activating less than half of the parameters per forward pass. It achieves up to 3.3x higher inference throughput than similarly-sized open models like GPT-OSS-20B and Qwen3-30B-A3B-Thinking-2507, while also being more accurate on popular benchmarks. Nemotron 3 Nano demonstrates enhanced agentic, reasoning, and chat abilities and supports context lengths up to 1M tokens. We release both our pretrained Nemotron 3 Nano 30B-A3B Base and post-trained Nemotron 3 Nano 30B-A3B checkpoints on Hugging Face.
Local Linear Attention: An Optimal Interpolation of Linear and Softmax Attention For Test-Time Regression
Oct 01, 2025Transformer architectures have achieved remarkable success in various domains. While efficient alternatives to Softmax Attention have been widely studied, the search for more expressive mechanisms grounded in theoretical insight-even at greater computational cost-has been relatively underexplored. In this work, we bridge this gap by proposing Local Linear Attention (LLA), a novel attention mechanism derived from nonparametric statistics through the lens of test-time regression. First, we show that LLA offers theoretical advantages over Linear and Softmax Attention for associative memory via a bias-variance trade-off analysis. Next, we address its computational challenges and propose two memory-efficient primitives to tackle the $\Theta(n^2 d)$ and $\Theta(n d^2)$ complexity. We then introduce FlashLLA, a hardware-efficient, blockwise algorithm that enables scalable and parallel computation on modern accelerators. In addition, we implement and profile a customized inference kernel that significantly reduces memory overheads. Finally, we empirically validate the advantages and limitations of LLA on test-time regression, in-context regression, associative recall and state tracking tasks. Experiment results demonstrate that LLA effectively adapts to non-stationarity, outperforming strong baselines in test-time training and in-context learning, and exhibiting promising evidence for its scalability and applicability in large-scale models. Code is available at https://github.com/Yifei-Zuo/Flash-LLA.
NVIDIA Nemotron Nano 2: An Accurate and Efficient Hybrid Mamba-Transformer Reasoning Model
Aug 21, 2025



We introduce Nemotron-Nano-9B-v2, a hybrid Mamba-Transformer language model designed to increase throughput for reasoning workloads while achieving state-of-the-art accuracy compared to similarly-sized models. Nemotron-Nano-9B-v2 builds on the Nemotron-H architecture, in which the majority of the self-attention layers in the common Transformer architecture are replaced with Mamba-2 layers, to achieve improved inference speed when generating the long thinking traces needed for reasoning. We create Nemotron-Nano-9B-v2 by first pre-training a 12-billion-parameter model (Nemotron-Nano-12B-v2-Base) on 20 trillion tokens using an FP8 training recipe. After aligning Nemotron-Nano-12B-v2-Base, we employ the Minitron strategy to compress and distill the model with the goal of enabling inference on up to 128k tokens on a single NVIDIA A10G GPU (22GiB of memory, bfloat16 precision). Compared to existing similarly-sized models (e.g., Qwen3-8B), we show that Nemotron-Nano-9B-v2 achieves on-par or better accuracy on reasoning benchmarks while achieving up to 6x higher inference throughput in reasoning settings like 8k input and 16k output tokens. We are releasing Nemotron-Nano-9B-v2, Nemotron-Nano12B-v2-Base, and Nemotron-Nano-9B-v2-Base checkpoints along with the majority of our pre- and post-training datasets on Hugging Face.
Beyond Ten Turns: Unlocking Long-Horizon Agentic Search with Large-Scale Asynchronous RL
Aug 13, 2025Recent advancements in LLM-based agents have demonstrated remarkable capabilities in handling complex, knowledge-intensive tasks by integrating external tools. Among diverse choices of tools, search tools play a pivotal role in accessing vast external knowledge. However, open-source agents still fall short of achieving expert-level Search Intelligence, the ability to resolve ambiguous queries, generate precise searches, analyze results, and conduct thorough exploration. Existing approaches fall short in scalability, efficiency, and data quality. For example, small turn limits in existing online RL methods, e.g. <=10, restrict complex strategy learning. This paper introduces ASearcher, an open-source project for large-scale RL training of search agents. Our key contributions include: (1) Scalable fully asynchronous RL training that enables long-horizon search while maintaining high training efficiency. (2) A prompt-based LLM agent that autonomously synthesizes high-quality and challenging QAs, creating a large-scale QA dataset. Through RL training, our prompt-based QwQ-32B agent achieves substantial improvements, with 46.7% and 20.8% Avg@4 gains on xBench and GAIA, respectively. Notably, our agent exhibits extreme long-horizon search, with tool calls exceeding 40 turns and output tokens exceeding 150k during training time. With a simple agent design and no external LLMs, ASearcher-Web-QwQ achieves Avg@4 scores of 42.1 on xBench and 52.8 on GAIA, surpassing existing open-source 32B agents. We open-source our models, training data, and codes in https://github.com/inclusionAI/ASearcher.
MMMG: a Comprehensive and Reliable Evaluation Suite for Multitask Multimodal Generation
May 23, 2025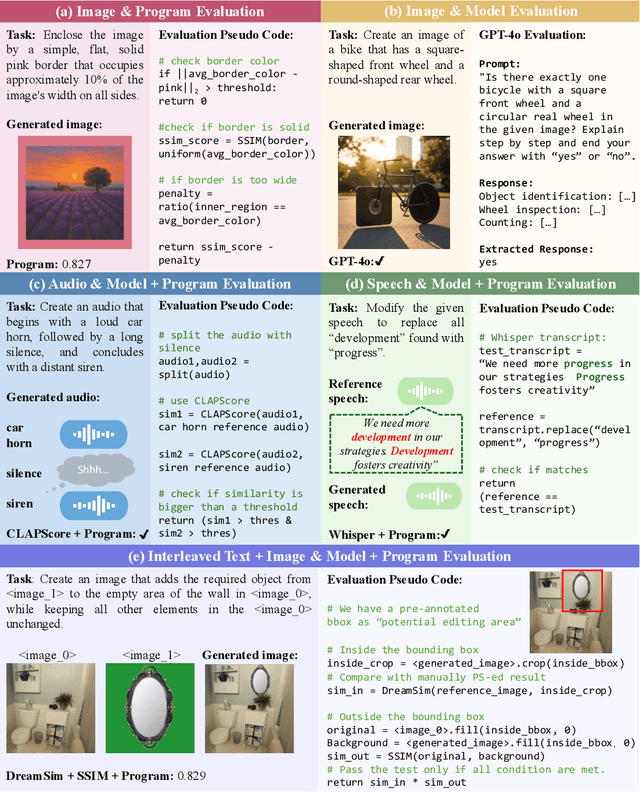
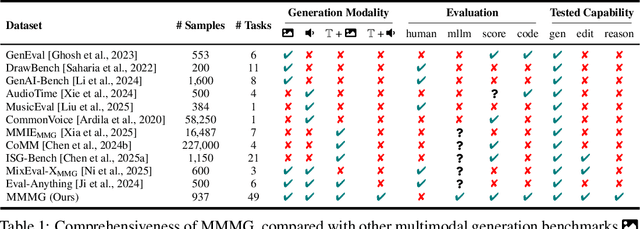
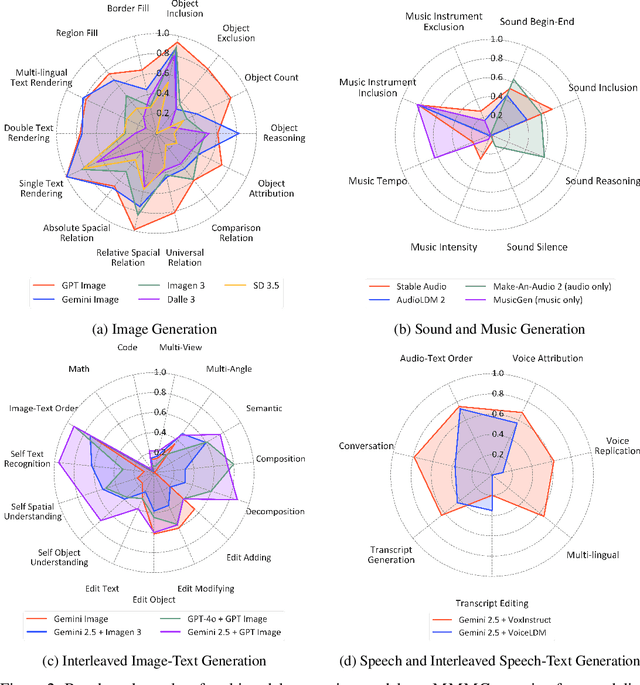
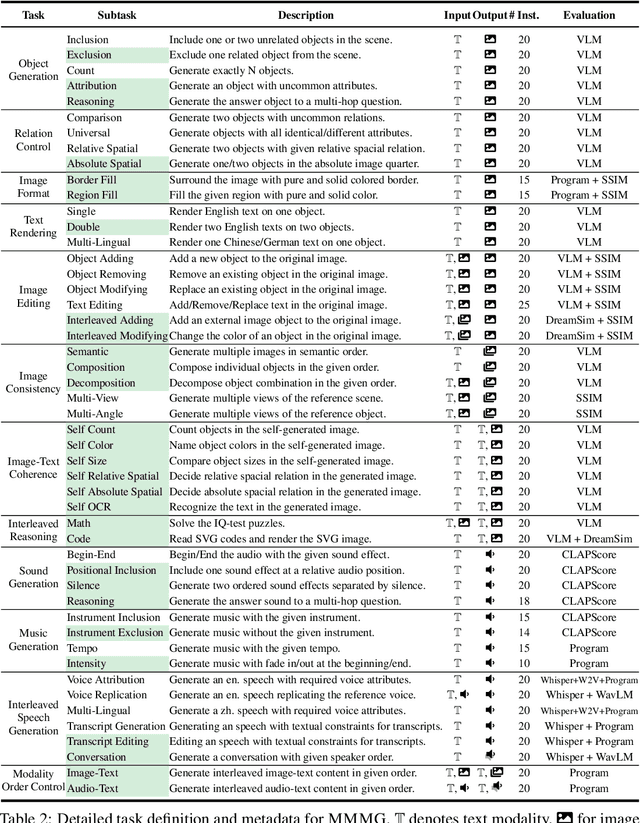
Automatically evaluating multimodal generation presents a significant challenge, as automated metrics often struggle to align reliably with human evaluation, especially for complex tasks that involve multiple modalities. To address this, we present MMMG, a comprehensive and human-aligned benchmark for multimodal generation across 4 modality combinations (image, audio, interleaved text and image, interleaved text and audio), with a focus on tasks that present significant challenges for generation models, while still enabling reliable automatic evaluation through a combination of models and programs. MMMG encompasses 49 tasks (including 29 newly developed ones), each with a carefully designed evaluation pipeline, and 937 instructions to systematically assess reasoning, controllability, and other key capabilities of multimodal generation models. Extensive validation demonstrates that MMMG is highly aligned with human evaluation, achieving an average agreement of 94.3%. Benchmarking results on 24 multimodal generation models reveal that even though the state-of-the-art model, GPT Image, achieves 78.3% accuracy for image generation, it falls short on multimodal reasoning and interleaved generation. Furthermore, results suggest considerable headroom for improvement in audio generation, highlighting an important direction for future research.
How to Evaluate Reward Models for RLHF
Oct 18, 2024



We introduce a new benchmark for reward models that quantifies their ability to produce strong language models through RLHF (Reinforcement Learning from Human Feedback). The gold-standard approach is to run a full RLHF training pipeline and directly probe downstream LLM performance. However, this process is prohibitively expensive. To address this, we build a predictive model of downstream LLM performance by evaluating the reward model on proxy tasks. These proxy tasks consist of a large-scale human preference and a verifiable correctness preference dataset, in which we measure 12 metrics across 12 domains. To investigate which reward model metrics are most correlated to gold-standard RLHF outcomes, we launch an end-to-end RLHF experiment on a large-scale crowdsourced human preference platform to view real reward model downstream performance as ground truth. Ultimately, we compile our data and findings into Preference Proxy Evaluations (PPE), the first reward model benchmark explicitly linked to post-RLHF real-world human preference performance, which we open-source for public use and further development. Our code and evaluations can be found at https://github.com/lmarena/PPE .
Taming Overconfidence in LLMs: Reward Calibration in RLHF
Oct 13, 2024



Language model calibration refers to the alignment between the confidence of the model and the actual performance of its responses. While previous studies point out the overconfidence phenomenon in Large Language Models (LLMs) and show that LLMs trained with Reinforcement Learning from Human Feedback (RLHF) are overconfident with a more sharpened output probability, in this study, we reveal that RLHF tends to lead models to express verbalized overconfidence in their own responses. We investigate the underlying cause of this overconfidence and demonstrate that reward models used for Proximal Policy Optimization (PPO) exhibit inherent biases towards high-confidence scores regardless of the actual quality of responses. Building upon this insight, we propose two PPO variants: PPO-M: PPO with Calibrated Reward Modeling and PPO-C: PPO with Calibrated Reward Calculation. PPO-M integrates explicit confidence scores in reward model training, which calibrates reward models to better capture the alignment between response quality and verbalized confidence. PPO-C adjusts the reward score during PPO based on the difference between the current reward and the moving average of past rewards. Both PPO-M and PPO-C can be seamlessly integrated into the current PPO pipeline and do not require additional golden labels. We evaluate our methods on both Llama3-8B and Mistral-7B across six diverse datasets including multiple-choice and open-ended generation. Experiment results demonstrate that both of our methods can reduce calibration error and maintain performance comparable to standard PPO. We further show that they do not compromise model capabilities in open-ended conversation settings.
From Crowdsourced Data to High-Quality Benchmarks: Arena-Hard and BenchBuilder Pipeline
Jun 17, 2024



The rapid evolution of language models has necessitated the development of more challenging benchmarks. Current static benchmarks often struggle to consistently distinguish between the capabilities of different models and fail to align with real-world user preferences. On the other hand, live crowd-sourced platforms like the Chatbot Arena collect a wide range of natural prompts and user feedback. However, these prompts vary in sophistication and the feedback cannot be applied offline to new models. In order to ensure that benchmarks keep up with the pace of LLM development, we address how one can evaluate benchmarks on their ability to confidently separate models and their alignment with human preference. Under these principles, we developed BenchBuilder, a living benchmark that filters high-quality prompts from live data sources to enable offline evaluation on fresh, challenging prompts. BenchBuilder identifies seven indicators of a high-quality prompt, such as the requirement for domain knowledge, and utilizes an LLM annotator to select a high-quality subset of prompts from various topic clusters. The LLM evaluation process employs an LLM judge to ensure a fully automated, high-quality, and constantly updating benchmark. We apply BenchBuilder on prompts from the Chatbot Arena to create Arena-Hard-Auto v0.1: 500 challenging user prompts from a wide range of tasks. Arena-Hard-Auto v0.1 offers 3x tighter confidence intervals than MT-Bench and achieves a state-of-the-art 89.1% agreement with human preference rankings, all at a cost of only $25 and without human labelers. The BenchBuilder pipeline enhances evaluation benchmarks and provides a valuable tool for developers, enabling them to extract high-quality benchmarks from extensive data with minimal effort.