 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynaIP: Dynamic Image Prompt Adapter for Scalable Zero-shot Personalized Text-to-Image Generation
Dec 10, 2025



Personalized Text-to-Image (PT2I) generation aims to produce customized images based on reference images. A prominent interest pertains to the integration of an image prompt adapter to facilitate zero-shot PT2I without test-time fine-tuning. However, current methods grapple with three fundamental challenges: 1. the elusive equilibrium between Concept Preservation (CP) and Prompt Following (PF), 2. the difficulty in retaining fine-grained concept details in reference images, and 3. the restricted scalability to extend to multi-subject personalization. To tackle these challenges, we present Dynamic Image Prompt Adapter (DynaIP), a cutting-edge plugin to enhance the fine-grained concept fidelity, CP-PF balance, and subject scalability of SOTA T2I multimodal diffusion transformers (MM-DiT) for PT2I generation. Our key finding is that MM-DiT inherently exhibit decoupling learning behavior when injecting reference image features into its dual branches via cross attentions. Based on this, we design an innovative Dynamic Decoupling Strategy that removes the interference of concept-agnostic information during inference, significantly enhancing the CP-PF balance and further bolstering the scalability of multi-subject compositions. Moreover, we identify the visual encoder as a key factor affecting fine-grained CP and reveal that the hierarchical features of commonly used CLIP can capture visual information at diverse granularity levels. Therefore, we introduce a novel Hierarchical Mixture-of-Experts Feature Fusion Module to fully leverage the hierarchical features of CLIP, remarkably elevating the fine-grained concept fidelity while also providing flexible control of visual granularity. Extensive experiments across single- and multi-subject PT2I tasks verify that our DynaIP outperforms existing approaches, marking a notable advancement in the field of PT2l generation.
STAR Loss: Reducing Semantic Ambiguity in Facial Landmark Detection
Jun 05, 2023Recently, deep learning-based facial landmark detection has achieved significant improvement. However, the semantic ambiguity problem degrades detection performance. Specifically, the semantic ambiguity causes inconsistent annotation and negatively affects the model's convergence, leading to worse accuracy and instability prediction. To solve this problem, we propose a Self-adapTive Ambiguity Reduction (STAR) loss by exploiting the properties of semantic ambiguity. We find that semantic ambiguity results in the anisotropic predicted distribution, which inspires us to use predicted distribution to represent semantic ambiguity. Based on this, we design the STAR loss that measures the anisotropism of the predicted distribution. Compared with the standard regression loss, STAR loss is encouraged to be small when the predicted distribution is anisotropic and thus adaptively mitigates the impact of semantic ambiguity. Moreover, we propose two kinds of eigenvalue restriction methods that could avoid both distribution's abnormal change and the model's premature convergence. Finally, the comprehensive experiments demonstrate that STAR loss outperforms the state-of-the-art methods on three benchmarks, i.e., COFW, 300W, and WFLW, with negligible computation overhead. Code is at https://github.com/ZhenglinZhou/STAR.
Pixel2Mesh: Generating 3D Mesh Models from Single RGB Images
Aug 03, 2018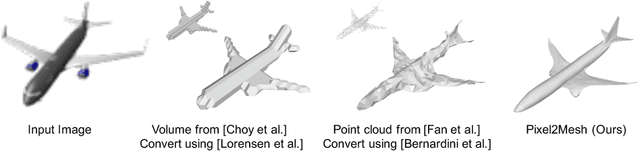
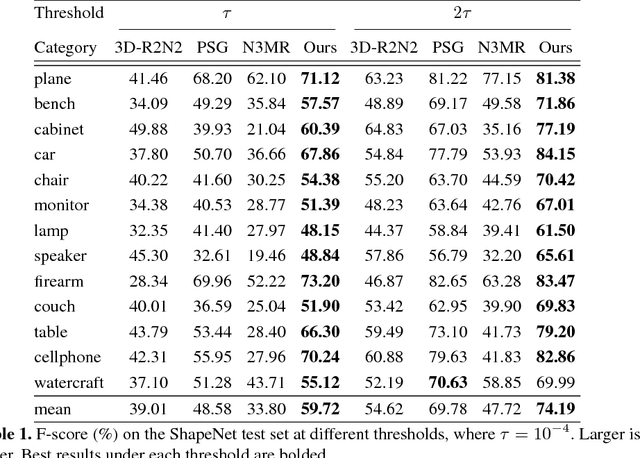
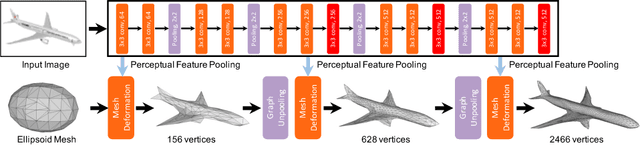
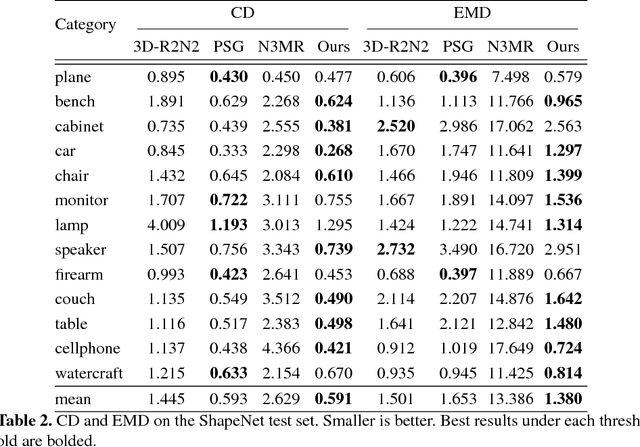
We propose an end-to-end deep learning architecture that produces a 3D shape in triangular mesh from a single color image. Limited by the nature of deep neural network, previous methods usually represent a 3D shape in volume or point cloud, and it is non-trivial to convert them to the more ready-to-use mesh model. Unlike the existing methods, our network represents 3D mesh in a graph-based convolutional neural network and produces correct geometry by progressively deforming an ellipsoid, leveraging perceptual features extracted from the input image. We adopt a coarse-to-fine strategy to make the whole deformation procedure stable, and define various of mesh related losses to capture properties of different levels to guarantee visually appealing and physically accurate 3D geometry. Extensive experiments show that our method not only qualitatively produces mesh model with better details, but also achieves higher 3D shape estimation accuracy compared to the state-of-the-art.