 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Pilot Empirical Study on When and How to Use Knowledge Graphs as Retrieval Augmented Generation
Feb 28, 2025The integration of Knowledge Graphs (KGs) into the Retrieval Augmented Generation (RAG) framework has attracted significant interest, with early studies showing promise in mitigating hallucinations and improving model accuracy. However, a systematic understanding and comparative analysis of the rapidly emerging KG-RAG methods are still lacking. This paper seeks to lay the foundation for systematically answering the question of when and how to use KG-RAG by analyzing their performance in various application scenarios associated with different technical configurations. After outlining the mind map using KG-RAG framework and summarizing its popular pipeline, we conduct a pilot empirical study of KG-RAG works to reimplement and evaluate 6 KG-RAG methods across 7 datasets in diverse scenarios, analyzing the impact of 9 KG-RAG configurations in combination with 17 LLMs. Our results underscore the critical role of appropriate application conditions and optimal configurations of KG-RAG components.
Activation-aware Probe-Query: Effective Key-Value Retrieval for Long-Context LLMs Inference
Feb 19, 2025Recent advances in large language models (LLMs) have showcased exceptional performance in long-context tasks, while facing significant inference efficiency challenges with limited GPU memory. Existing solutions first proposed the sliding-window approach to accumulate a set of historical \textbf{key-value} (KV) pairs for reuse, then further improvements selectively retain its subsets at each step. However, due to the sparse attention distribution across a long context, it is hard to identify and recall relevant KV pairs, as the attention is distracted by massive candidate pairs. Additionally, we found it promising to select representative tokens as probe-Query in each sliding window to effectively represent the entire context, which is an approach overlooked by existing methods. Thus, we propose \textbf{ActQKV}, a training-free, \textbf{Act}ivation-aware approach that dynamically determines probe-\textbf{Q}uery and leverages it to retrieve the relevant \textbf{KV} pairs for inference. Specifically, ActQKV monitors a token-level indicator, Activation Bias, within each context window, enabling the proper construction of probe-Query for retrieval at pre-filling stage. To accurately recall the relevant KV pairs and minimize the irrelevant ones, we design a dynamic KV cut-off mechanism guided by information density across layers at the decoding stage. Experiments on the Long-Bench and $\infty$ Benchmarks demonstrate its state-of-the-art performance with competitive inference quality and resource efficiency.
When Data Manipulation Meets Attack Goals: An In-depth Survey of Attacks for VLMs
Feb 10, 2025Vision-Language Models (VLMs) have gained considerable prominence in recent years due to their remarkable capability to effectively integrate and process both textual and visual information. This integration has significantly enhanced performance across a diverse spectrum of applications, such as scene perception and robotics. However, the deployment of VLMs has also given rise to critical safety and security concerns, necessitating extensive research to assess the potential vulnerabilities these VLM systems may harbor. In this work, we present an in-depth survey of the attack strategies tailored for VLMs. We categorize these attacks based on their underlying objectives - namely jailbreak, camouflage, and exploitation - while also detailing the various methodologies employed for data manipulation of VLMs. Meanwhile, we outline corresponding defense mechanisms that have been proposed to mitigate these vulnerabilities. By discerning key connections and distinctions among the diverse types of attacks, we propose a compelling taxonomy for VLM attacks. Moreover, we summarize the evaluation metrics that comprehensively describe the characteristics and impact of different attacks on VLMs. Finally, we conclude with a discussion of promising future research directions that could further enhance the robustness and safety of VLMs, emphasizing the importance of ongoing exploration in this critical area of study. To facilitate community engagement, we maintain an up-to-date project page, accessible at: https://github.com/AobtDai/VLM_Attack_Paper_List.
AttentionPredictor: Temporal Pattern Matters for Efficient LLM Inference
Feb 06, 2025



With the development of large language models (LLMs), efficient inference through Key-Value (KV) cache compression has attracted considerable attention, especially for long-context generation. To compress the KV cache, recent methods identify critical KV tokens through heuristic ranking with attention scores. However, these methods often struggle to accurately determine critical tokens as they neglect the \textit{temporal patterns} in attention scores, resulting in a noticeable degradation in LLM performance. To address this challenge, we propose AttentionPredictor, which is the first learning-based critical token identification approach. Specifically, AttentionPredictor learns a lightweight convolution model to capture spatiotemporal patterns and predict the next-token attention score. An appealing feature of AttentionPredictor is that it accurately predicts the attention score while consuming negligible memory. Moreover, we propose a cross-token critical cache prefetching framework that hides the token estimation time overhead to accelerate the decoding stage. By retaining most of the attention information, AttentionPredictor achieves 16$\times$ KV cache compression with comparable LLM performance, significantly outperforming the state-of-the-art.
SpaceGNN: Multi-Space Graph Neural Network for Node Anomaly Detection with Extremely Limited Labels
Feb 05, 2025



Node Anomaly Detection (NAD) has gained significant attention in the deep learning community due to its diverse applications in real-world scenarios. Existing NAD methods primarily embed graphs within a single Euclidean space, while overlooking the potential of non-Euclidean spaces. Besides, to address the prevalent issue of limited supervision in real NAD tasks, previous methods tend to leverage synthetic data to collect auxiliary information, which is not an effective solution as shown in our experiments. To overcome these challenges, we introduce a novel SpaceGNN model designed for NAD tasks with extremely limited labels. Specifically, we provide deeper insights into a task-relevant framework by empirically analyzing the benefits of different spaces for node representations, based on which, we design a Learnable Space Projection function that effectively encodes nodes into suitable spaces. Besides, we introduce the concept of weighted homogeneity, which we empirically and theoretically validate as an effective coefficient during information propagation. This concept inspires the design of the Distance Aware Propagation module. Furthermore, we propose the Multiple Space Ensemble module, which extracts comprehensive information for NAD under conditions of extremely limited supervision. Our findings indicate that this module is more beneficial than data augmentation techniques for NAD. Extensive experiments conducted on 9 real datasets confirm the superiority of SpaceGNN, which outperforms the best rival by an average of 8.55% in AUC and 4.31% in F1 scores. Our code is available at https://github.com/xydong127/SpaceGNN.
GaussianToken: An Effective Image Tokenizer with 2D Gaussian Splatting
Jan 26, 2025Effective image tokenization is crucial for both multi-modal understanding and generation tasks due to the necessity of the alignment with discrete text data. To this end, existing approaches utilize vector quantization (VQ) to project pixels onto a discrete codebook and reconstruct images from the discrete representation. However, compared with the continuous latent space, the limited discrete codebook space significantly restrict the representational ability of these image tokenizers. In this paper, we propose GaussianToken: An Effective Image Tokenizer with 2D Gaussian Splatting as a solution. We first represent the encoded samples as multiple flexible featured 2D Gaussians characterized by positions, rotation angles, scaling factors, and feature coefficients. We adopt the standard quantization for the Gaussian features and then concatenate the quantization results with the other intrinsic Gaussian parameters before the corresponding splatting operation and the subsequent decoding module. In general, GaussianToken integrates the local influence of 2D Gaussian distribution into the discrete space and thus enhances the representation capability of the image tokenizer. Competitive reconstruction performances on CIFAR, Mini-ImageNet, and ImageNet-1K demonstrate the effectiveness of our framework. Our code is available at: https://github.com/ChrisDong-THU/GaussianToken.
Top Ten Challenges Towards Agentic Neural Graph Databases
Jan 24, 2025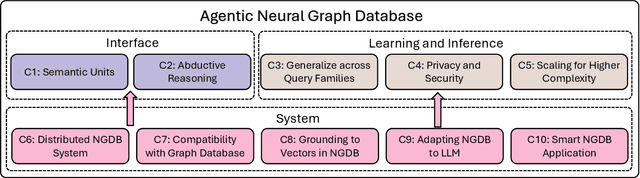
Graph databases (GDBs) like Neo4j and TigerGraph excel at handling interconnected data but lack advanced inference capabilities. Neural Graph Databases (NGDBs) address this by integrating Graph Neural Networks (GNNs) for predictive analysis and reasoning over incomplete or noisy data. However, NGDBs rely on predefined queries and lack autonomy and adaptability. This paper introduces Agentic Neural Graph Databases (Agentic NGDBs), which extend NGDBs with three core functionalities: autonomous query construction, neural query execution, and continuous learning. We identify ten key challenges in realizing Agentic NGDBs: semantic unit representation, abductive reasoning, scalable query execution, and integration with foundation models like large language models (LLMs). By addressing these challenges, Agentic NGDBs can enable intelligent, self-improving systems for modern data-driven applications, paving the way for adaptable and autonomous data management solutions.
AgentPose: Progressive Distribution Alignment via Feature Agent for Human Pose Distillation
Jan 14, 2025



Pose distillation is widely adopted to reduce model size in human pose estimation. However, existing methods primarily emphasize the transfer of teacher knowledge while often neglecting the performance degradation resulted from the curse of capacity gap between teacher and student. To address this issue, we propose AgentPose, a novel pose distillation method that integrates a feature agent to model the distribution of teacher features and progressively aligns the distribution of student features with that of the teacher feature, effectively overcoming the capacity gap and enhancing the ability of knowledge transfer. Our comprehensive experiments conducted on the COCO dataset substantiate the effectiveness of our method in knowledge transfer, particularly in scenarios with a high capacity gap.
Robust Low-Light Human Pose Estimation through Illumination-Texture Modulation
Jan 14, 2025



As critical visual details become obscured, the low visibility and high ISO noise in extremely low-light images pose a significant challenge to human pose estimation. Current methods fail to provide high-quality representations due to reliance on pixel-level enhancements that compromise semantics and the inability to effectively handle extreme low-light conditions for robust feature learning. In this work, we propose a frequency-based framework for low-light human pose estimation, rooted in the "divide-and-conquer" principle. Instead of uniformly enhancing the entire image, our method focuses on task-relevant information. By applying dynamic illumination correction to the low-frequency components and low-rank denoising to the high-frequency components, we effectively enhance both the semantic and texture information essential for accurate pose estimation. As a result, this targeted enhancement method results in robust, high-quality representations, significantly improving pose estimation performance. Extensive experiments demonstrating its superiority over state-of-the-art methods in various challenging low-light scenarios.
Localization-Aware Multi-Scale Representation Learning for Repetitive Action Counting
Jan 13, 2025



Repetitive action counting (RAC) aims to estimate the number of class-agnostic action occurrences in a video without exemplars. Most current RAC methods rely on a raw frame-to-frame similarity representation for period prediction. However, this approach can be significantly disrupted by common noise such as action interruptions and inconsistencies, leading to sub-optimal counting performance in realistic scenarios. In this paper, we introduce a foreground localization optimization objective into similarity representation learning to obtain more robust and efficient video features. We propose a Localization-Aware Multi-Scale Representation Learning (LMRL) framework. Specifically, we apply a Multi-Scale Period-Aware Representation (MPR) with a scale-specific design to accommodate various action frequencies and learn more flexible temporal correlations. Furthermore, we introduce the Repetition Foreground Localization (RFL) method, which enhances the representation by coarsely identifying periodic actions and incorporating global semantic information. These two modules can be jointly optimized, resulting in a more discerning periodic action representation. Our approach significantly reduces the impact of noise, thereby improving counting accuracy. Additionally, the framework is designed to be scalable and adaptable to different types of video content. Experimental results on the RepCountA and UCFRep datasets demonstrate that our proposed method effectively handles repetitive action counting.