 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGaussianToken: An Effective Image Tokenizer with 2D Gaussian Splatting
Jan 26, 2025Effective image tokenization is crucial for both multi-modal understanding and generation tasks due to the necessity of the alignment with discrete text data. To this end, existing approaches utilize vector quantization (VQ) to project pixels onto a discrete codebook and reconstruct images from the discrete representation. However, compared with the continuous latent space, the limited discrete codebook space significantly restrict the representational ability of these image tokenizers. In this paper, we propose GaussianToken: An Effective Image Tokenizer with 2D Gaussian Splatting as a solution. We first represent the encoded samples as multiple flexible featured 2D Gaussians characterized by positions, rotation angles, scaling factors, and feature coefficients. We adopt the standard quantization for the Gaussian features and then concatenate the quantization results with the other intrinsic Gaussian parameters before the corresponding splatting operation and the subsequent decoding module. In general, GaussianToken integrates the local influence of 2D Gaussian distribution into the discrete space and thus enhances the representation capability of the image tokenizer. Competitive reconstruction performances on CIFAR, Mini-ImageNet, and ImageNet-1K demonstrate the effectiveness of our framework. Our code is available at: https://github.com/ChrisDong-THU/GaussianToken.
V2M: Visual 2-Dimensional Mamba for Image Representation Learning
Oct 14, 2024



Mamba has garnered widespread attention due to its flexible design and efficient hardware performance to process 1D sequences based on the state space model (SSM). Recent studies have attempted to apply Mamba to the visual domain by flattening 2D images into patches and then regarding them as a 1D sequence. To compensate for the 2D structure information loss (e.g., local similarity) of the original image, most existing methods focus on designing different orders to sequentially process the tokens, which could only alleviate this issue to some extent. In this paper, we propose a Visual 2-Dimensional Mamba (V2M) model as a complete solution, which directly processes image tokens in the 2D space. We first generalize SSM to the 2-dimensional space which generates the next state considering two adjacent states on both dimensions (e.g., columns and rows). We then construct our V2M based on the 2-dimensional SSM formulation and incorporate Mamba to achieve hardware-efficient parallel processing. The proposed V2M effectively incorporates the 2D locality prior yet inherits the efficiency and input-dependent scalability of Mamba. Extensive experimental results on ImageNet classification and downstream visual tasks including object detection and instance segmentation on COCO and semantic segmentation on ADE20K demonstrate the effectiveness of our V2M compared with other visual backbones.
GlobalMamba: Global Image Serialization for Vision Mamba
Oct 14, 2024



Vision mambas have demonstrated strong performance with linear complexity to the number of vision tokens. Their efficiency results from processing image tokens sequentially. However, most existing methods employ patch-based image tokenization and then flatten them into 1D sequences for causal processing, which ignore the intrinsic 2D structural correlations of images. It is also difficult to extract global information by sequential processing of local patches. In this paper, we propose a global image serialization method to transform the image into a sequence of causal tokens, which contain global information of the 2D image. We first convert the image from the spatial domain to the frequency domain using Discrete Cosine Transform (DCT) and then arrange the pixels with corresponding frequency ranges. We further transform each set within the same frequency band back to the spatial domain to obtain a series of images before tokenization. We construct a vision mamba model, GlobalMamba, with a causal input format based on the proposed global image serialization, which can better exploit the causal relations among image sequences. Extensive experiments demonstrate the effectiveness of our GlobalMamba, including image classification on ImageNet-1K, object detection on COCO, and semantic segmentation on ADE20K.
Introspective Deep Metric Learning
Sep 11, 2023This paper proposes an introspective deep metric learning (IDML) framework for uncertainty-aware comparisons of images. Conventional deep metric learning methods focus on learning a discriminative embedding to describe the semantic features of images, which ignore the existence of uncertainty in each image resulting from noise or semantic ambiguity. Training without awareness of these uncertainties causes the model to overfit the annotated labels during training and produce unsatisfactory judgments during inference. Motivated by this, we argue that a good similarity model should consider the semantic discrepancies with awareness of the uncertainty to better deal with ambiguous images for more robust training. To achieve this, we propose to represent an image using not only a semantic embedding but also an accompanying uncertainty embedding, which describes the semantic characteristics and ambiguity of an image, respectively. We further propose an introspective similarity metric to make similarity judgments between images considering both their semantic differences and ambiguities. The gradient analysis of the proposed metric shows that it enables the model to learn at an adaptive and slower pace to deal with the uncertainty during training. The proposed IDML framework improves the performance of deep metric learning through uncertainty modeling and attains state-of-the-art results on the widely used CUB-200-2011, Cars196, and Stanford Online Products datasets for image retrieval and clustering. We further provide an in-depth analysis of our framework to demonstrate the effectiveness and reliability of IDML. Code: https://github.com/wzzheng/IDML.
Probabilistic Deep Metric Learning for Hyperspectral Image Classification
Nov 15, 2022This paper proposes a probabilistic deep metric learning (PDML) framework for hyperspectral image classification, which aims to predict the category of each pixel for an image captured by hyperspectral sensors. The core problem for hyperspectral image classification is the spectral variability between intraclass materials and the spectral similarity between interclass materials, motivating the further incorporation of spatial information to differentiate a pixel based on its surrounding patch. However, different pixels and even the same pixel in one patch might not encode the same material due to the low spatial resolution of most hyperspectral sensors, leading to an inconsistent judgment of a specific pixel. To address this issue, we propose a probabilistic deep metric learning framework to model the categorical uncertainty of the spectral distribution of an observed pixel. We propose to learn a global probabilistic distribution for each pixel in the patch and a probabilistic metric to model the distance between distributions. We treat each pixel in a patch as a training sample, enabling us to exploit more information from the patch compared with conventional methods. Our framework can be readily applied to existing hyperspectral image classification methods with various network architectures and loss functions. Extensive experiments on four widely used datasets including IN, UP, KSC, and Houston 2013 datasets demonstrate that our framework improves the performance of existing methods and further achieves the state of the art. Code is available at: https://github.com/wzzheng/PDML.
OPERA: Omni-Supervised Representation Learning with Hierarchical Supervisions
Oct 11, 2022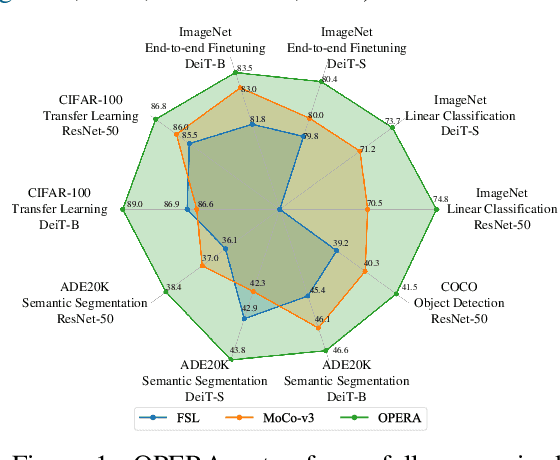
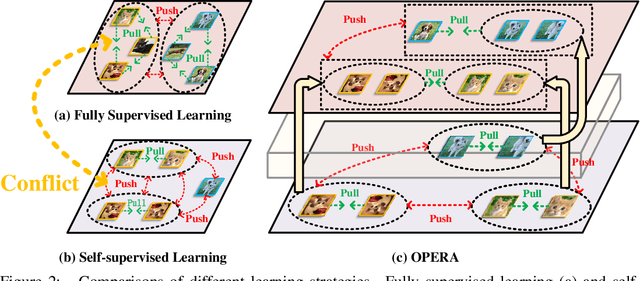
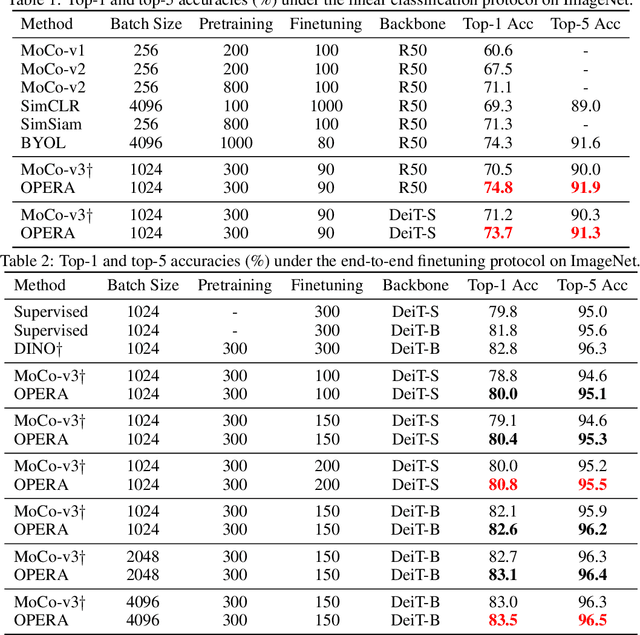
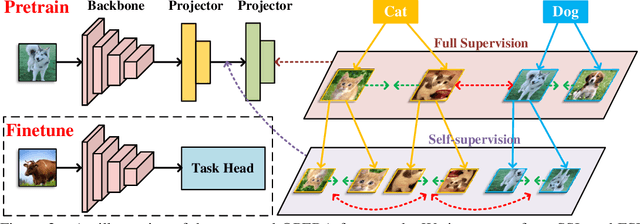
The pretrain-finetune paradigm in modern computer vision facilitates the success of self-supervised learning, which tends to achieve better transferability than supervised learning. However, with the availability of massive labeled data, a natural question emerges: how to train a better model with both self and full supervision signals? In this paper, we propose Omni-suPErvised Representation leArning with hierarchical supervisions (OPERA) as a solution. We provide a unified perspective of supervisions from labeled and unlabeled data and propose a unified framework of fully supervised and self-supervised learning. We extract a set of hierarchical proxy representations for each image and impose self and full supervisions on the corresponding proxy representations. Extensive experiments on both convolutional neural networks and vision transformers demonstrate the superiority of OPERA in image classification, segmentation, and object detection. Code is available at: https://github.com/wangck20/OPERA.