 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Non-Core Language Instruction-Following in Speech LLMs via Semi-Implicit Cross-Lingual CoT Reasoning
Apr 29, 2025



Large language models have been extended to the speech domain, leading to the development of speech large language models (SLLMs). While existing SLLMs demonstrate strong performance in speech instruction-following for core languages (e.g., English), they often struggle with non-core languages due to the scarcity of paired speech-text data and limited multilingual semantic reasoning capabilities. To address this, we propose the semi-implicit Cross-lingual Speech Chain-of-Thought (XS-CoT) framework, which integrates speech-to-text translation into the reasoning process of SLLMs. The XS-CoT generates four types of tokens: instruction and response tokens in both core and non-core languages, enabling cross-lingual transfer of reasoning capabilities. To mitigate inference latency in generating target non-core response tokens, we incorporate a semi-implicit CoT scheme into XS-CoT, which progressively compresses the first three types of intermediate reasoning tokens while retaining global reasoning logic during training. By leveraging the robust reasoning capabilities of the core language, XS-CoT improves responses for non-core languages by up to 45\% in GPT-4 score when compared to direct supervised fine-tuning on two representative SLLMs, Qwen2-Audio and SALMONN. Moreover, the semi-implicit XS-CoT reduces token delay by more than 50\% with a slight drop in GPT-4 scores. Importantly, XS-CoT requires only a small amount of high-quality training data for non-core languages by leveraging the reasoning capabilities of core languages. To support training, we also develop a data pipeline and open-source speech instruction-following datasets in Japanese, German, and French.
CHASe: Client Heterogeneity-Aware Data Selection for Effective Federated Active Learning
Apr 24, 2025



Active learning (AL) reduces human annotation costs for machine learning systems by strategically selecting the most informative unlabeled data for annotation, but performing it individually may still be insufficient due to restricted data diversity and annotation budget. Federated Active Learning (FAL) addresses this by facilitating collaborative data selection and model training, while preserving the confidentiality of raw data samples. Yet, existing FAL methods fail to account for the heterogeneity of data distribution across clients and the associated fluctuations in global and local model parameters, adversely affecting model accuracy. To overcome these challenges, we propose CHASe (Client Heterogeneity-Aware Data Selection), specifically designed for FAL. CHASe focuses on identifying those unlabeled samples with high epistemic variations (EVs), which notably oscillate around the decision boundaries during training. To achieve both effectiveness and efficiency, \model{} encompasses techniques for 1) tracking EVs by analyzing inference inconsistencies across training epochs, 2) calibrating decision boundaries of inaccurate models with a new alignment loss, and 3) enhancing data selection efficiency via a data freeze and awaken mechanism with subset sampling. Experiments show that CHASe surpasses various established baselines in terms of effectiveness and efficiency, validated across diverse datasets, model complexities, and heterogeneous federation settings.
Advancing CMA-ES with Learning-Based Cooperative Coevolution for Scalable Optimization
Apr 24, 2025Recent research in Cooperative Coevolution~(CC) have achieved promising progress in solving large-scale global optimization problems. However, existing CC paradigms have a primary limitation in that they require deep expertise for selecting or designing effective variable decomposition strategies. Inspired by advancements in Meta-Black-Box Optimization, this paper introduces LCC, a pioneering learning-based cooperative coevolution framework that dynamically schedules decomposition strategies during optimization processes. The decomposition strategy selector is parameterized through a neural network, which processes a meticulously crafted set of optimization status features to determine the optimal strategy for each optimization step. The network is trained via the Proximal Policy Optimization method in a reinforcement learning manner across a collection of representative problems, aiming to maximize the expected optimization performance. Extensive experimental results demonstrate that LCC not only offers certain advantages over state-of-the-art baselines in terms of optimization effectiveness and resource consumption, but it also exhibits promising transferability towards unseen problems.
HMI: Hierarchical Knowledge Management for Efficient Multi-Tenant Inference in Pretrained Language Models
Apr 24, 2025The significant computational demands of pretrained language models (PLMs), which often require dedicated hardware, present a substantial challenge in serving them efficiently, especially in multi-tenant environments. To address this, we introduce HMI, a Hierarchical knowledge management-based Multi-tenant Inference system, designed to manage tenants with distinct PLMs resource-efficiently. Our approach is three-fold: Firstly, we categorize PLM knowledge into general, domain-specific, and task-specific. Leveraging insights on knowledge acquisition across different model layers, we construct hierarchical PLMs (hPLMs) by extracting and storing knowledge at different levels, significantly reducing GPU memory usage per tenant. Secondly, we establish hierarchical knowledge management for hPLMs generated by various tenants in HMI. We manage domain-specific knowledge with acceptable storage increases by constructing and updating domain-specific knowledge trees based on frequency. We manage task-specific knowledge within limited GPU memory through parameter swapping. Finally, we propose system optimizations to enhance resource utilization and inference throughput. These include fine-grained pipelining via hierarchical knowledge prefetching to overlap CPU and I/O operations with GPU computations, and optimizing parallel implementations with batched matrix multiplications. Our experimental results demonstrate that the proposed HMI can efficiently serve up to 10,000 hPLMs (hBERTs and hGPTs) on a single GPU, with only a negligible compromise in accuracy.
AI for CSI Prediction in 5G-Advanced and Beyond
Apr 17, 2025Artificial intelligence (AI) is pivotal in advancing fifth-generation (5G)-Advanced and sixth-generation systems, capturing substantial research interest. Both the 3rd Generation Partnership Project (3GPP) and leading corporations champion AI's standardization in wireless communication. This piece delves into AI's role in channel state information (CSI) prediction, a sub-use case acknowledged in 5G-Advanced by the 3GPP. We offer an exhaustive survey of AI-driven CSI prediction, highlighting crucial elements like accuracy, generalization, and complexity. Further, we touch on the practical side of model management, encompassing training, monitoring, and data gathering. Moreover, we explore prospects for CSI prediction in future wireless communication systems, entailing integrated design with feedback, multitasking synergy, and predictions in rapid scenarios. This article seeks to be a touchstone for subsequent research in this burgeoning domain.
On the Feasibility of Using MultiModal LLMs to Execute AR Social Engineering Attacks
Apr 16, 2025Augmented Reality (AR) and Multimodal Large Language Models (LLMs) are rapidly evolving, providing unprecedented capabilities for human-computer interaction. However, their integration introduces a new attack surface for social engineering. In this paper, we systematically investigate the feasibility of orchestrating AR-driven Social Engineering attacks using Multimodal LLM for the first time, via our proposed SEAR framework, which operates through three key phases: (1) AR-based social context synthesis, which fuses Multimodal inputs (visual, auditory and environmental cues); (2) role-based Multimodal RAG (Retrieval-Augmented Generation), which dynamically retrieves and integrates contextual data while preserving character differentiation; and (3) ReInteract social engineering agents, which execute adaptive multiphase attack strategies through inference interaction loops. To verify SEAR, we conducted an IRB-approved study with 60 participants in three experimental configurations (unassisted, AR+LLM, and full SEAR pipeline) compiling a new dataset of 180 annotated conversations in simulated social scenarios. Our results show that SEAR is highly effective at eliciting high-risk behaviors (e.g., 93.3% of participants susceptible to email phishing). The framework was particularly effective in building trust, with 85% of targets willing to accept an attacker's call after an interaction. Also, we identified notable limitations such as ``occasionally artificial'' due to perceived authenticity gaps. This work provides proof-of-concept for AR-LLM driven social engineering attacks and insights for developing defensive countermeasures against next-generation augmented reality threats.
ICG-MVSNet: Learning Intra-view and Cross-view Relationships for Guidance in Multi-View Stereo
Mar 27, 2025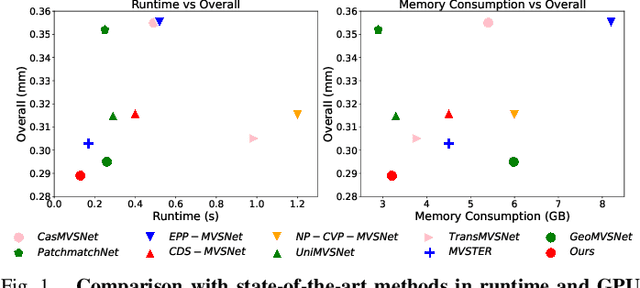
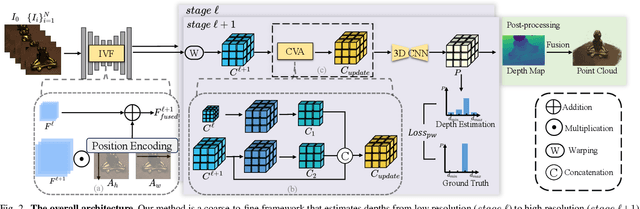
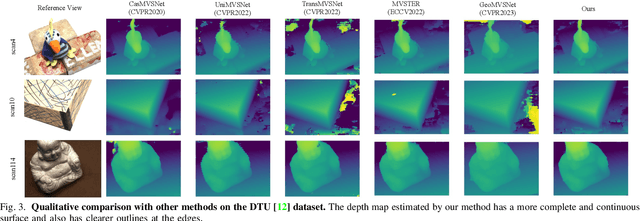

Multi-view Stereo (MVS) aims to estimate depth and reconstruct 3D point clouds from a series of overlapping images. Recent learning-based MVS frameworks overlook the geometric information embedded in features and correlations, leading to weak cost matching. In this paper, we propose ICG-MVSNet, which explicitly integrates intra-view and cross-view relationships for depth estimation. Specifically, we develop an intra-view feature fusion module that leverages the feature coordinate correlations within a single image to enhance robust cost matching. Additionally, we introduce a lightweight cross-view aggregation module that efficiently utilizes the contextual information from volume correlations to guide regularization. Our method is evaluated on the DTU dataset and Tanks and Temples benchmark, consistently achieving competitive performance against state-of-the-art works, while requiring lower computational resources.
QualiSpeech: A Speech Quality Assessment Dataset with Natural Language Reasoning and Descriptions
Mar 26, 2025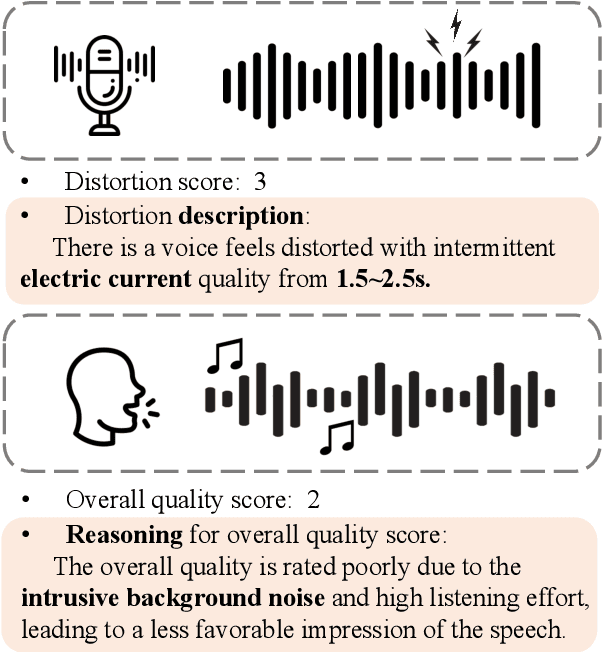
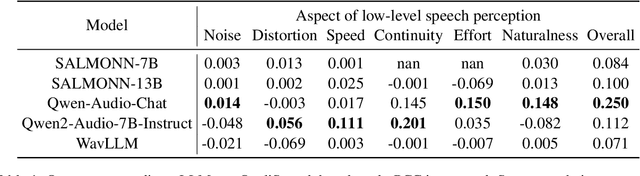
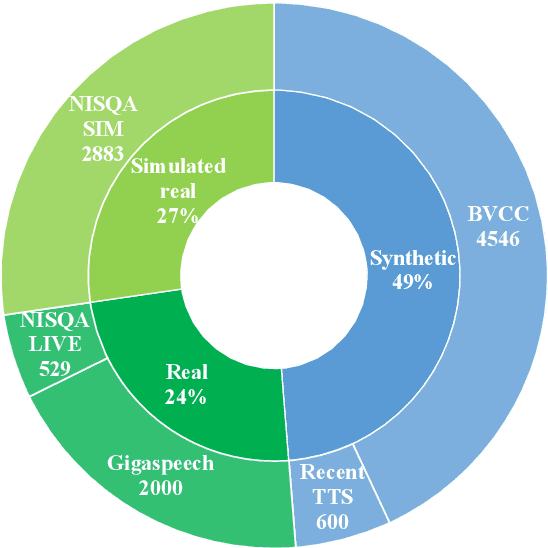
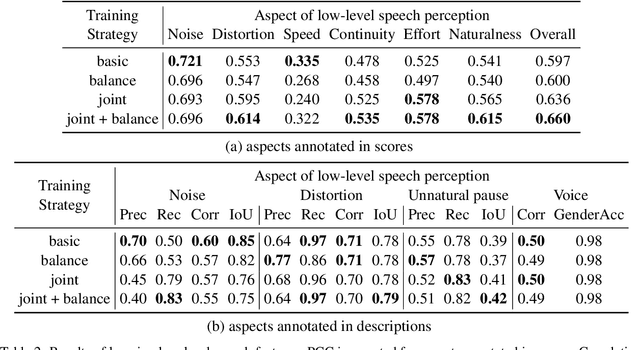
This paper explores a novel perspective to speech quality assessment by leveraging natural language descriptions, offering richer, more nuanced insights than traditional numerical scoring methods. Natural language feedback provides instructive recommendations and detailed evaluations, yet existing datasets lack the comprehensive annotations needed for this approach. To bridge this gap, we introduce QualiSpeech, a comprehensive low-level speech quality assessment dataset encompassing 11 key aspects and detailed natural language comments that include reasoning and contextual insights. Additionally, we propose the QualiSpeech Benchmark to evaluate the low-level speech understanding capabilities of auditory large language models (LLMs). Experimental results demonstrate that finetuned auditory LLMs can reliably generate detailed descriptions of noise and distortion, effectively identifying their types and temporal characteristics. The results further highlight the potential for incorporating reasoning to enhance the accuracy and reliability of quality assessments. The dataset will be released at https://huggingface.co/datasets/tsinghua-ee/QualiSpeech.
Mutual Information-Empowered Task-Oriented Communication: Principles, Applications and Challenges
Mar 26, 2025


Mutual information (MI)-based guidelines have recently proven to be effective for designing task-oriented communication systems, where the ultimate goal is to extract and transmit task-relevant information for downstream task. This paper provides a comprehensive overview of MI-empowered task-oriented communication, highlighting how MI-based methods can serve as a unifying design framework in various task-oriented communication scenarios. We begin with the roadmap of MI for designing task-oriented communication systems, and then introduce the roles and applications of MI to guide feature encoding, transmission optimization, and efficient training with two case studies. We further elaborate the limitations and challenges of MI-based methods. Finally, we identify several open issues in MI-based task-oriented communication to inspire future research.
AdaWorld: Learning Adaptable World Models with Latent Actions
Mar 24, 2025World models aim to learn action-controlled prediction models and have proven essential for the development of intelligent agents. However, most existing world models rely heavily on substantial action-labeled data and costly training, making it challenging to adapt to novel environments with heterogeneous actions through limited interactions. This limitation can hinder their applicability across broader domains. To overcome this challenge, we propose AdaWorld, an innovative world model learning approach that enables efficient adaptation. The key idea is to incorporate action information during the pretraining of world models. This is achieved by extracting latent actions from videos in a self-supervised manner, capturing the most critical transitions between frames. We then develop an autoregressive world model that conditions on these latent actions. This learning paradigm enables highly adaptable world models, facilitating efficient transfer and learning of new actions even with limited interactions and finetuning. Our comprehensive experiments across multiple environments demonstrate that AdaWorld achieves superior performance in both simulation quality and visual planning.