 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuestion Directed Graph Attention Network for Numerical Reasoning over Text
Sep 16, 2020
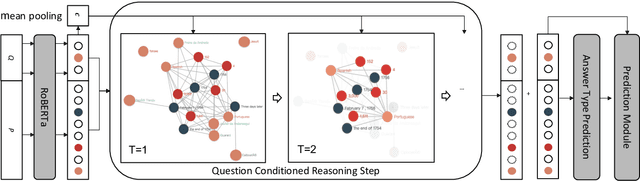
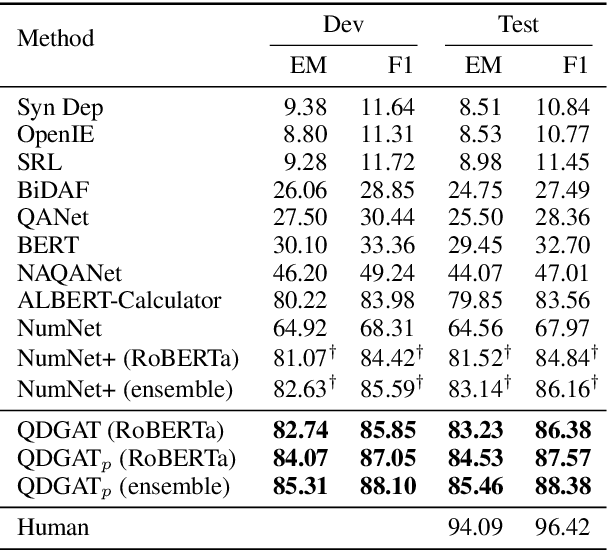
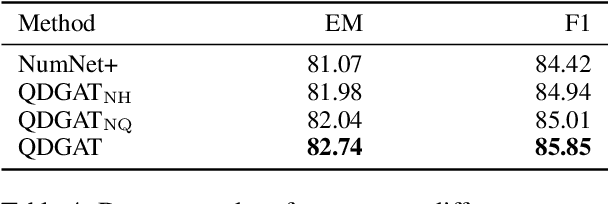
Numerical reasoning over texts, such as addition, subtraction, sorting and counting, is a challenging machine reading comprehension task, since it requires both natural language understanding and arithmetic computation. To address this challenge, we propose a heterogeneous graph representation for the context of the passage and question needed for such reasoning, and design a question directed graph attention network to drive multi-step numerical reasoning over this context graph.
Retro*: Learning Retrosynthetic Planning with Neural Guided A* Search
Jun 29, 2020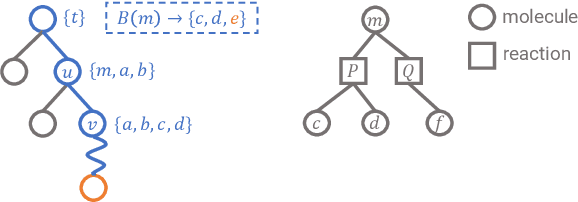

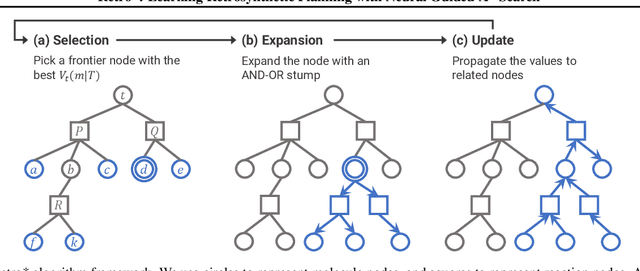
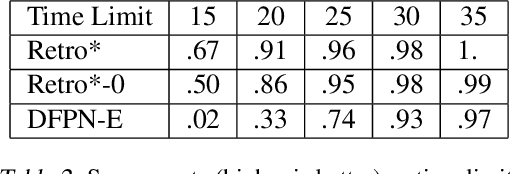
Retrosynthetic planning is a critical task in organic chemistry which identifies a series of reactions that can lead to the synthesis of a target product. The vast number of possible chemical transformations makes the size of the search space very big, and retrosynthetic planning is challenging even for experienced chemists. However, existing methods either require expensive return estimation by rollout with high variance, or optimize for search speed rather than the quality. In this paper, we propose Retro*, a neural-based A*-like algorithm that finds high-quality synthetic routes efficiently. It maintains the search as an AND-OR tree, and learns a neural search bias with off-policy data. Then guided by this neural network, it performs best-first search efficiently during new planning episodes. Experiments on benchmark USPTO datasets show that, our proposed method outperforms existing state-of-the-art with respect to both the success rate and solution quality, while being more efficient at the same time.
Understanding Deep Architectures with Reasoning Layer
Jun 24, 2020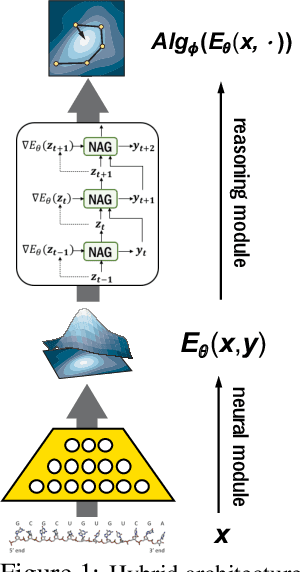

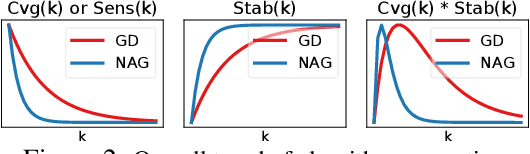
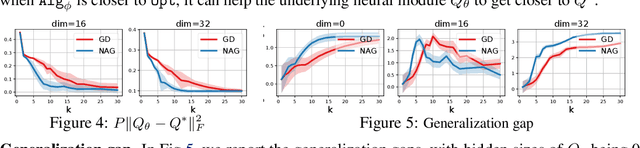
Recently, there has been a surge of interest in combining deep learning models with reasoning in order to handle more sophisticated learning tasks. In many cases, a reasoning task can be solved by an iterative algorithm. This algorithm is often unrolled, and used as a specialized layer in the deep architecture, which can be trained end-to-end with other neural components. Although such hybrid deep architectures have led to many empirical successes, the theoretical foundation of such architectures, especially the interplay between algorithm layers and other neural layers, remains largely unexplored. In this paper, we take an initial step towards an understanding of such hybrid deep architectures by showing that properties of the algorithm layers, such as convergence, stability, and sensitivity, are intimately related to the approximation and generalization abilities of the end-to-end model. Furthermore, our analysis matches closely our experimental observations under various conditions, suggesting that our theory can provide useful guidelines for designing deep architectures with reasoning layers.
Bandit Samplers for Training Graph Neural Networks
Jun 11, 2020
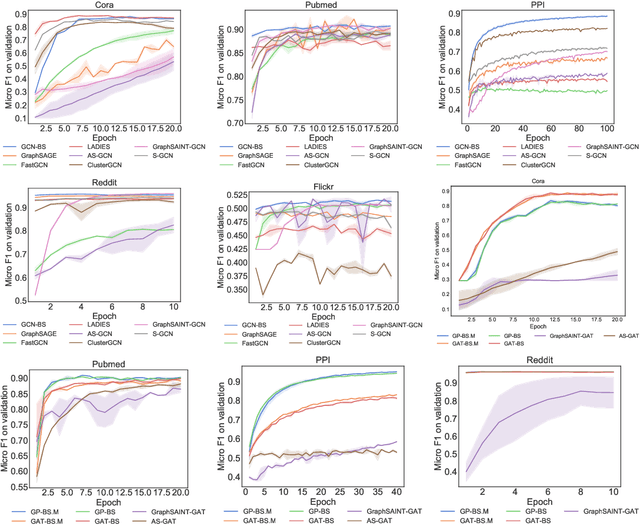
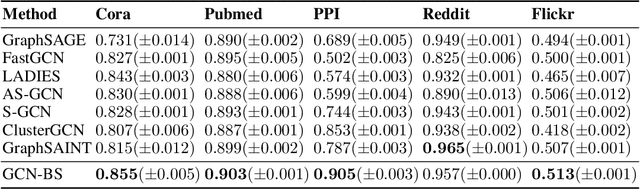
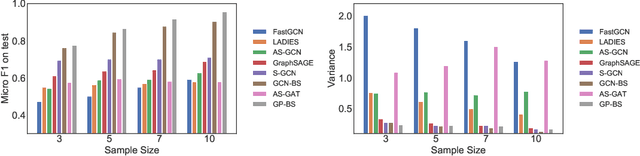
Several sampling algorithms with variance reduction have been proposed for accelerating the training of Graph Convolution Networks (GCNs). However, due to the intractable computation of optimal sampling distribution, these sampling algorithms are suboptimal for GCNs and are not applicable to more general graph neural networks (GNNs) where the message aggregator contains learned weights rather than fixed weights, such as Graph Attention Networks (GAT). The fundamental reason is that the embeddings of the neighbors or learned weights involved in the optimal sampling distribution are changing during the training and not known a priori, but only partially observed when sampled, thus making the derivation of an optimal variance reduced samplers non-trivial. In this paper, we formulate the optimization of the sampling variance as an adversary bandit problem, where the rewards are related to the node embeddings and learned weights, and can vary constantly. Thus a good sampler needs to acquire variance information about more neighbors (exploration) while at the same time optimizing the immediate sampling variance (exploit). We theoretically show that our algorithm asymptotically approaches the optimal variance within a factor of 3. We show the efficiency and effectiveness of our approach on multiple datasets.
Learning to Stop While Learning to Predict
Jun 09, 2020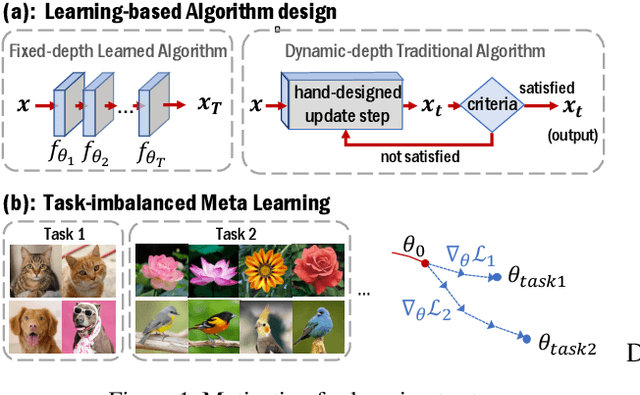

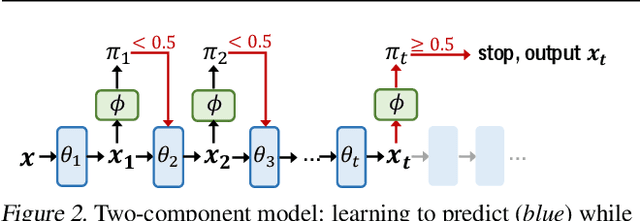
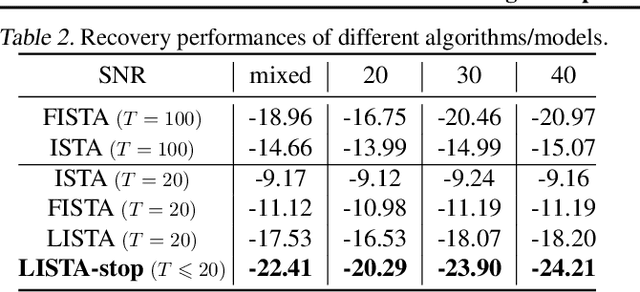
There is a recent surge of interest in designing deep architectures based on the update steps in traditional algorithms, or learning neural networks to improve and replace traditional algorithms. While traditional algorithms have certain stopping criteria for outputting results at different iterations, many algorithm-inspired deep models are restricted to a ``fixed-depth'' for all inputs. Similar to algorithms, the optimal depth of a deep architecture may be different for different input instances, either to avoid ``over-thinking'', or because we want to compute less for operations converged already. In this paper, we tackle this varying depth problem using a steerable architecture, where a feed-forward deep model and a variational stopping policy are learned together to sequentially determine the optimal number of layers for each input instance. Training such architecture is very challenging. We provide a variational Bayes perspective and design a novel and effective training procedure which decomposes the task into an oracle model learning stage and an imitation stage. Experimentally, we show that the learned deep model along with the stopping policy improves the performances on a diverse set of tasks, including learning sparse recovery, few-shot meta learning, and computer vision tasks.
Intention Propagation for Multi-agent Reinforcement Learning
Apr 19, 2020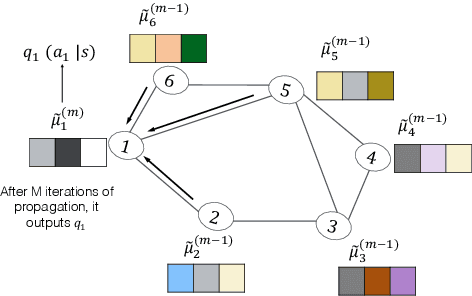

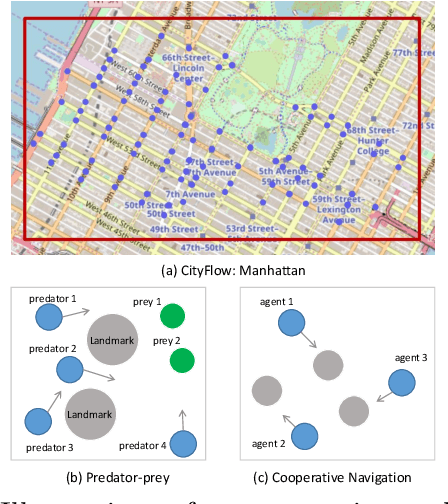
A hallmark of an AI agent is to mimic human beings to understand and interact with others. In this paper, we propose a collaborative multi-agent reinforcement learning algorithm to learn a \emph{joint} policy through the interactions over agents. To make a joint decision over the group, each agent makes an initial decision and tells its policy to its neighbors. Then each agent modifies its own policy properly based on received messages and spreads out its plan. As this intention propagation procedure goes on, we prove that it converges to a mean-field approximation of the joint policy with the framework of neural embedded probabilistic inference. We evaluate our algorithm on several large scale challenging tasks and demonstrate that it outperforms previous state-of-the-arts.
Orthogonal Over-Parameterized Training
Apr 09, 2020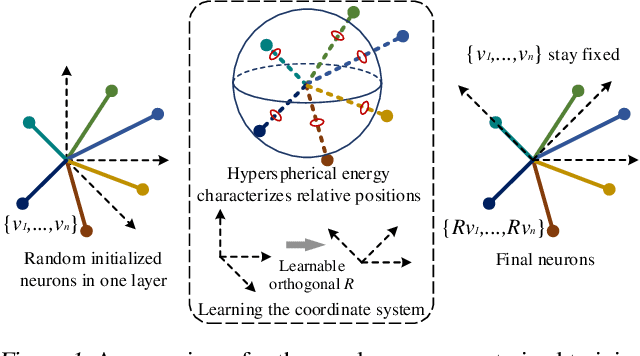
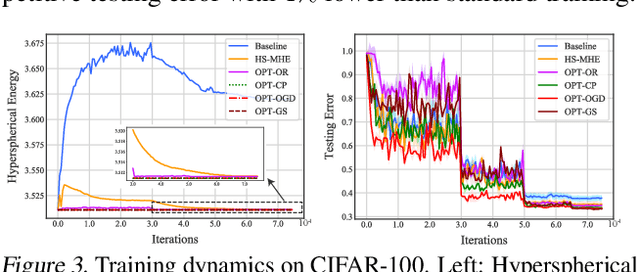
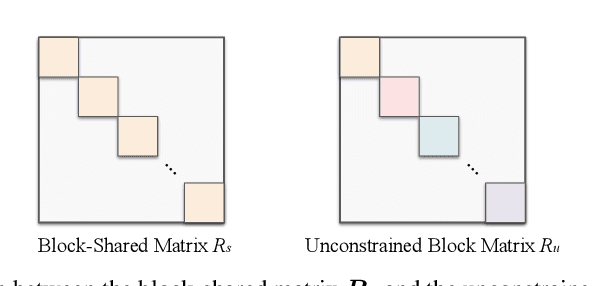
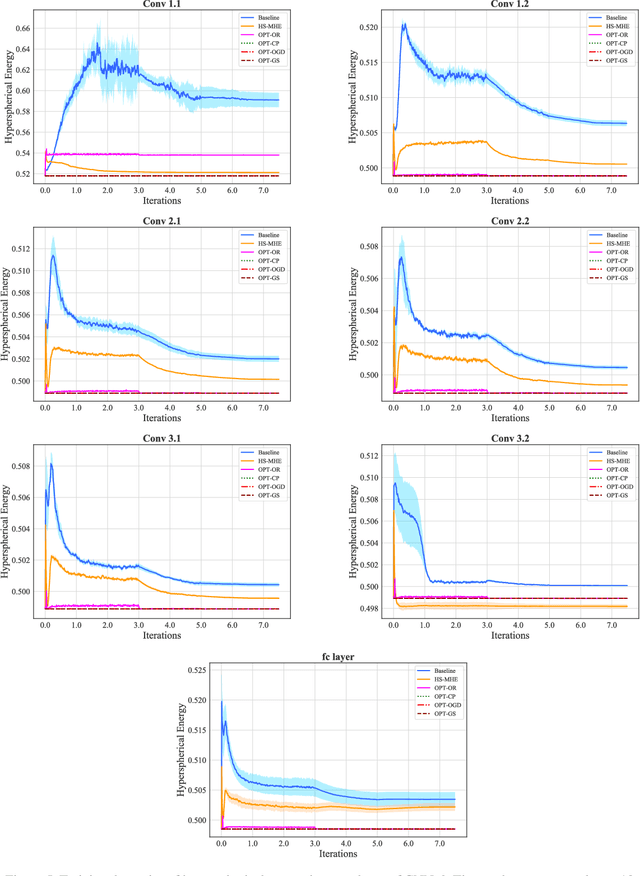
The inductive bias of a neural network is largely determined by the architecture and the training algorithm. To achieve good generalization, how to effectively train a neural network is even more important than designing the architecture. We propose a novel orthogonal over-parameterized training (OPT) framework that can provably minimize the hyperspherical energy which characterizes the diversity of neurons on a hypersphere. By constantly maintaining the minimum hyperspherical energy during training, OPT can greatly improve the network generalization. Specifically, OPT fixes the randomly initialized weights of the neurons and learns an orthogonal transformation that applies to these neurons. We propose multiple ways to learn such an orthogonal transformation, including unrolling orthogonalization algorithms, applying orthogonal parameterization, and designing orthogonality-preserving gradient update. Interestingly, OPT reveals that learning a proper coordinate system for neurons is crucial to generalization and may be more important than learning a specific relative position of neurons. We further provide theoretical insights of why OPT yields better generalization. Extensive experiments validate the superiority of OPT.
DC-BERT: Decoupling Question and Document for Efficient Contextual Encoding
Feb 28, 2020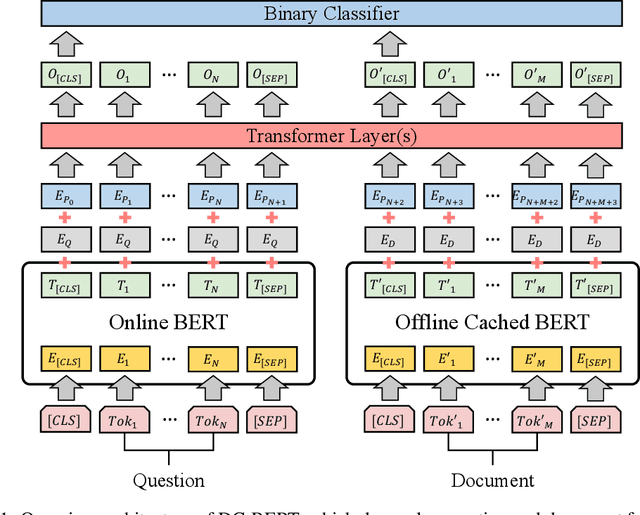
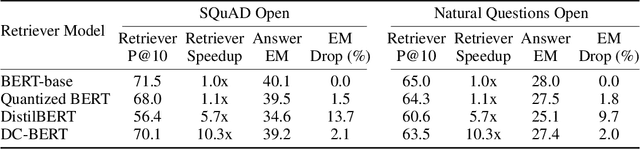
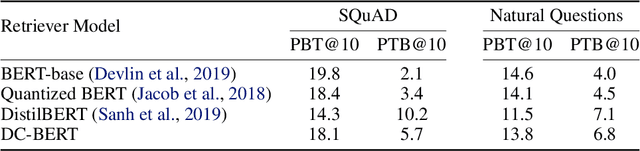
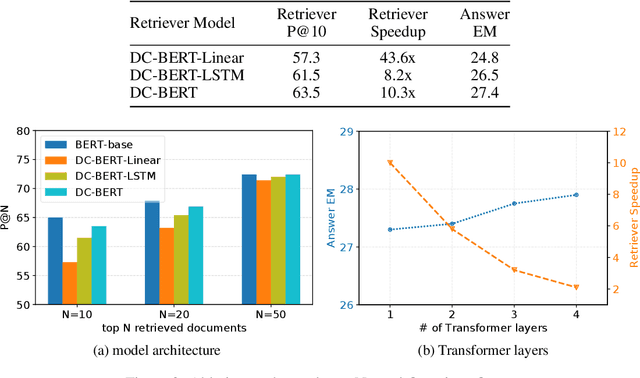
Recent studies on open-domain question answering have achieved prominent performance improvement using pre-trained language models such as BERT. State-of-the-art approaches typically follow the "retrieve and read" pipeline and employ BERT-based reranker to filter retrieved documents before feeding them into the reader module. The BERT retriever takes as input the concatenation of question and each retrieved document. Despite the success of these approaches in terms of QA accuracy, due to the concatenation, they can barely handle high-throughput of incoming questions each with a large collection of retrieved documents. To address the efficiency problem, we propose DC-BERT, a decoupled contextual encoding framework that has dual BERT models: an online BERT which encodes the question only once, and an offline BERT which pre-encodes all the documents and caches their encodings. On SQuAD Open and Natural Questions Open datasets, DC-BERT achieves 10x speedup on document retrieval, while retaining most (about 98%) of the QA performance compared to state-of-the-art approaches for open-domain question answering.
Heterogeneous Graph Neural Networks for Malicious Account Detection
Feb 27, 2020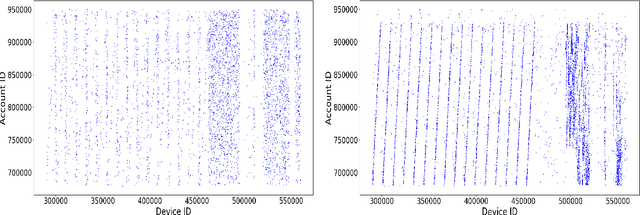
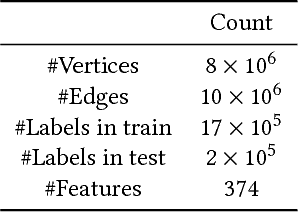
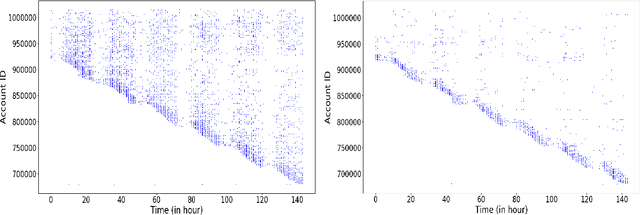
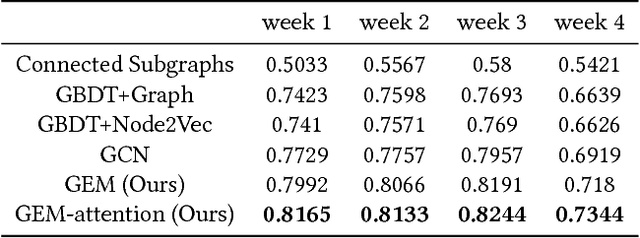
We present, GEM, the first heterogeneous graph neural network approach for detecting malicious accounts at Alipay, one of the world's leading mobile cashless payment platform. Our approach, inspired from a connected subgraph approach, adaptively learns discriminative embeddings from heterogeneous account-device graphs based on two fundamental weaknesses of attackers, i.e. device aggregation and activity aggregation. For the heterogeneous graph consists of various types of nodes, we propose an attention mechanism to learn the importance of different types of nodes, while using the sum operator for modeling the aggregation patterns of nodes in each type. Experiments show that our approaches consistently perform promising results compared with competitive methods over time.
RNA Secondary Structure Prediction By Learning Unrolled Algorithms
Feb 13, 2020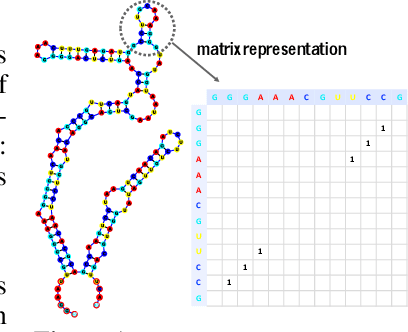
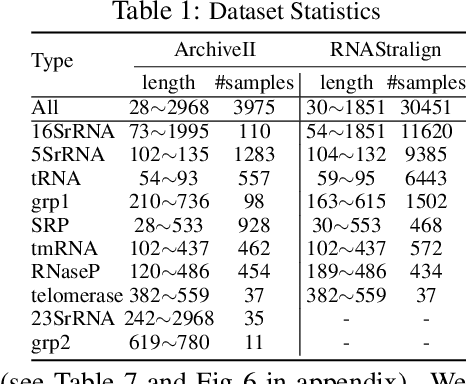
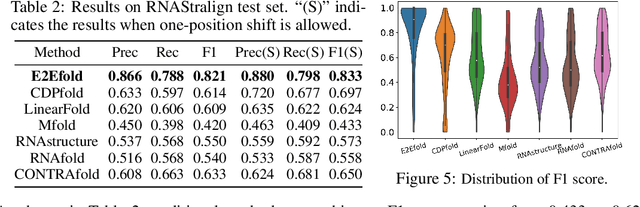
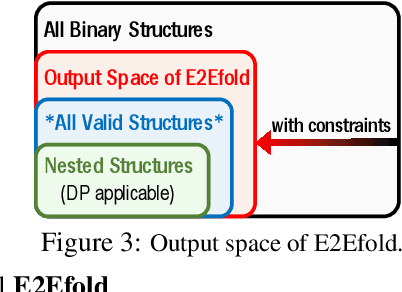
In this paper, we propose an end-to-end deep learning model, called E2Efold, for RNA secondary structure prediction which can effectively take into account the inherent constraints in the problem. The key idea of E2Efold is to directly predict the RNA base-pairing matrix, and use an unrolled algorithm for constrained programming as the template for deep architectures to enforce constraints. With comprehensive experiments on benchmark datasets, we demonstrate the superior performance of E2Efold: it predicts significantly better structures compared to previous SOTA (especially for pseudoknotted structures), while being as efficient as the fastest algorithms in terms of inference time.