 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMachine Learning-based Methods for Reconfigurable Antenna Mode Selection in MIMO Systems
Nov 24, 2022



MIMO technology has enabled spatial multiple access and has provided a higher system spectral efficiency (SE). However, this technology has some drawbacks, such as the high number of RF chains that increases complexity in the system. One of the solutions to this problem can be to employ reconfigurable antennas (RAs) that can support different radiation patterns during transmission to provide similar performance with fewer RF chains. In this regard, the system aims to maximize the SE with respect to optimum beamforming design and RA mode selection. Due to the non-convexity of this problem, we propose machine learning-based methods for RA antenna mode selection in both dynamic and static scenarios. In the static scenario, we present how to solve the RA mode selection problem, an integer optimization problem in nature, via deep convolutional neural networks (DCNN). A Multi-Armed-bandit (MAB) consisting of offline and online training is employed for the dynamic RA state selection. For the proposed MAB, the computational complexity of the optimization problem is reduced. Finally, the proposed methods in both dynamic and static scenarios are compared with exhaustive search and random selection methods.
MIMO Systems with Reconfigurable Antennas: Joint Channel Estimation and Mode Selection
Nov 24, 2022Reconfigurable antennas (RAs) are a promising technology to enhance the capacity and coverage of wireless communication systems. However, RA systems have two major challenges: (i) High computational complexity of mode selection, and (ii) High overhead of channel estimation for all modes. In this paper, we develop a low-complexity iterative mode selection algorithm for data transmission in an RA-MIMO system. Furthermore, we study channel estimation of an RA multi-user MIMO system. However, given the coherence time, it is challenging to estimate channels of all modes. We propose a mode selection scheme to select a subset of modes, train channels for the selected subset, and predict channels for the remaining modes. In addition, we propose a prediction scheme based on pattern correlation between modes. Representative simulation results demonstrate the system's channel estimation error and achievable sum-rate for various selected modes and different signal-to-noise ratios (SNRs).
Deep Factorization Model for Robust Recommendation
Nov 05, 2022Recently, malevolent user hacking has become a huge problem for real-world companies. In order to learn predictive models for recommender systems, factorization techniques have been developed to deal with user-item ratings. In this paper, we suggest a broad architecture of a factorization model with adversarial training to get over these issues. The effectiveness of our systems is demonstrated by experimental findings on real-world datasets.
CAMO-MOT: Combined Appearance-Motion Optimization for 3D Multi-Object Tracking with Camera-LiDAR Fusion
Sep 12, 2022
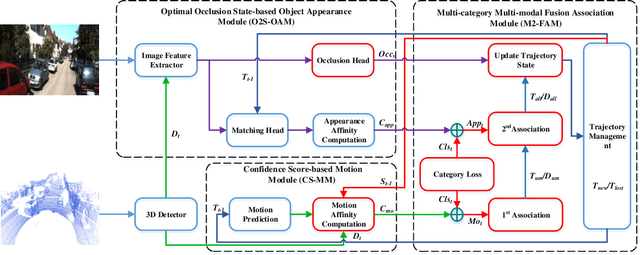
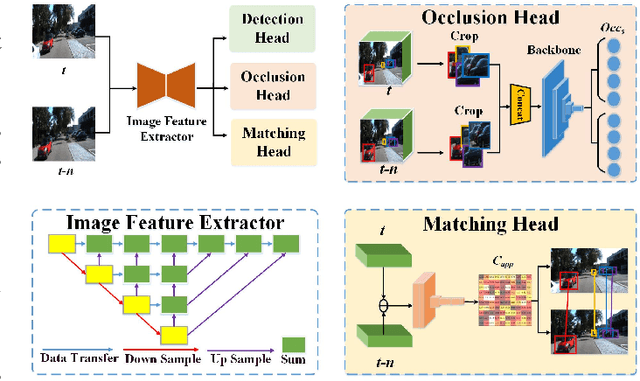
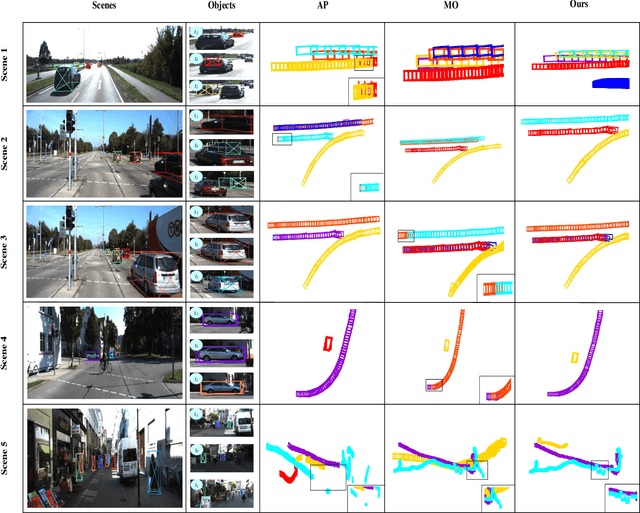
3D Multi-object tracking (MOT) ensures consistency during continuous dynamic detection, conducive to subsequent motion planning and navigation tasks in autonomous driving. However, camera-based methods suffer in the case of occlusions and it can be challenging to accurately track the irregular motion of objects for LiDAR-based methods. Some fusion methods work well but do not consider the untrustworthy issue of appearance features under occlusion. At the same time, the false detection problem also significantly affects tracking. As such, we propose a novel camera-LiDAR fusion 3D MOT framework based on the Combined Appearance-Motion Optimization (CAMO-MOT), which uses both camera and LiDAR data and significantly reduces tracking failures caused by occlusion and false detection. For occlusion problems, we are the first to propose an occlusion head to select the best object appearance features multiple times effectively, reducing the influence of occlusions. To decrease the impact of false detection in tracking, we design a motion cost matrix based on confidence scores which improve the positioning and object prediction accuracy in 3D space. As existing multi-object tracking methods only consider a single category, we also propose to build a multi-category loss to implement multi-object tracking in multi-category scenes. A series of validation experiments are conducted on the KITTI and nuScenes tracking benchmarks. Our proposed method achieves state-of-the-art performance and the lowest identity switches (IDS) value (23 for Car and 137 for Pedestrian) among all multi-modal MOT methods on the KITTI test dataset. And our proposed method achieves state-of-the-art performance among all algorithms on the nuScenes test dataset with 75.3% AMOTA.
Private, Efficient, and Accurate: Protecting Models Trained by Multi-party Learning with Differential Privacy
Aug 18, 2022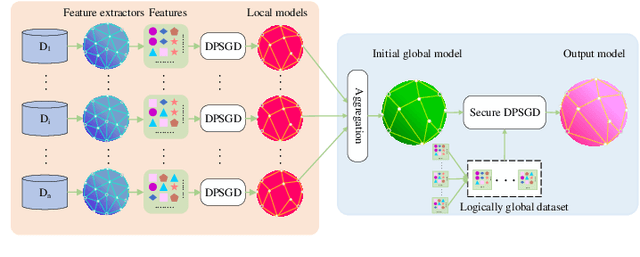
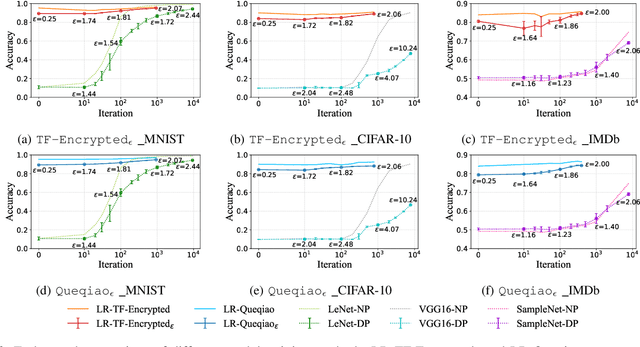
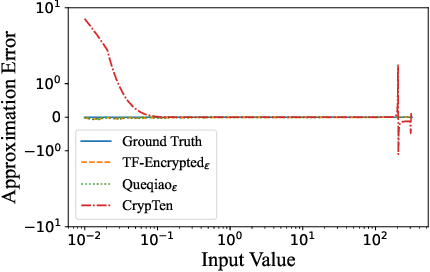
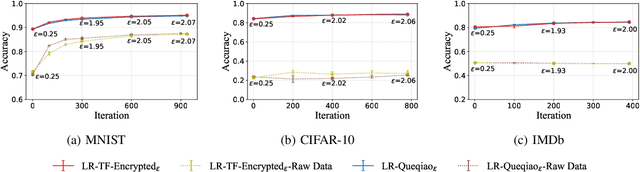
Secure multi-party computation-based machine learning, referred to as MPL, has become an important technology to utilize data from multiple parties with privacy preservation. While MPL provides rigorous security guarantees for the computation process, the models trained by MPL are still vulnerable to attacks that solely depend on access to the models. Differential privacy could help to defend against such attacks. However, the accuracy loss brought by differential privacy and the huge communication overhead of secure multi-party computation protocols make it highly challenging to balance the 3-way trade-off between privacy, efficiency, and accuracy. In this paper, we are motivated to resolve the above issue by proposing a solution, referred to as PEA (Private, Efficient, Accurate), which consists of a secure DPSGD protocol and two optimization methods. First, we propose a secure DPSGD protocol to enforce DPSGD in secret sharing-based MPL frameworks. Second, to reduce the accuracy loss led by differential privacy noise and the huge communication overhead of MPL, we propose two optimization methods for the training process of MPL: (1) the data-independent feature extraction method, which aims to simplify the trained model structure; (2) the local data-based global model initialization method, which aims to speed up the convergence of the model training. We implement PEA in two open-source MPL frameworks: TF-Encrypted and Queqiao. The experimental results on various datasets demonstrate the efficiency and effectiveness of PEA. E.g. when ${\epsilon}$ = 2, we can train a differentially private classification model with an accuracy of 88% for CIFAR-10 within 7 minutes under the LAN setting. This result significantly outperforms the one from CryptGPU, one SOTA MPL framework: it costs more than 16 hours to train a non-private deep neural network model on CIFAR-10 with the same accuracy.
Scalable and Sparsity-Aware Privacy-Preserving K-means Clustering with Application to Fraud Detection
Aug 12, 2022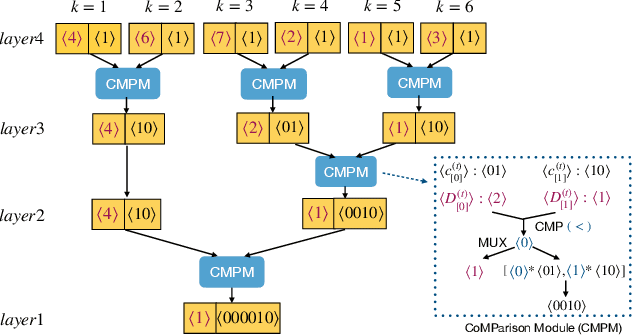
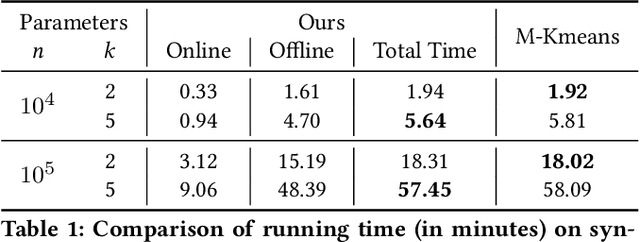
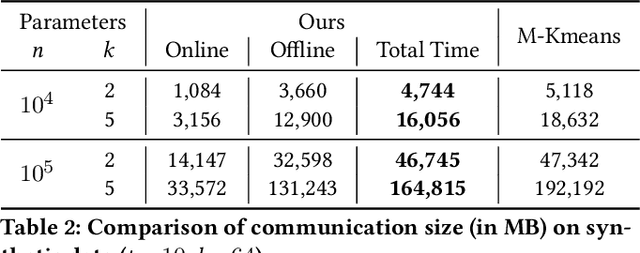
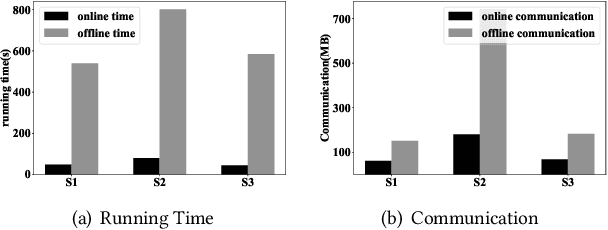
K-means is one of the most widely used clustering models in practice. Due to the problem of data isolation and the requirement for high model performance, how to jointly build practical and secure K-means for multiple parties has become an important topic for many applications in the industry. Existing work on this is mainly of two types. The first type has efficiency advantages, but information leakage raises potential privacy risks. The second type is provable secure but is inefficient and even helpless for the large-scale data sparsity scenario. In this paper, we propose a new framework for efficient sparsity-aware K-means with three characteristics. First, our framework is divided into a data-independent offline phase and a much faster online phase, and the offline phase allows to pre-compute almost all cryptographic operations. Second, we take advantage of the vectorization techniques in both online and offline phases. Third, we adopt a sparse matrix multiplication for the data sparsity scenario to improve efficiency further. We conduct comprehensive experiments on three synthetic datasets and deploy our model in a real-world fraud detection task. Our experimental results show that, compared with the state-of-the-art solution, our model achieves competitive performance in terms of both running time and communication size, especially on sparse datasets.
Longitudinal Prediction of Postnatal Brain Magnetic Resonance Images via a Metamorphic Generative Adversarial Network
Aug 09, 2022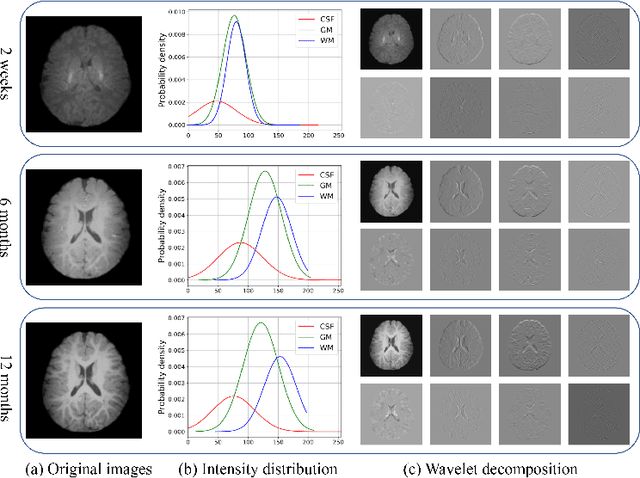
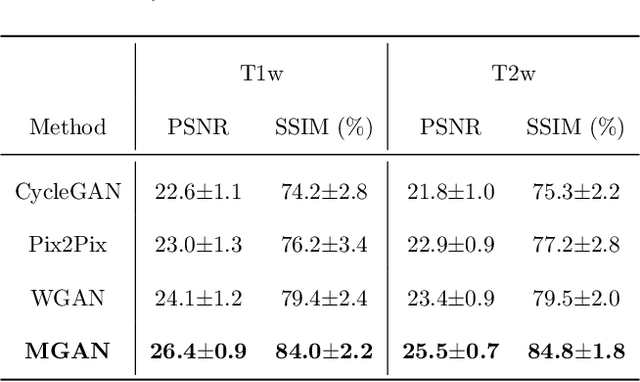
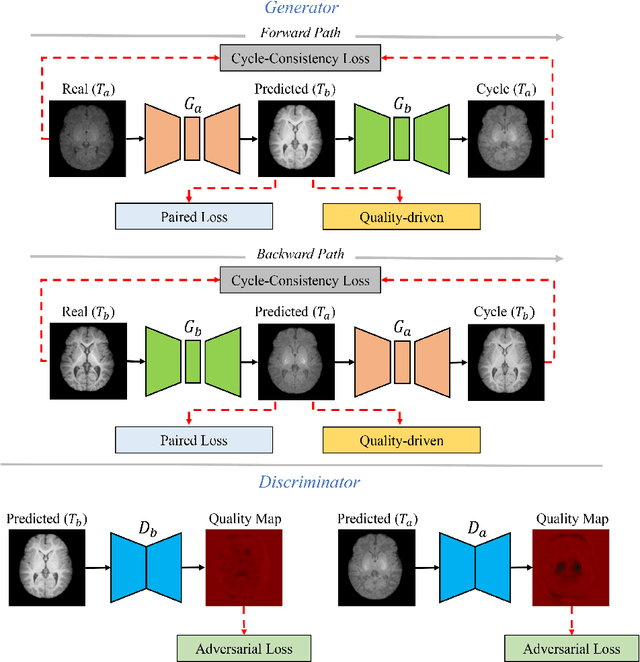
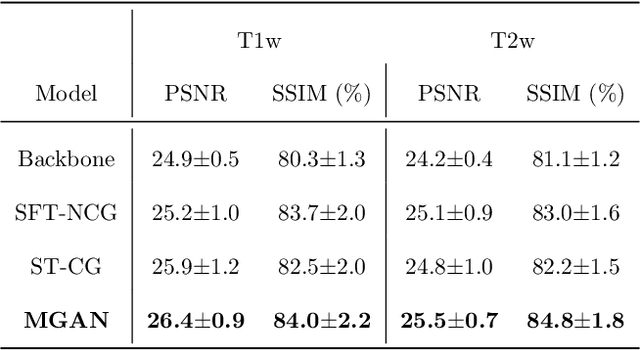
Missing scans are inevitable in longitudinal studies due to either subject dropouts or failed scans. In this paper, we propose a deep learning framework to predict missing scans from acquired scans, catering to longitudinal infant studies. Prediction of infant brain MRI is challenging owing to the rapid contrast and structural changes particularly during the first year of life. We introduce a trustworthy metamorphic generative adversarial network (MGAN) for translating infant brain MRI from one time-point to another. MGAN has three key features: (i) Image translation leveraging spatial and frequency information for detail-preserving mapping; (ii) Quality-guided learning strategy that focuses attention on challenging regions. (iii) Multi-scale hybrid loss function that improves translation of tissue contrast and structural details. Experimental results indicate that MGAN outperforms existing GANs by accurately predicting both contrast and anatomical details.
Deep Uncalibrated Photometric Stereo via Inter-Intra Image Feature Fusion
Aug 06, 2022
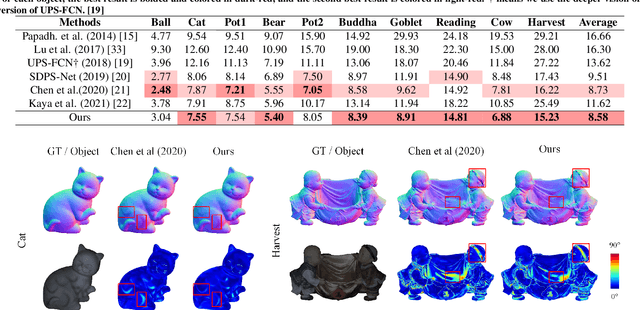
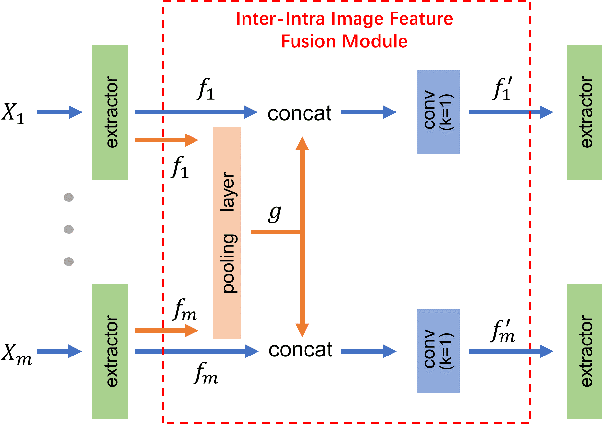
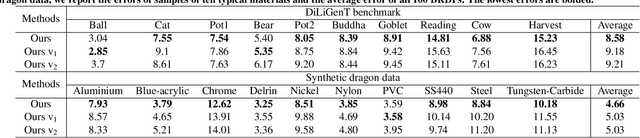
Uncalibrated photometric stereo is proposed to estimate the detailed surface normal from images under varying and unknown lightings. Recently, deep learning brings powerful data priors to this underdetermined problem. This paper presents a new method for deep uncalibrated photometric stereo, which efficiently utilizes the inter-image representation to guide the normal estimation. Previous methods use optimization-based neural inverse rendering or a single size-independent pooling layer to deal with multiple inputs, which are inefficient for utilizing information among input images. Given multi-images under different lighting, we consider the intra-image and inter-image variations highly correlated. Motivated by the correlated variations, we designed an inter-intra image feature fusion module to introduce the inter-image representation into the per-image feature extraction. The extra representation is used to guide the per-image feature extraction and eliminate the ambiguity in normal estimation. We demonstrate the effect of our design on a wide range of samples, especially on dark materials. Our method produces significantly better results than the state-of-the-art methods on both synthetic and real data.
Convolutional Embedding Makes Hierarchical Vision Transformer Stronger
Aug 01, 2022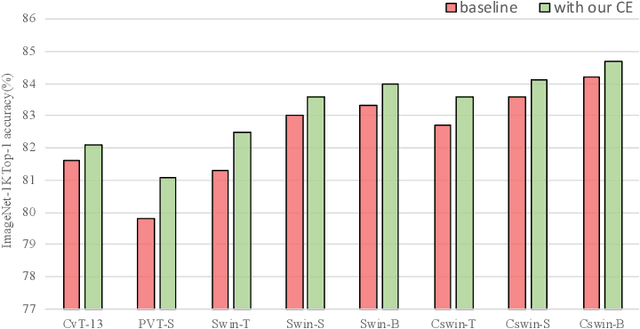
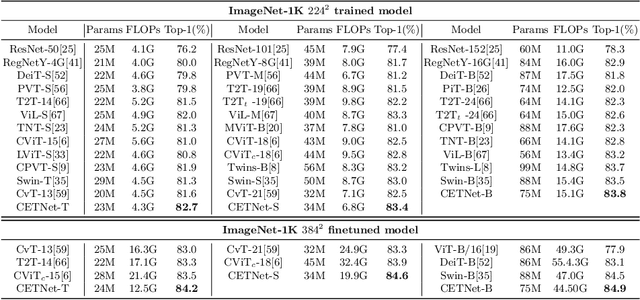
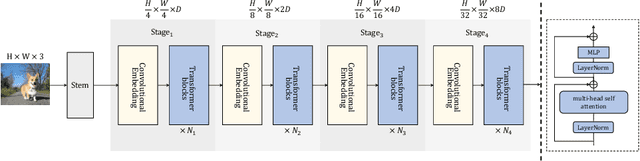
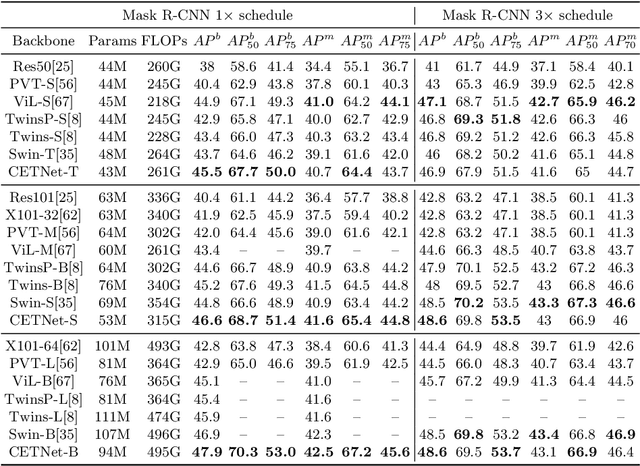
Vision Transformers (ViTs) have recently dominated a range of computer vision tasks, yet it suffers from low training data efficiency and inferior local semantic representation capability without appropriate inductive bias. Convolutional neural networks (CNNs) inherently capture regional-aware semantics, inspiring researchers to introduce CNNs back into the architecture of the ViTs to provide desirable inductive bias for ViTs. However, is the locality achieved by the micro-level CNNs embedded in ViTs good enough? In this paper, we investigate the problem by profoundly exploring how the macro architecture of the hybrid CNNs/ViTs enhances the performances of hierarchical ViTs. Particularly, we study the role of token embedding layers, alias convolutional embedding (CE), and systemically reveal how CE injects desirable inductive bias in ViTs. Besides, we apply the optimal CE configuration to 4 recently released state-of-the-art ViTs, effectively boosting the corresponding performances. Finally, a family of efficient hybrid CNNs/ViTs, dubbed CETNets, are released, which may serve as generic vision backbones. Specifically, CETNets achieve 84.9% Top-1 accuracy on ImageNet-1K (training from scratch), 48.6% box mAP on the COCO benchmark, and 51.6% mIoU on the ADE20K, substantially improving the performances of the corresponding state-of-the-art baselines.
Intelligent Amphibious Ground-Aerial Vehicles: State of the Art Technology for Future Transportation
Jul 23, 2022



Amphibious ground-aerial vehicles fuse flying and driving modes to enable more flexible air-land mobility and have received growing attention recently. By analyzing the existing amphibious vehicles, we highlight the autonomous fly-driving functionality for the effective uses of amphibious vehicles in complex three-dimensional urban transportation systems. We review and summarize the key enabling technologies for intelligent flying-driving in existing amphibious vehicle designs, identify major technological barriers and propose potential solutions for future research and innovation. This paper aims to serve as a guide for research and development of intelligent amphibious vehicles for urban transportation toward the future.