 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVPHO: Joint Visual-Physical Cue Learning and Aggregation for Hand-Object Pose Estimation
Nov 15, 2025



Estimating the 3D poses of hands and objects from a single RGB image is a fundamental yet challenging problem, with broad applications in augmented reality and human-computer interaction. Existing methods largely rely on visual cues alone, often producing results that violate physical constraints such as interpenetration or non-contact. Recent efforts to incorporate physics reasoning typically depend on post-optimization or non-differentiable physics engines, which compromise visual consistency and end-to-end trainability. To overcome these limitations, we propose a novel framework that jointly integrates visual and physical cues for hand-object pose estimation. This integration is achieved through two key ideas: 1) joint visual-physical cue learning: The model is trained to extract 2D visual cues and 3D physical cues, thereby enabling more comprehensive representation learning for hand-object interactions; 2) candidate pose aggregation: A novel refinement process that aggregates multiple diffusion-generated candidate poses by leveraging both visual and physical predictions, yielding a final estimate that is visually consistent and physically plausible. Extensive experiments demonstrate that our method significantly outperforms existing state-of-the-art approaches in both pose accuracy and physical plausibility.
Thinker: Training LLMs in Hierarchical Thinking for Deep Search via Multi-Turn Interaction
Nov 14, 2025



Efficient retrieval of external knowledge bases and web pages is crucial for enhancing the reasoning abilities of LLMs. Previous works on training LLMs to leverage external retrievers for solving complex problems have predominantly employed end-to-end reinforcement learning. However, these approaches neglect supervision over the reasoning process, making it difficult to guarantee logical coherence and rigor. To address these limitations, we propose Thinker, a hierarchical thinking model for deep search through multi-turn interaction, making the reasoning process supervisable and verifiable. It decomposes complex problems into independently solvable sub-problems, each dually represented in both natural language and an equivalent logical function to support knowledge base and web searches. Concurrently, dependencies between sub-problems are passed as parameters via these logical functions, enhancing the logical coherence of the problem-solving process. To avoid unnecessary external searches, we perform knowledge boundary determination to check if a sub-problem is within the LLM's intrinsic knowledge, allowing it to answer directly. Experimental results indicate that with as few as several hundred training samples, the performance of Thinker is competitive with established baselines. Furthermore, when scaled to the full training set, Thinker significantly outperforms these methods across various datasets and model sizes. The source code is available at https://github.com/OpenSPG/KAG-Thinker.
ARGenSeg: Image Segmentation with Autoregressive Image Generation Model
Oct 23, 2025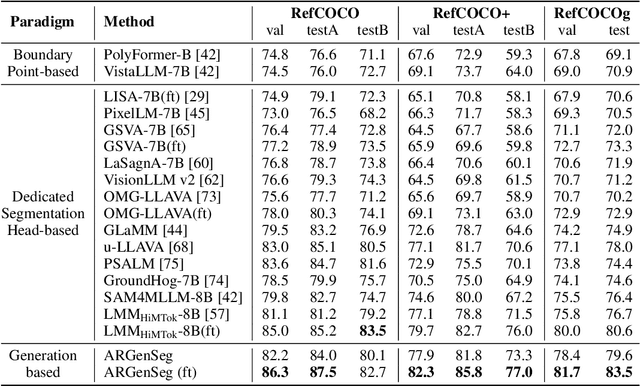
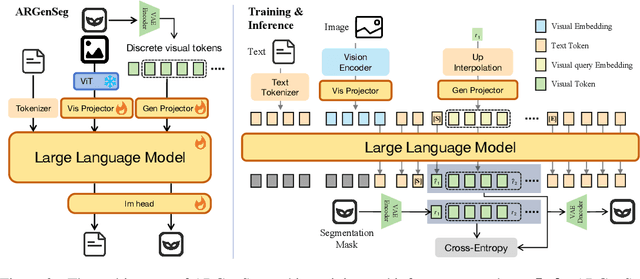


We propose a novel AutoRegressive Generation-based paradigm for image Segmentation (ARGenSeg), achieving multimodal understanding and pixel-level perception within a unified framework. Prior works integrating image segmentation into multimodal large language models (MLLMs) typically employ either boundary points representation or dedicated segmentation heads. These methods rely on discrete representations or semantic prompts fed into task-specific decoders, which limits the ability of the MLLM to capture fine-grained visual details. To address these challenges, we introduce a segmentation framework for MLLM based on image generation, which naturally produces dense masks for target objects. We leverage MLLM to output visual tokens and detokenize them into images using an universal VQ-VAE, making the segmentation fully dependent on the pixel-level understanding of the MLLM. To reduce inference latency, we employ a next-scale-prediction strategy to generate required visual tokens in parallel. Extensive experiments demonstrate that our method surpasses prior state-of-the-art approaches on multiple segmentation datasets with a remarkable boost in inference speed, while maintaining strong understanding capabilities.
PruneHal: Reducing Hallucinations in Multi-modal Large Language Models through Adaptive KV Cache Pruning
Oct 22, 2025While multi-modal large language models (MLLMs) have made significant progress in recent years, the issue of hallucinations remains a major challenge. To mitigate this phenomenon, existing solutions either introduce additional data for further training or incorporate external or internal information during inference. However, these approaches inevitably introduce extra computational costs. In this paper, we observe that hallucinations in MLLMs are strongly associated with insufficient attention allocated to visual tokens. In particular, the presence of redundant visual tokens disperses the model's attention, preventing it from focusing on the most informative ones. As a result, critical visual cues are often under-attended, which in turn exacerbates the occurrence of hallucinations. Building on this observation, we propose \textbf{PruneHal}, a training-free, simple yet effective method that leverages adaptive KV cache pruning to enhance the model's focus on critical visual information, thereby mitigating hallucinations. To the best of our knowledge, we are the first to apply token pruning for hallucination mitigation in MLLMs. Notably, our method don't require additional training and incurs nearly no extra inference cost. Moreover, PruneHal is model-agnostic and can be seamlessly integrated with different decoding strategies, including those specifically designed for hallucination mitigation. We evaluate PruneHal on several widely used hallucination evaluation benchmarks using four mainstream MLLMs, achieving robust and outstanding results that highlight the effectiveness and superiority of our method. Our code will be publicly available.
Every Step Evolves: Scaling Reinforcement Learning for Trillion-Scale Thinking Model
Oct 21, 2025



We present Ring-1T, the first open-source, state-of-the-art thinking model with a trillion-scale parameter. It features 1 trillion total parameters and activates approximately 50 billion per token. Training such models at a trillion-parameter scale introduces unprecedented challenges, including train-inference misalignment, inefficiencies in rollout processing, and bottlenecks in the RL system. To address these, we pioneer three interconnected innovations: (1) IcePop stabilizes RL training via token-level discrepancy masking and clipping, resolving instability from training-inference mismatches; (2) C3PO++ improves resource utilization for long rollouts under a token budget by dynamically partitioning them, thereby obtaining high time efficiency; and (3) ASystem, a high-performance RL framework designed to overcome the systemic bottlenecks that impede trillion-parameter model training. Ring-1T delivers breakthrough results across critical benchmarks: 93.4 on AIME-2025, 86.72 on HMMT-2025, 2088 on CodeForces, and 55.94 on ARC-AGI-v1. Notably, it attains a silver medal-level result on the IMO-2025, underscoring its exceptional reasoning capabilities. By releasing the complete 1T parameter MoE model to the community, we provide the research community with direct access to cutting-edge reasoning capabilities. This contribution marks a significant milestone in democratizing large-scale reasoning intelligence and establishes a new baseline for open-source model performance.
Arrows of Math Reasoning Data Synthesis for Large Language Models: Diversity, Complexity and Correctness
Aug 26, 2025Enhancing the mathematical reasoning of large language models (LLMs) demands high-quality training data, yet conventional methods face critical challenges in scalability, cost, and data reliability. To address these limitations, we propose a novel program-assisted synthesis framework that systematically generates a high-quality mathematical corpus with guaranteed diversity, complexity, and correctness. This framework integrates mathematical knowledge systems and domain-specific tools to create executable programs. These programs are then translated into natural language problem-solution pairs and vetted by a bilateral validation mechanism that verifies solution correctness against program outputs and ensures program-problem consistency. We have generated 12.3 million such problem-solving triples. Experiments demonstrate that models fine-tuned on our data significantly improve their inference capabilities, achieving state-of-the-art performance on several benchmark datasets and showcasing the effectiveness of our synthesis approach.
Towards Greater Leverage: Scaling Laws for Efficient Mixture-of-Experts Language Models
Jul 24, 2025Mixture-of-Experts (MoE) has become a dominant architecture for scaling Large Language Models (LLMs) efficiently by decoupling total parameters from computational cost. However, this decoupling creates a critical challenge: predicting the model capacity of a given MoE configurations (e.g., expert activation ratio and granularity) remains an unresolved problem. To address this gap, we introduce Efficiency Leverage (EL), a metric quantifying the computational advantage of an MoE model over a dense equivalent. We conduct a large-scale empirical study, training over 300 models up to 28B parameters, to systematically investigate the relationship between MoE architectural configurations and EL. Our findings reveal that EL is primarily driven by the expert activation ratio and the total compute budget, both following predictable power laws, while expert granularity acts as a non-linear modulator with a clear optimal range. We integrate these discoveries into a unified scaling law that accurately predicts the EL of an MoE architecture based on its configuration. To validate our derived scaling laws, we designed and trained Ling-mini-beta, a pilot model for Ling-2.0 series with only 0.85B active parameters, alongside a 6.1B dense model for comparison. When trained on an identical 1T high-quality token dataset, Ling-mini-beta matched the performance of the 6.1B dense model while consuming over 7x fewer computational resources, thereby confirming the accuracy of our scaling laws. This work provides a principled and empirically-grounded foundation for the scaling of efficient MoE models.
High-fidelity 3D Gaussian Inpainting: preserving multi-view consistency and photorealistic details
Jul 24, 2025Recent advancements in multi-view 3D reconstruction and novel-view synthesis, particularly through Neural Radiance Fields (NeRF) and 3D Gaussian Splatting (3DGS), have greatly enhanced the fidelity and efficiency of 3D content creation. However, inpainting 3D scenes remains a challenging task due to the inherent irregularity of 3D structures and the critical need for maintaining multi-view consistency. In this work, we propose a novel 3D Gaussian inpainting framework that reconstructs complete 3D scenes by leveraging sparse inpainted views. Our framework incorporates an automatic Mask Refinement Process and region-wise Uncertainty-guided Optimization. Specifically, we refine the inpainting mask using a series of operations, including Gaussian scene filtering and back-projection, enabling more accurate localization of occluded regions and realistic boundary restoration. Furthermore, our Uncertainty-guided Fine-grained Optimization strategy, which estimates the importance of each region across multi-view images during training, alleviates multi-view inconsistencies and enhances the fidelity of fine details in the inpainted results. Comprehensive experiments conducted on diverse datasets demonstrate that our approach outperforms existing state-of-the-art methods in both visual quality and view consistency.
WSM: Decay-Free Learning Rate Schedule via Checkpoint Merging for LLM Pre-training
Jul 23, 2025Recent advances in learning rate (LR) scheduling have demonstrated the effectiveness of decay-free approaches that eliminate the traditional decay phase while maintaining competitive performance. Model merging techniques have emerged as particularly promising solutions in this domain. We present Warmup-Stable and Merge (WSM), a general framework that establishes a formal connection between learning rate decay and model merging. WSM provides a unified theoretical foundation for emulating various decay strategies-including cosine decay, linear decay and inverse square root decay-as principled model averaging schemes, while remaining fully compatible with diverse optimization methods. Through extensive experiments, we identify merge duration-the training window for checkpoint aggregation-as the most critical factor influencing model performance, surpassing the importance of both checkpoint interval and merge quantity. Our framework consistently outperforms the widely-adopted Warmup-Stable-Decay (WSD) approach across multiple benchmarks, achieving significant improvements of +3.5% on MATH, +2.9% on HumanEval, and +5.5% on MMLU-Pro. The performance advantages extend to supervised fine-tuning scenarios, highlighting WSM's potential for long-term model refinement.
MaskedCLIP: Bridging the Masked and CLIP Space for Semi-Supervised Medical Vision-Language Pre-training
Jul 23, 2025Foundation models have recently gained tremendous popularity in medical image analysis. State-of-the-art methods leverage either paired image-text data via vision-language pre-training or unpaired image data via self-supervised pre-training to learn foundation models with generalizable image features to boost downstream task performance. However, learning foundation models exclusively on either paired or unpaired image data limits their ability to learn richer and more comprehensive image features. In this paper, we investigate a novel task termed semi-supervised vision-language pre-training, aiming to fully harness the potential of both paired and unpaired image data for foundation model learning. To this end, we propose MaskedCLIP, a synergistic masked image modeling and contrastive language-image pre-training framework for semi-supervised vision-language pre-training. The key challenge in combining paired and unpaired image data for learning a foundation model lies in the incompatible feature spaces derived from these two types of data. To address this issue, we propose to connect the masked feature space with the CLIP feature space with a bridge transformer. In this way, the more semantic specific CLIP features can benefit from the more general masked features for semantic feature extraction. We further propose a masked knowledge distillation loss to distill semantic knowledge of original image features in CLIP feature space back to the predicted masked image features in masked feature space. With this mutually interactive design, our framework effectively leverages both paired and unpaired image data to learn more generalizable image features for downstream tasks. Extensive experiments on retinal image analysis demonstrate the effectiveness and data efficiency of our method.