 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSysML: The New Frontier of Machine Learning Systems
May 01, 2019Machine learning (ML) techniques are enjoying rapidly increasing adoption. However, designing and implementing the systems that support ML models in real-world deployments remains a significant obstacle, in large part due to the radically different development and deployment profile of modern ML methods, and the range of practical concerns that come with broader adoption. We propose to foster a new systems machine learning research community at the intersection of the traditional systems and ML communities, focused on topics such as hardware systems for ML, software systems for ML, and ML optimized for metrics beyond predictive accuracy. To do this, we describe a new conference, SysML, that explicitly targets research at the intersection of systems and machine learning with a program committee split evenly between experts in systems and ML, and an explicit focus on topics at the intersection of the two.
Precision and Recall for Time Series
Oct 28, 2018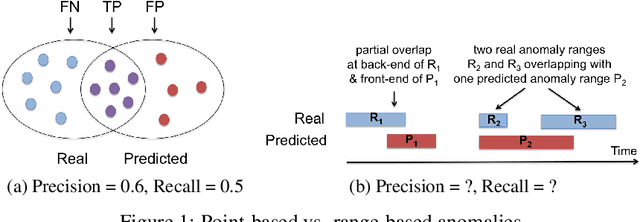


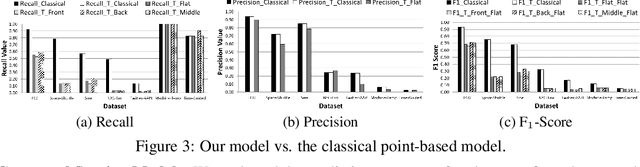
Classical anomaly detection is principally concerned with point-based anomalies, those anomalies that occur at a single point in time. Yet, many real-world anomalies are range-based, meaning they occur over a period of time. Motivated by this observation, we present a new mathematical model to evaluate the accuracy of time series classification algorithms. Our model expands the well-known Precision and Recall metrics to measure ranges, while simultaneously enabling customization support for domain-specific preferences.
The Three Pillars of Machine Programming
May 08, 2018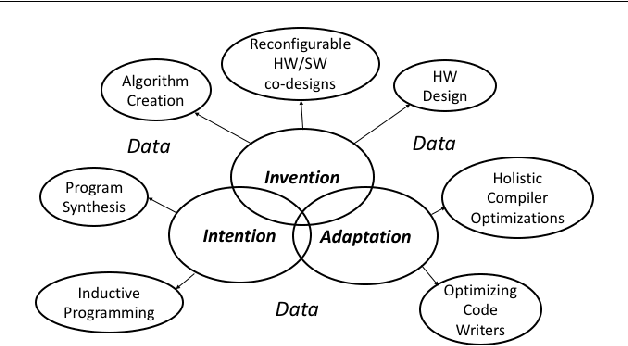
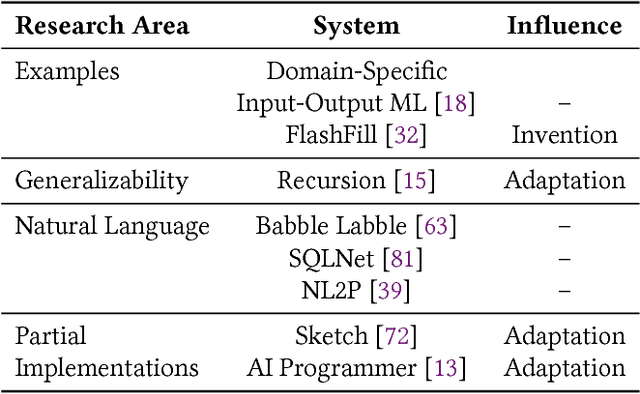
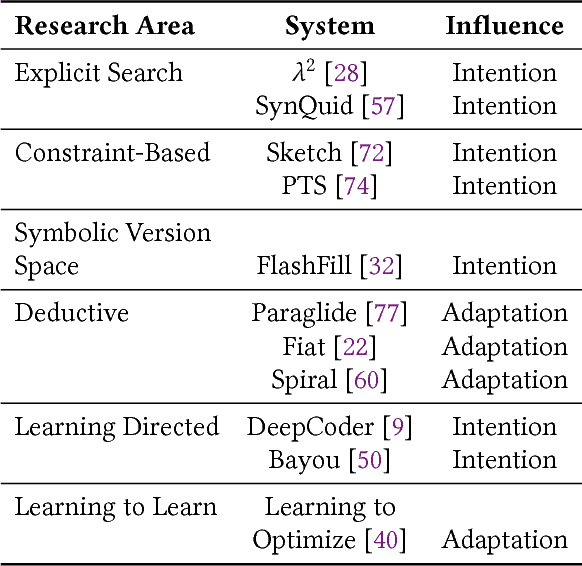
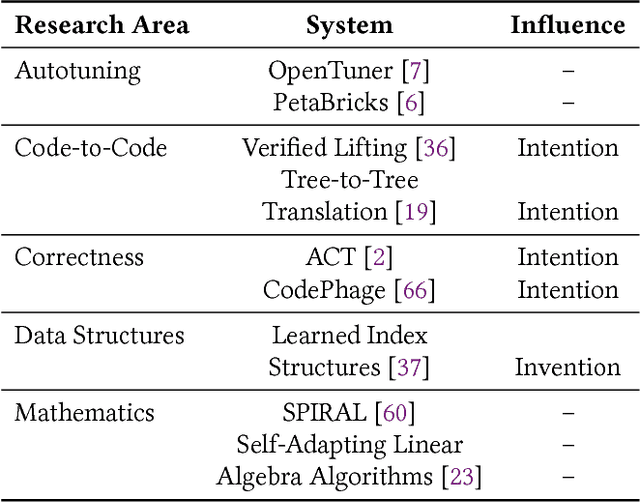
In this position paper, we describe our vision of the future of machine programming through a categorical examination of three pillars of research. Those pillars are: (i) intention, (ii) invention, and(iii) adaptation. Intention emphasizes advancements in the human-to-computer and computer-to-machine-learning interfaces. Invention emphasizes the creation or refinement of algorithms or core hardware and software building blocks through machine learning (ML). Adaptation emphasizes advances in the use of ML-based constructs to autonomously evolve software.
Greenhouse: A Zero-Positive Machine Learning System for Time-Series Anomaly Detection
Feb 11, 2018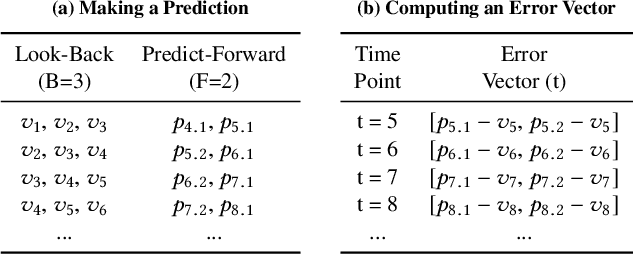
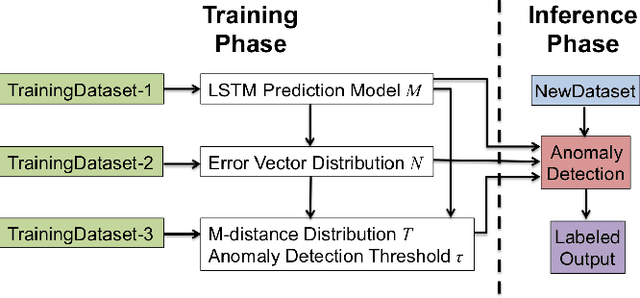
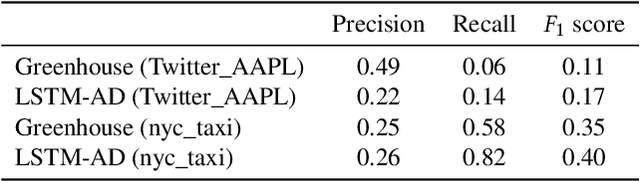
This short paper describes our ongoing research on Greenhouse - a zero-positive machine learning system for time-series anomaly detection.
Precision and Recall for Range-Based Anomaly Detection
Feb 11, 2018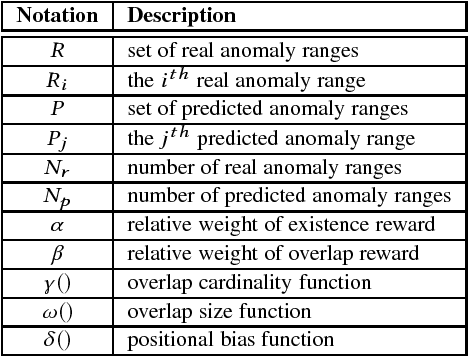

Classical anomaly detection is principally concerned with point-based anomalies, anomalies that occur at a single data point. In this paper, we present a new mathematical model to express range-based anomalies, anomalies that occur over a range (or period) of time.
Toward Scalable Verification for Safety-Critical Deep Networks
Feb 02, 2018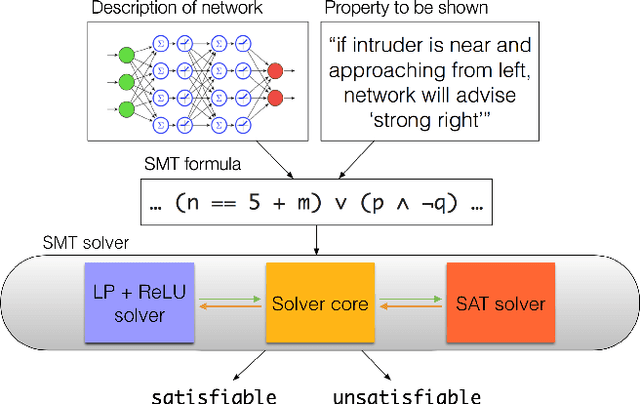
The increasing use of deep neural networks for safety-critical applications, such as autonomous driving and flight control, raises concerns about their safety and reliability. Formal verification can address these concerns by guaranteeing that a deep learning system operates as intended, but the state of the art is limited to small systems. In this work-in-progress report we give an overview of our work on mitigating this difficulty, by pursuing two complementary directions: devising scalable verification techniques, and identifying design choices that result in deep learning systems that are more amenable to verification.
Paranom: A Parallel Anomaly Dataset Generator
Jan 09, 2018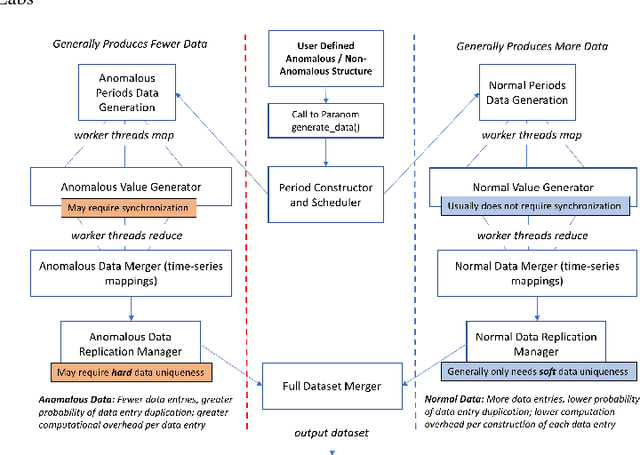
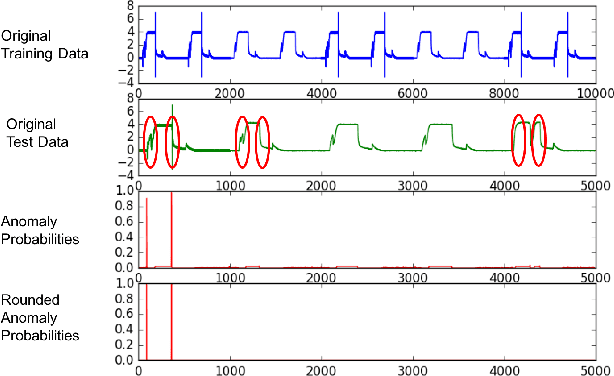
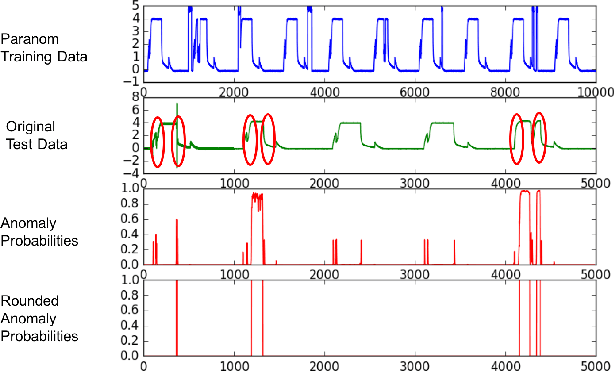

In this paper, we present Paranom, a parallel anomaly dataset generator. We discuss its design and provide brief experimental results demonstrating its usefulness in improving the classification correctness of LSTM-AD, a state-of-the-art anomaly detection model.
AutoPerf: A Generalized Zero-Positive Learning System to Detect Software Performance Anomalies
Nov 19, 2017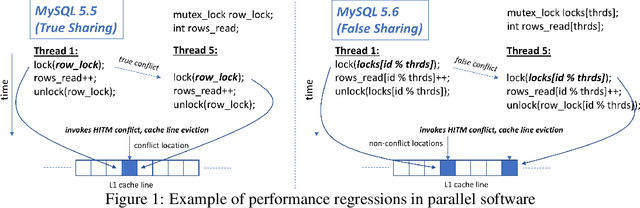
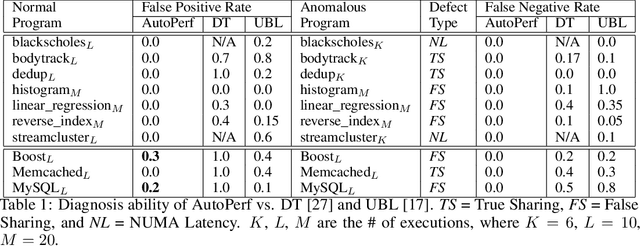
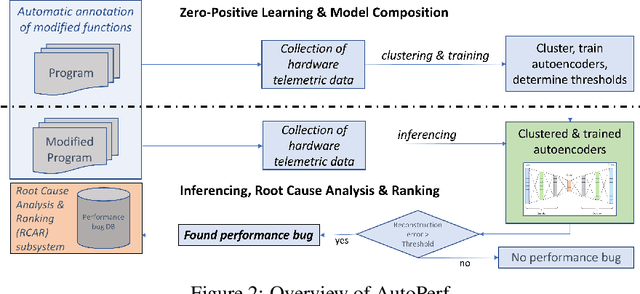
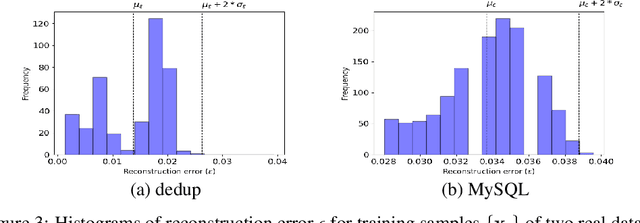
In this paper, we present AutoPerf, a generalized software performance anomaly detection system. AutoPerf uses autoencoders, an unsupervised learning technique, and hardware performance counters to learn the performance signatures of parallel programs. It then uses this knowledge to identify when newer versions of the program suffer performance penalties, while simultaneously providing root cause analysis to help programmers debug the program's performance. AutoPerf is the first zero-positive learning performance anomaly detector, a system that trains entirely in the negative (non-anomalous) space to learn positive (anomalous) behaviors. We demonstrate AutoPerf's generality against three different types of performance anomalies: (i) true sharing cache contention, (ii) false sharing cache contention, and (iii) NUMA latencies across 15 real world performance anomalies and 7 open source programs. AutoPerf has only 3.7% profiling overhead (on average) and detects more anomalies than the prior state-of-the-art approach.
AI Programmer: Autonomously Creating Software Programs Using Genetic Algorithms
Sep 17, 2017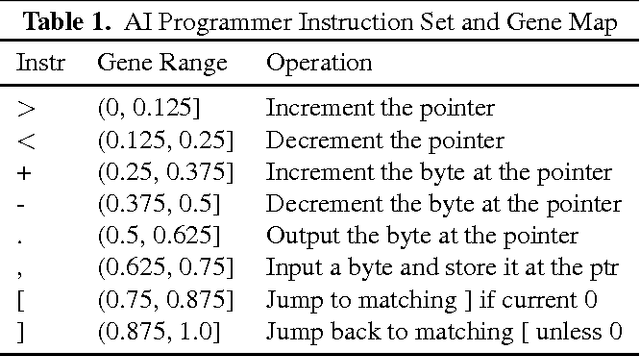
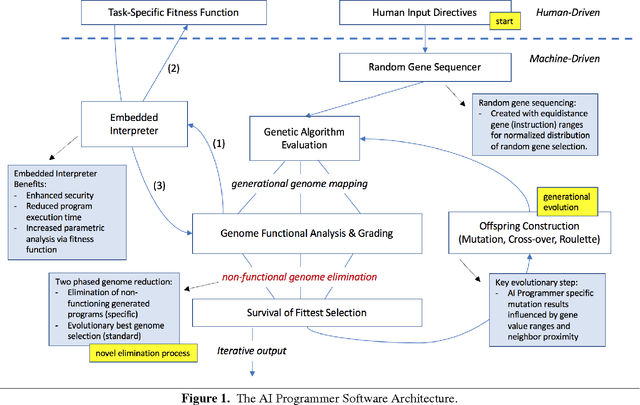
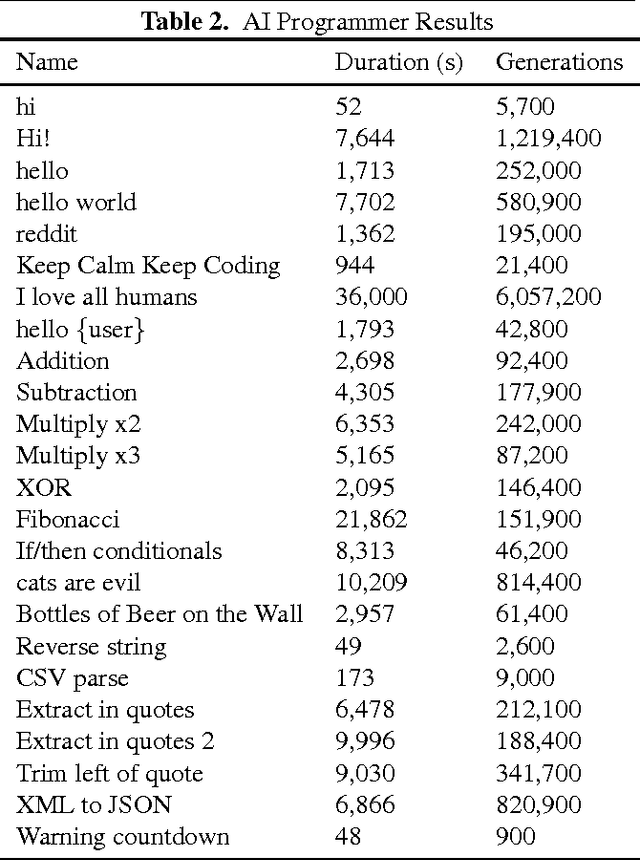
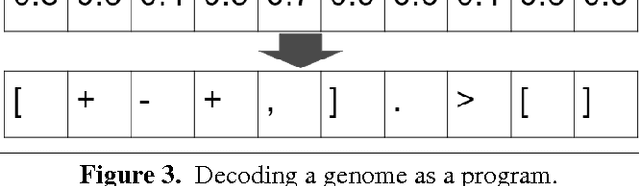
In this paper, we present the first-of-its-kind machine learning (ML) system, called AI Programmer, that can automatically generate full software programs requiring only minimal human guidance. At its core, AI Programmer uses genetic algorithms (GA) coupled with a tightly constrained programming language that minimizes the overhead of its ML search space. Part of AI Programmer's novelty stems from (i) its unique system design, including an embedded, hand-crafted interpreter for efficiency and security and (ii) its augmentation of GAs to include instruction-gene randomization bindings and programming language-specific genome construction and elimination techniques. We provide a detailed examination of AI Programmer's system design, several examples detailing how the system works, and experimental data demonstrating its software generation capabilities and performance using only mainstream CPUs.