 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFleet-DAgger: Interactive Robot Fleet Learning with Scalable Human Supervision
Jun 29, 2022
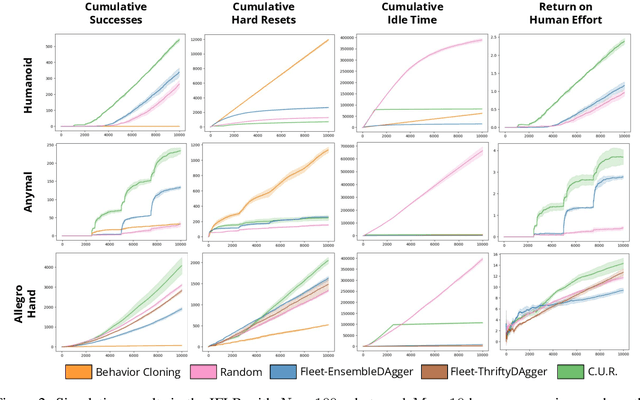
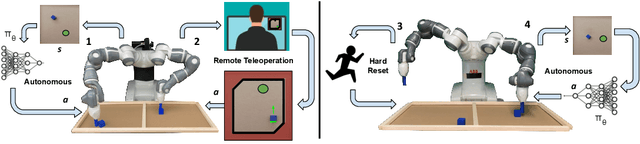
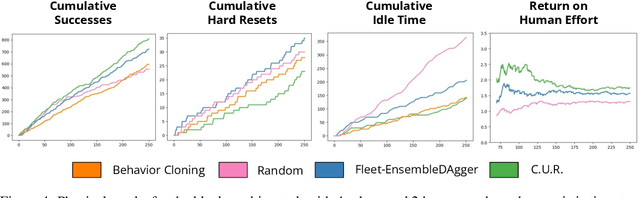
Commercial and industrial deployments of robot fleets often fall back on remote human teleoperators during execution when robots are at risk or unable to make task progress. With continual learning, interventions from the remote pool of humans can also be used to improve the robot fleet control policy over time. A central question is how to effectively allocate limited human attention to individual robots. Prior work addresses this in the single-robot, single-human setting. We formalize the Interactive Fleet Learning (IFL) setting, in which multiple robots interactively query and learn from multiple human supervisors. We present a fully implemented open-source IFL benchmark suite of GPU-accelerated Isaac Gym environments for the evaluation of IFL algorithms. We propose Fleet-DAgger, a family of IFL algorithms, and compare a novel Fleet-DAgger algorithm to 4 baselines in simulation. We also perform 1000 trials of a physical block-pushing experiment with 4 ABB YuMi robot arms. Experiments suggest that the allocation of humans to robots significantly affects robot fleet performance, and that our algorithm achieves up to 8.8x higher return on human effort than baselines. See https://tinyurl.com/fleet-dagger for code, videos, and supplemental material.
DayDreamer: World Models for Physical Robot Learning
Jun 28, 2022
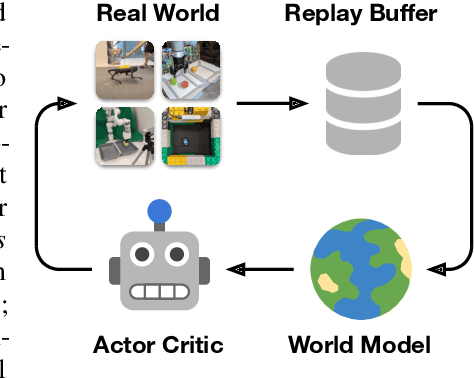
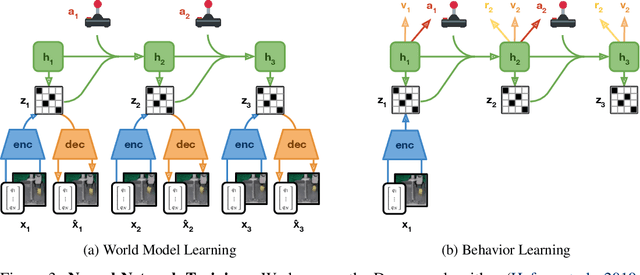

To solve tasks in complex environments, robots need to learn from experience. Deep reinforcement learning is a common approach to robot learning but requires a large amount of trial and error to learn, limiting its deployment in the physical world. As a consequence, many advances in robot learning rely on simulators. On the other hand, learning inside of simulators fails to capture the complexity of the real world, is prone to simulator inaccuracies, and the resulting behaviors do not adapt to changes in the world. The Dreamer algorithm has recently shown great promise for learning from small amounts of interaction by planning within a learned world model, outperforming pure reinforcement learning in video games. Learning a world model to predict the outcomes of potential actions enables planning in imagination, reducing the amount of trial and error needed in the real environment. However, it is unknown whether Dreamer can facilitate faster learning on physical robots. In this paper, we apply Dreamer to 4 robots to learn online and directly in the real world, without simulators. Dreamer trains a quadruped robot to roll off its back, stand up, and walk from scratch and without resets in only 1 hour. We then push the robot and find that Dreamer adapts within 10 minutes to withstand perturbations or quickly roll over and stand back up. On two different robotic arms, Dreamer learns to pick and place multiple objects directly from camera images and sparse rewards, approaching human performance. On a wheeled robot, Dreamer learns to navigate to a goal position purely from camera images, automatically resolving ambiguity about the robot orientation. Using the same hyperparameters across all experiments, we find that Dreamer is capable of online learning in the real world, establishing a strong baseline. We release our infrastructure for future applications of world models to robot learning.
Efficiently Learning Single-Arm Fling Motions to Smooth Garments
Jun 17, 2022

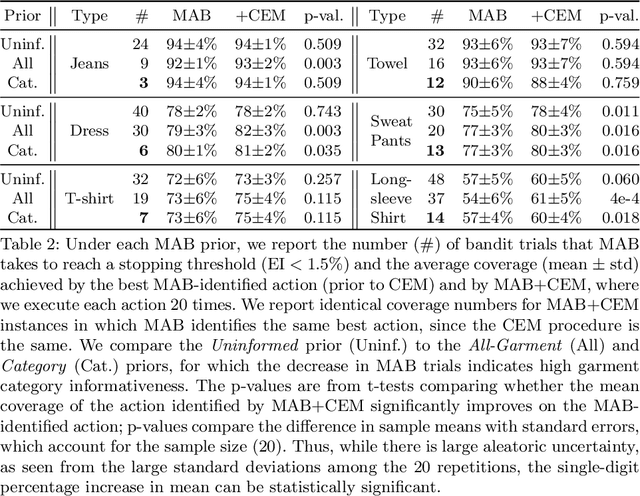
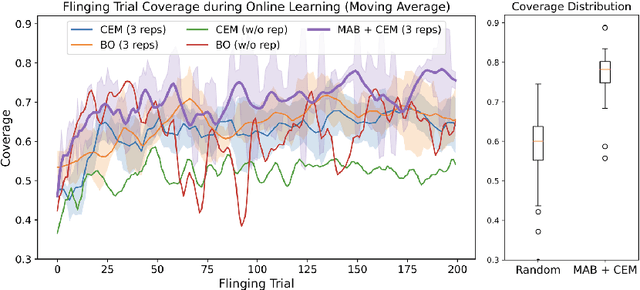
Recent work has shown that 2-arm "fling" motions can be effective for garment smoothing. We consider single-arm fling motions. Unlike 2-arm fling motions, which require little robot trajectory parameter tuning, single-arm fling motions are sensitive to trajectory parameters. We consider a single 6-DOF robot arm that learns fling trajectories to achieve high garment coverage. Given a garment grasp point, the robot explores different parameterized fling trajectories in physical experiments. To improve learning efficiency, we propose a coarse-to-fine learning method that first uses a multi-armed bandit (MAB) framework to efficiently find a candidate fling action, which it then refines via a continuous optimization method. Further, we propose novel training and execution-time stopping criteria based on fling outcome uncertainty. Compared to baselines, we show that the proposed method significantly accelerates learning. Moreover, with prior experience on similar garments collected through self-supervision, the MAB learning time for a new garment is reduced by up to 87%. We evaluate on 6 garment types: towels, T-shirts, long-sleeve shirts, dresses, sweat pants, and jeans. Results suggest that using prior experience, a robot requires under 30 minutes to learn a fling action for a novel garment that achieves 60-94% coverage.
Optimal Shelf Arrangement to Minimize Robot Retrieval Time
Jun 17, 2022
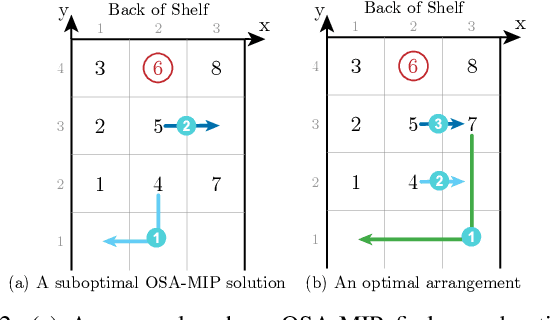
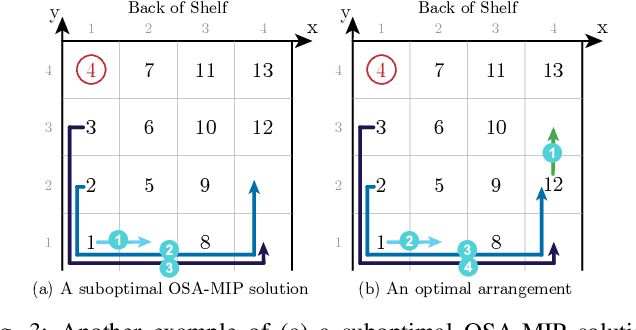
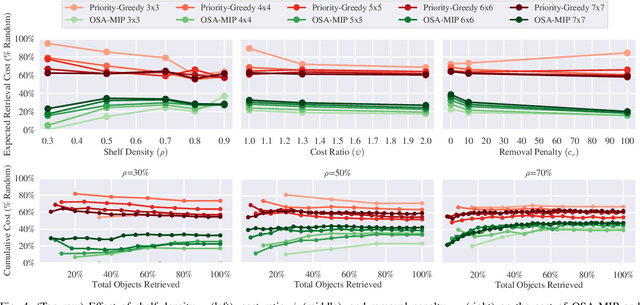
Shelves are commonly used to store objects in homes, stores, and warehouses. We formulate the problem of Optimal Shelf Arrangement (OSA), where the goal is to optimize the arrangement of objects on a shelf for access time given an access frequency and movement cost for each object. We propose OSA-MIP, a mixed-integer program (MIP), show that it finds an optimal solution for OSA under certain conditions, and provide bounds on its suboptimal solutions in general cost settings. We analytically characterize a necessary and sufficient shelf density condition for which there exists an arrangement such that any object can be retrieved without removing objects from the shelf. Experimental data from 1,575 simulated shelf trials and 54 trials with a physical Fetch robot equipped with a pushing blade and suction grasping tool suggest that arranging the objects optimally reduces the expected retrieval cost by 60-80% in fully-observed configurations and reduces the expected search cost by 50-70% while increasing the search success rate by up to 2x in partially-observed configurations.
Multi-Object Grasping in the Plane
Jun 01, 2022

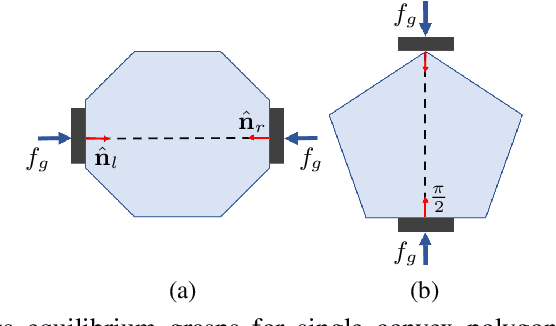
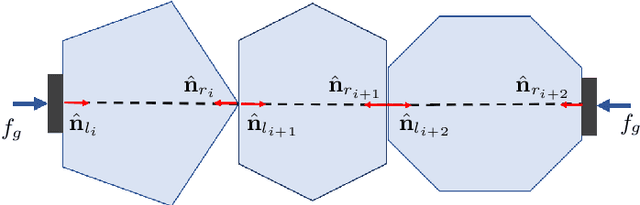
We consider the problem where multiple rigid convex polygonal objects rest in randomly placed positions and orientations on a planar surface visible from an overhead camera. The objective is to efficiently grasp and transport all objects into a bin. Specifically, we explore multi-object push-grasps where multiple objects are pushed together before the grasp can occur. We provide necessary conditions for multi-object push-grasps and apply these to filter inadmissible grasps in a novel multi-object grasp planner. We find that our planner is 19 times faster than a Mujoco simulator baseline. We also propose a picking algorithm that uses both single- and multi-object grasps to pick objects. In physical grasping experiments, compared to a single-object picking baseline, we find that the multi-object grasping system achieves 13.6% higher grasp success and is 59.9% faster. See https://sites.google.com/view/multi-object-grasping for videos, code, and data.
FogROS 2: An Adaptive and Extensible Platform for Cloud and Fog Robotics Using ROS 2
May 19, 2022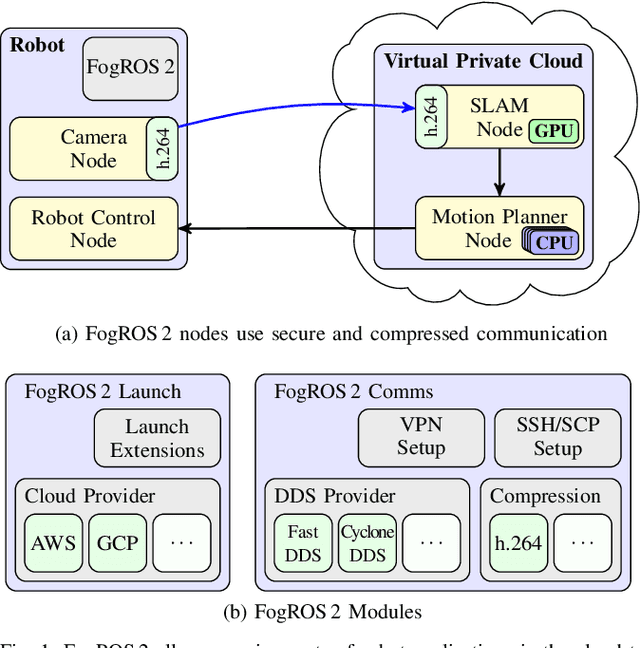
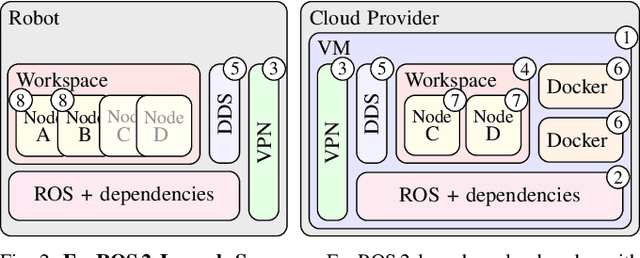
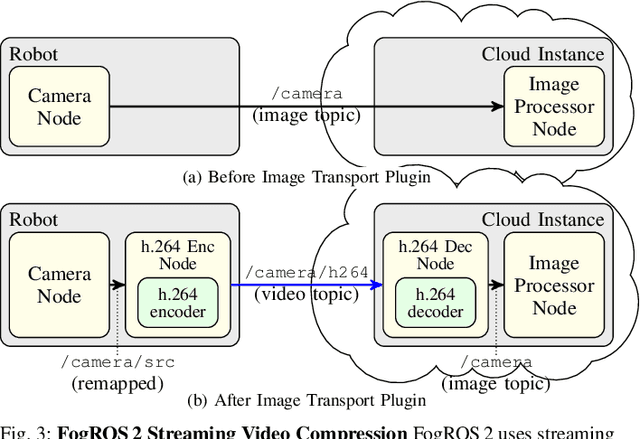
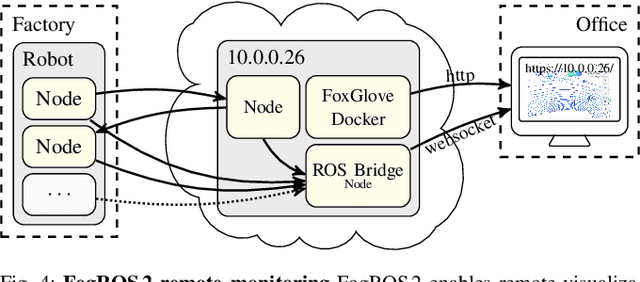
Mobility, power, and price points often dictate that robots do not have sufficient computing power on board to run modern robot algorithms at desired rates. Cloud computing providers such as AWS, GCP, and Azure offer immense computing power on demand, but tapping into that power from a robot is non-trivial. In this paper, we present FogROS 2, an easy-to-use, open-source platform to facilitate cloud and fog robotics compatible with the emerging ROS 2 standard, extending the open-source Robot Operating System (ROS). FogROS 2 provisions a cloud computer, deploys and launches ROS 2 nodes to the cloud computer, sets up secure networking between the robot and cloud, and starts the application running. FogROS 2 is completely redesigned and distinct from its predecessor to support ROS 2 applications, transparent video compression and communication, improved performance and security, support for multiple cloud-computing providers, and remote monitoring and visualization. We demonstrate in example applications that the performance gained by using cloud computers can overcome the network latency to significantly speed up robot performance. In examples, FogROS 2 reduces SLAM latency by 50%, reduces grasp planning time from 14s to 1.2s, and speeds up motion planning 28x. When compared to alternatives, FogROS 2 reduces network utilization by up to 3.8x. FogROS 2, source, examples, and documentation is available at https://github.com/BerkeleyAutomation/FogROS2 .
Learning to Fold Real Garments with One Arm: A Case Study in Cloud-Based Robotics Research
Apr 21, 2022


Autonomous fabric manipulation is a longstanding challenge in robotics, but evaluating progress is difficult due to the cost and diversity of robot hardware. Using Reach, a cloud robotics platform that enables low-latency remote execution of control policies on physical robots, we present the first systematic benchmarking of fabric manipulation algorithms on physical hardware. We develop 4 novel learning-based algorithms that model expert actions, keypoints, reward functions, and dynamic motions, and we compare these against 4 learning-free and inverse dynamics algorithms on the task of folding a crumpled T-shirt with a single robot arm. The entire lifecycle of data collection, model training, and policy evaluation is performed remotely without physical access to the robot workcell. Results suggest a new algorithm combining imitation learning with analytic methods achieves 84% of human-level performance on the folding task. See https://sites.google.com/berkeley.edu/cloudfolding for all data, code, models, and supplemental material.
Adversarial Motion Priors Make Good Substitutes for Complex Reward Functions
Mar 28, 2022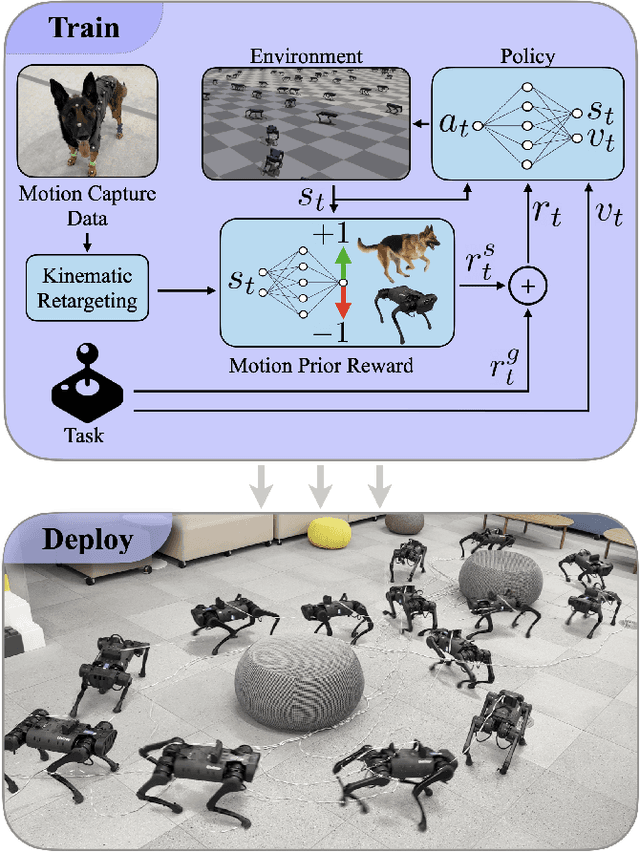
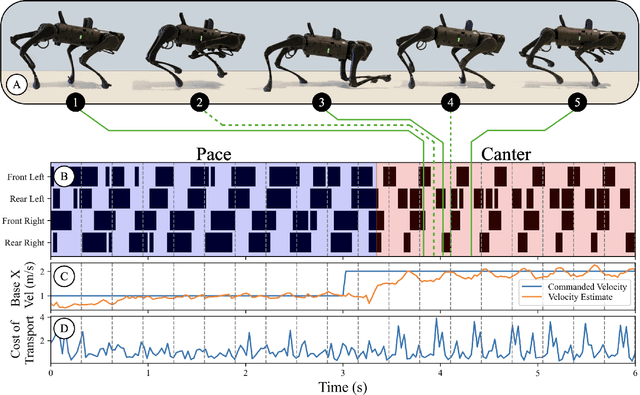


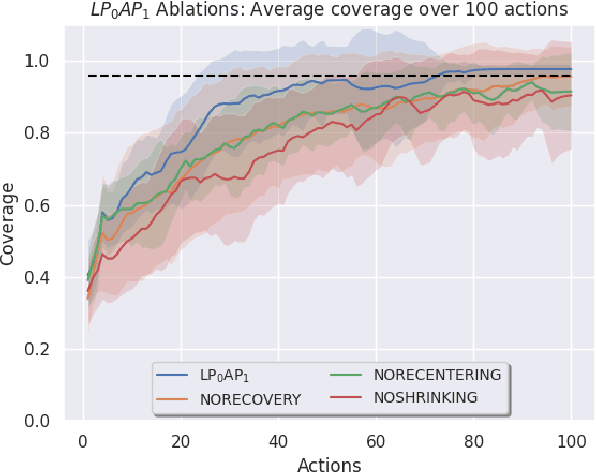
Training a high-dimensional simulated agent with an under-specified reward function often leads the agent to learn physically infeasible strategies that are ineffective when deployed in the real world. To mitigate these unnatural behaviors, reinforcement learning practitioners often utilize complex reward functions that encourage physically plausible behaviors. However, a tedious labor-intensive tuning process is often required to create hand-designed rewards which might not easily generalize across platforms and tasks. We propose substituting complex reward functions with "style rewards" learned from a dataset of motion capture demonstrations. A learned style reward can be combined with an arbitrary task reward to train policies that perform tasks using naturalistic strategies. These natural strategies can also facilitate transfer to the real world. We build upon Adversarial Motion Priors -- an approach from the computer graphics domain that encodes a style reward from a dataset of reference motions -- to demonstrate that an adversarial approach to training policies can produce behaviors that transfer to a real quadrupedal robot without requiring complex reward functions. We also demonstrate that an effective style reward can be learned from a few seconds of motion capture data gathered from a German Shepherd and leads to energy-efficient locomotion strategies with natural gait transitions.
GOMP-ST: Grasp Optimized Motion Planning for Suction Transport
Mar 16, 2022
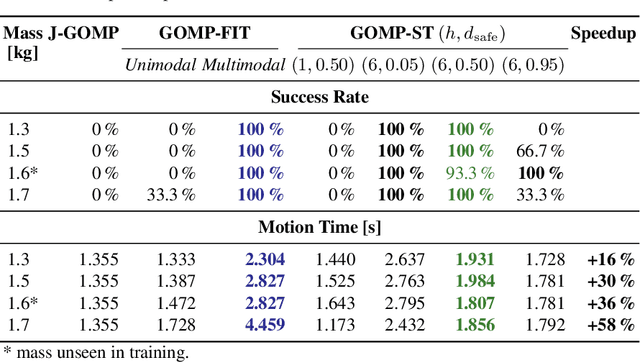
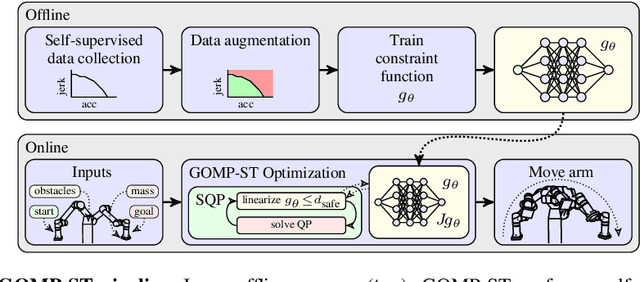

Suction cup grasping is very common in industry, but moving too quickly can cause suction cups to detach, causing drops or damage. Maintaining a suction grasp throughout a high-speed motion requires balancing suction forces against inertial forces while the suction cups deform under strain. In this paper, we consider Grasp Optimized Motion Planning for Suction Transport (GOMP-ST), an algorithm that combines deep learning with optimization to decrease transport time while avoiding suction cup failure. GOMP-ST first repeatedly moves a physical robot, vacuum gripper, and a sample object, while measuring pressure with a solid-state sensor to learn critical failure conditions. Then, these are integrated as constraints on the accelerations at the end-effector into a time-optimizing motion planner. The resulting plans incorporate real-world effects such as suction cup deformation that are difficult to model analytically. In GOMP-ST, the learned constraint, modeled with a neural network, is linearized using Autograd and integrated into a sequential quadratic program optimization. In 420 experiments with a physical UR5 transporting objects ranging from 1.3 to 1.7 kg, we compare GOMP-ST to baseline optimizing motion planners. Results suggest that GOMP-ST can avoid suction cup failure while decreasing transport times from 16% to 58%. For code, video, and datasets, see https://sites.google.com/view/gomp-st.
All You Need is LUV: Unsupervised Collection of Labeled Images using Invisible UV Fluorescent Indicators
Mar 13, 2022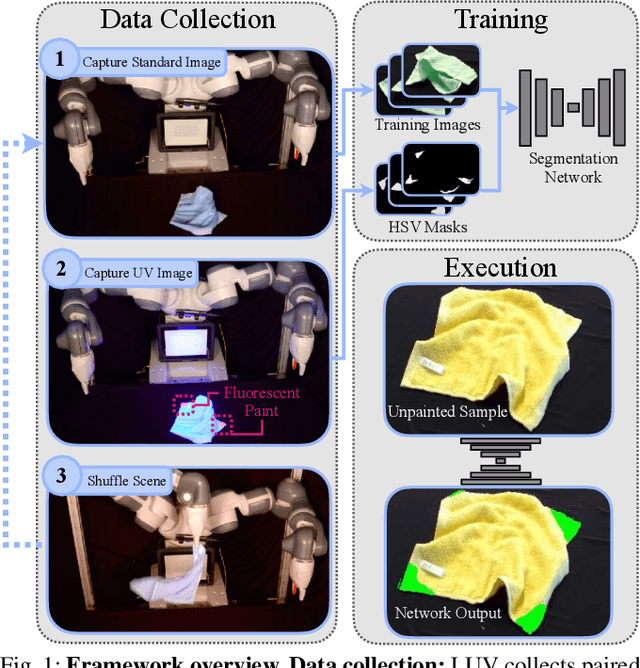



Large-scale semantic image annotation is a significant challenge for learning-based perception systems in robotics. Current approaches often rely on human labelers, which can be expensive, or simulation data, which can visually or physically differ from real data. This paper proposes Labels from UltraViolet (LUV), a novel framework that enables rapid, labeled data collection in real manipulation environments without human labeling. LUV uses transparent, ultraviolet-fluorescent paint with programmable ultraviolet LEDs to collect paired images of a scene in standard lighting and UV lighting to autonomously extract segmentation masks and keypoints via color segmentation. We apply LUV to a suite of diverse robot perception tasks to evaluate its labeling quality, flexibility, and data collection rate. Results suggest that LUV is 180-2500 times faster than a human labeler across the tasks. We show that LUV provides labels consistent with human annotations on unpainted test images. The networks trained on these labels are used to smooth and fold crumpled towels with 83% success rate and achieve 1.7mm position error with respect to human labels on a surgical needle pose estimation task. The low cost of LUV makes it ideal as a lightweight replacement for human labeling systems, with the one-time setup costs at $300 equivalent to the cost of collecting around 200 semantic segmentation labels on Amazon Mechanical Turk. Code, datasets, visualizations, and supplementary material can be found at https://sites.google.com/berkeley.edu/luv