 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplainable Semantic Federated Learning Enabled Industrial Edge Network for Fire Surveillance
Dec 28, 2024In fire surveillance, Industrial Internet of Things (IIoT) devices require transmitting large monitoring data frequently, which leads to huge consumption of spectrum resources. Hence, we propose an Industrial Edge Semantic Network (IESN) to allow IIoT devices to send warnings through Semantic communication (SC). Thus, we should consider (1) Data privacy and security. (2) SC model adaptation for heterogeneous devices. (3) Explainability of semantics. Therefore, first, we present an eXplainable Semantic Federated Learning (XSFL) to train the SC model, thus ensuring data privacy and security. Then, we present an Adaptive Client Training (ACT) strategy to provide a specific SC model for each device according to its Fisher information matrix, thus overcoming the heterogeneity. Next, an Explainable SC (ESC) mechanism is designed, which introduces a leakyReLU-based activation mapping to explain the relationship between the extracted semantics and monitoring data. Finally, simulation results demonstrate the effectiveness of XSFL.
* 9 pages
Multimodal Latent Language Modeling with Next-Token Diffusion
Dec 11, 2024



Multimodal generative models require a unified approach to handle both discrete data (e.g., text and code) and continuous data (e.g., image, audio, video). In this work, we propose Latent Language Modeling (LatentLM), which seamlessly integrates continuous and discrete data using causal Transformers. Specifically, we employ a variational autoencoder (VAE) to represent continuous data as latent vectors and introduce next-token diffusion for autoregressive generation of these vectors. Additionally, we develop $\sigma$-VAE to address the challenges of variance collapse, which is crucial for autoregressive modeling. Extensive experiments demonstrate the effectiveness of LatentLM across various modalities. In image generation, LatentLM surpasses Diffusion Transformers in both performance and scalability. When integrated into multimodal large language models, LatentLM provides a general-purpose interface that unifies multimodal generation and understanding. Experimental results show that LatentLM achieves favorable performance compared to Transfusion and vector quantized models in the setting of scaling up training tokens. In text-to-speech synthesis, LatentLM outperforms the state-of-the-art VALL-E 2 model in speaker similarity and robustness, while requiring 10x fewer decoding steps. The results establish LatentLM as a highly effective and scalable approach to advance large multimodal models.
MoE-CAP: Cost-Accuracy-Performance Benchmarking for Mixture-of-Experts Systems
Dec 10, 2024The sparse Mixture-of-Experts (MoE) architecture is increasingly favored for scaling Large Language Models (LLMs) efficiently; however, MoE systems rely on heterogeneous compute and memory resources. These factors collectively influence the system's Cost, Accuracy, and Performance (CAP), creating a challenging trade-off. Current benchmarks often fail to provide precise estimates of these effects, complicating practical considerations for deploying MoE systems. To bridge this gap, we introduce MoE-CAP, a benchmark specifically designed to evaluate MoE systems. Our findings highlight the difficulty of achieving an optimal balance of cost, accuracy, and performance with existing hardware capabilities. MoE systems often necessitate compromises on one factor to optimize the other two, a dynamic we term the MoE-CAP trade-off. To identify the best trade-off, we propose novel performance evaluation metrics - Sparse Memory Bandwidth Utilization (S-MBU) and Sparse Model FLOPS Utilization (S-MFU) - and develop cost models that account for the heterogeneous compute and memory hardware integral to MoE systems. This benchmark is publicly available on HuggingFace: https://huggingface.co/spaces/sparse-generative-ai/open-moe-llm-leaderboard.
RedStone: Curating General, Code, Math, and QA Data for Large Language Models
Dec 04, 2024
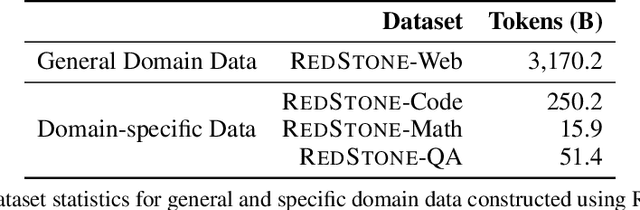
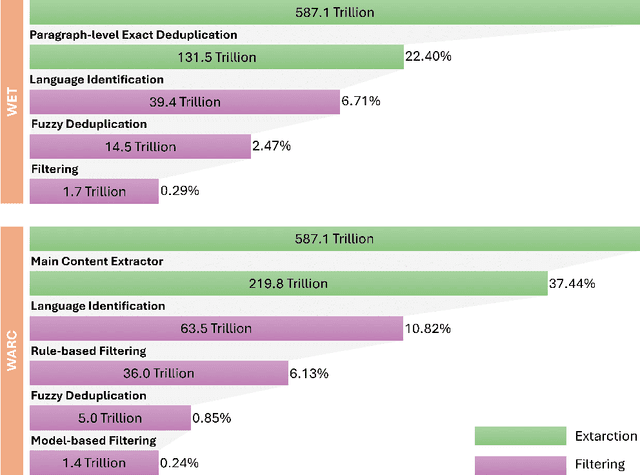
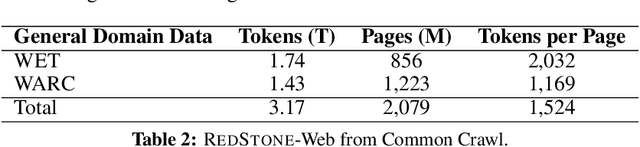
Pre-training Large Language Models (LLMs) on high-quality, meticulously curated datasets is widely recognized as critical for enhancing their performance and generalization capabilities. This study explores the untapped potential of Common Crawl as a comprehensive and flexible resource for pre-training LLMs, addressing both general-purpose language understanding and specialized domain knowledge. We introduce RedStone, an innovative and scalable pipeline engineered to extract and process data from Common Crawl, facilitating the creation of extensive and varied pre-training datasets. Unlike traditional datasets, which often require expensive curation and domain-specific expertise, RedStone leverages the breadth of Common Crawl to deliver datasets tailored to a wide array of domains. In this work, we exemplify its capability by constructing pre-training datasets across multiple fields, including general language understanding, code, mathematics, and question-answering tasks. The flexibility of RedStone allows for easy adaptation to other specialized domains, significantly lowering the barrier to creating valuable domain-specific datasets. Our findings demonstrate that Common Crawl, when harnessed through effective pipelines like RedStone, can serve as a rich, renewable source of pre-training data, unlocking new avenues for domain adaptation and knowledge discovery in LLMs. This work also underscores the importance of innovative data acquisition strategies and highlights the role of web-scale data as a powerful resource in the continued evolution of LLMs. RedStone code and data samples will be publicly available at \url{https://aka.ms/redstone}.
Large Generative Model-assisted Talking-face Semantic Communication System
Nov 06, 2024



The rapid development of generative Artificial Intelligence (AI) continually unveils the potential of Semantic Communication (SemCom). However, current talking-face SemCom systems still encounter challenges such as low bandwidth utilization, semantic ambiguity, and diminished Quality of Experience (QoE). This study introduces a Large Generative Model-assisted Talking-face Semantic Communication (LGM-TSC) System tailored for the talking-face video communication. Firstly, we introduce a Generative Semantic Extractor (GSE) at the transmitter based on the FunASR model to convert semantically sparse talking-face videos into texts with high information density. Secondly, we establish a private Knowledge Base (KB) based on the Large Language Model (LLM) for semantic disambiguation and correction, complemented by a joint knowledge base-semantic-channel coding scheme. Finally, at the receiver, we propose a Generative Semantic Reconstructor (GSR) that utilizes BERT-VITS2 and SadTalker models to transform text back into a high-QoE talking-face video matching the user's timbre. Simulation results demonstrate the feasibility and effectiveness of the proposed LGM-TSC system.
Deferred Poisoning: Making the Model More Vulnerable via Hessian Singularization
Nov 06, 2024Recent studies have shown that deep learning models are very vulnerable to poisoning attacks. Many defense methods have been proposed to address this issue. However, traditional poisoning attacks are not as threatening as commonly believed. This is because they often cause differences in how the model performs on the training set compared to the validation set. Such inconsistency can alert defenders that their data has been poisoned, allowing them to take the necessary defensive actions. In this paper, we introduce a more threatening type of poisoning attack called the Deferred Poisoning Attack. This new attack allows the model to function normally during the training and validation phases but makes it very sensitive to evasion attacks or even natural noise. We achieve this by ensuring the poisoned model's loss function has a similar value as a normally trained model at each input sample but with a large local curvature. A similar model loss ensures that there is no obvious inconsistency between the training and validation accuracy, demonstrating high stealthiness. On the other hand, the large curvature implies that a small perturbation may cause a significant increase in model loss, leading to substantial performance degradation, which reflects a worse robustness. We fulfill this purpose by making the model have singular Hessian information at the optimal point via our proposed Singularization Regularization term. We have conducted both theoretical and empirical analyses of the proposed method and validated its effectiveness through experiments on image classification tasks. Furthermore, we have confirmed the hazards of this form of poisoning attack under more general scenarios using natural noise, offering a new perspective for research in the field of security.
GAI-Enabled Explainable Personalized Federated Semi-Supervised Learning
Oct 11, 2024



Federated learning (FL) is a commonly distributed algorithm for mobile users (MUs) training artificial intelligence (AI) models, however, several challenges arise when applying FL to real-world scenarios, such as label scarcity, non-IID data, and unexplainability. As a result, we propose an explainable personalized FL framework, called XPFL. First, we introduce a generative AI (GAI) assisted personalized federated semi-supervised learning, called GFed. Particularly, in local training, we utilize a GAI model to learn from large unlabeled data and apply knowledge distillation-based semi-supervised learning to train the local FL model using the knowledge acquired from the GAI model. In global aggregation, we obtain the new local FL model by fusing the local and global FL models in specific proportions, allowing each local model to incorporate knowledge from others while preserving its personalized characteristics. Second, we propose an explainable AI mechanism for FL, named XFed. Specifically, in local training, we apply a decision tree to match the input and output of the local FL model. In global aggregation, we utilize t-distributed stochastic neighbor embedding (t-SNE) to visualize the local models before and after aggregation. Finally, simulation results validate the effectiveness of the proposed XPFL framework.
Self-Boosting Large Language Models with Synthetic Preference Data
Oct 09, 2024



Through alignment with human preferences, Large Language Models (LLMs) have advanced significantly in generating honest, harmless, and helpful responses. However, collecting high-quality preference data is a resource-intensive and creativity-demanding process, especially for the continual improvement of LLMs. We introduce SynPO, a self-boosting paradigm that leverages synthetic preference data for model alignment. SynPO employs an iterative mechanism wherein a self-prompt generator creates diverse prompts, and a response improver refines model responses progressively. This approach trains LLMs to autonomously learn the generative rewards for their own outputs and eliminates the need for large-scale annotation of prompts and human preferences. After four SynPO iterations, Llama3-8B and Mistral-7B show significant enhancements in instruction-following abilities, achieving over 22.1% win rate improvements on AlpacaEval 2.0 and ArenaHard. Simultaneously, SynPO improves the general performance of LLMs on various tasks, validated by a 3.2 to 5.0 average score increase on the well-recognized Open LLM leaderboard.
Data Selection via Optimal Control for Language Models
Oct 09, 2024



This work investigates the selection of high-quality pre-training data from massive corpora to enhance LMs' capabilities for downstream usage. We formulate data selection as a generalized Optimal Control problem, which can be solved theoretically by Pontryagin's Maximum Principle (PMP), yielding a set of necessary conditions that characterize the relationship between optimal data selection and LM training dynamics. Based on these theoretical results, we introduce PMP-based Data Selection (PDS), a framework that approximates optimal data selection by solving the PMP conditions. In our experiments, we adopt PDS to select data from CommmonCrawl and show that the PDS-selected corpus accelerates the learning of LMs and constantly boosts their performance on a wide range of downstream tasks across various model sizes. Moreover, the benefits of PDS extend to ~400B models trained on ~10T tokens, as evidenced by the extrapolation of the test loss curves according to the Scaling Laws. PDS also improves data utilization when the pre-training data is limited, by reducing the data demand by 1.8 times, which mitigates the quick exhaustion of available web-crawled corpora. Our code, data, and model checkpoints can be found in https://github.com/microsoft/LMOps/tree/main/data_selection.
Differential Transformer
Oct 07, 2024



Transformer tends to overallocate attention to irrelevant context. In this work, we introduce Diff Transformer, which amplifies attention to the relevant context while canceling noise. Specifically, the differential attention mechanism calculates attention scores as the difference between two separate softmax attention maps. The subtraction cancels noise, promoting the emergence of sparse attention patterns. Experimental results on language modeling show that Diff Transformer outperforms Transformer in various settings of scaling up model size and training tokens. More intriguingly, it offers notable advantages in practical applications, such as long-context modeling, key information retrieval, hallucination mitigation, in-context learning, and reduction of activation outliers. By being less distracted by irrelevant context, Diff Transformer can mitigate hallucination in question answering and text summarization. For in-context learning, Diff Transformer not only enhances accuracy but is also more robust to order permutation, which was considered as a chronic robustness issue. The results position Diff Transformer as a highly effective and promising architecture to advance large language models.