 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelective Invocation for Multilingual ASR: A Cost-effective Approach Adapting to Speech Recognition Difficulty
May 22, 2025Although multilingual automatic speech recognition (ASR) systems have significantly advanced, enabling a single model to handle multiple languages, inherent linguistic differences and data imbalances challenge SOTA performance across all languages. While language identification (LID) models can route speech to the appropriate ASR model, they incur high costs from invoking SOTA commercial models and suffer from inaccuracies due to misclassification. To overcome these, we propose SIMA, a selective invocation for multilingual ASR that adapts to the difficulty level of the input speech. Built on a spoken large language model (SLLM), SIMA evaluates whether the input is simple enough for direct transcription or requires the invocation of a SOTA ASR model. Our approach reduces word error rates by 18.7% compared to the SLLM and halves invocation costs compared to LID-based methods. Tests on three datasets show that SIMA is a scalable, cost-effective solution for multilingual ASR applications.
Enhancing Non-Core Language Instruction-Following in Speech LLMs via Semi-Implicit Cross-Lingual CoT Reasoning
Apr 29, 2025



Large language models have been extended to the speech domain, leading to the development of speech large language models (SLLMs). While existing SLLMs demonstrate strong performance in speech instruction-following for core languages (e.g., English), they often struggle with non-core languages due to the scarcity of paired speech-text data and limited multilingual semantic reasoning capabilities. To address this, we propose the semi-implicit Cross-lingual Speech Chain-of-Thought (XS-CoT) framework, which integrates speech-to-text translation into the reasoning process of SLLMs. The XS-CoT generates four types of tokens: instruction and response tokens in both core and non-core languages, enabling cross-lingual transfer of reasoning capabilities. To mitigate inference latency in generating target non-core response tokens, we incorporate a semi-implicit CoT scheme into XS-CoT, which progressively compresses the first three types of intermediate reasoning tokens while retaining global reasoning logic during training. By leveraging the robust reasoning capabilities of the core language, XS-CoT improves responses for non-core languages by up to 45\% in GPT-4 score when compared to direct supervised fine-tuning on two representative SLLMs, Qwen2-Audio and SALMONN. Moreover, the semi-implicit XS-CoT reduces token delay by more than 50\% with a slight drop in GPT-4 scores. Importantly, XS-CoT requires only a small amount of high-quality training data for non-core languages by leveraging the reasoning capabilities of core languages. To support training, we also develop a data pipeline and open-source speech instruction-following datasets in Japanese, German, and French.
HMM-Free Encoder Pre-Training for Streaming RNN Transducer
Apr 02, 2021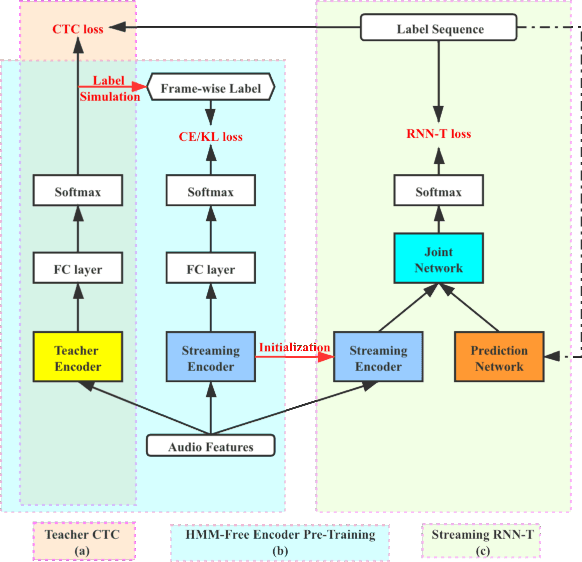
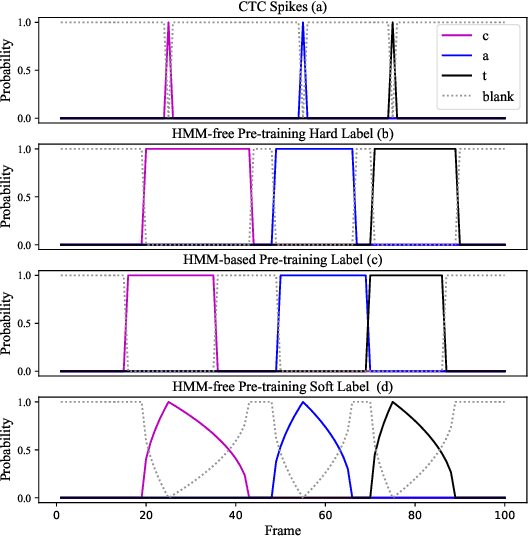
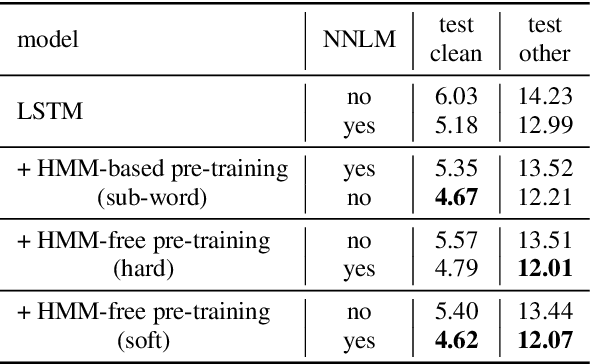
This work describes an encoder pre-training procedure using frame-wise label to improve the training of streaming recurrent neural network transducer (RNN-T) model. Streaming RNN-T trained from scratch usually performs worse and has high latency. Although it is common to address these issues through pre-training components of RNN-T with other criteria or frame-wise alignment guidance, the alignment is not easily available in end-to-end manner. In this work, frame-wise alignment, used to pre-train streaming RNN-T's encoder, is generated without using a HMM-based system. Therefore an all-neural framework equipping HMM-free encoder pre-training is constructed. This is achieved by expanding the spikes of CTC model to their left/right blank frames, and two expanding strategies are proposed. To our best knowledge, this is the first work to simulate HMM-based frame-wise label using CTC model. Experiments conducted on LibriSpeech and MLS English tasks show the proposed pre-training procedure, compared with random initialization, reduces the WER by relatively 5%~11% and the emission latency by 60 ms. Besides, the method is lexicon-free, so it is friendly to new languages without manually designed lexicon.