 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Category-level Articulated Object Pose Tracking on SE(3) Manifolds
Nov 08, 2025Articulated objects are prevalent in daily life and robotic manipulation tasks. However, compared to rigid objects, pose tracking for articulated objects remains an underexplored problem due to their inherent kinematic constraints. To address these challenges, this work proposes a novel point-pair-based pose tracking framework, termed \textbf{PPF-Tracker}. The proposed framework first performs quasi-canonicalization of point clouds in the SE(3) Lie group space, and then models articulated objects using Point Pair Features (PPF) to predict pose voting parameters by leveraging the invariance properties of SE(3). Finally, semantic information of joint axes is incorporated to impose unified kinematic constraints across all parts of the articulated object. PPF-Tracker is systematically evaluated on both synthetic datasets and real-world scenarios, demonstrating strong generalization across diverse and challenging environments. Experimental results highlight the effectiveness and robustness of PPF-Tracker in multi-frame pose tracking of articulated objects. We believe this work can foster advances in robotics, embodied intelligence, and augmented reality. Codes are available at https://github.com/mengxh20/PPFTracker.
An Automated Theorem Generator with Theoretical Foundation Based on Rectangular Standard Contradiction
Nov 06, 2025Currently, there is a lack of rigorous theoretical system for systematically generating non-trivial and logically valid theorems. Addressing this critical gap, this paper conducts research to propose a novel automated theorem generation theory and tool. Based on the concept of standard contradiction which possesses unique deductive advantages, this paper defines and proves, for the first time, a new logical structure known as rectangular standard contradiction. Centered on this structure, a complete Automated Theorem Generation (ATG) theory is put forward. Theoretical proofs clarify two core properties of rectangular standard contradiction: first, it is a standard contradiction (necessarily unsatisfiable); second, it exhibits non-redundancy (the remaining clause set becomes satisfiable after removing any clause). Leveraging these properties, this paper proves that partitioning a rectangular standard contradiction into a premise subset $A$ and negation of its complement $H$, a valid theorem $A \vdash \neg H$ can be formed, and all such theorems are logically equivalent. To implement this theory, an efficient template-based ATG algorithm is designed, and a Rectangular Automated Theorem Generator is developed. This research enables machines to transition from "verifiers" to "discoverers", opening up new avenues for fundamental research in the fields of logic and artificial intelligence.
Towards Fine-Grained Vision-Language Alignment for Few-Shot Anomaly Detection
Oct 30, 2025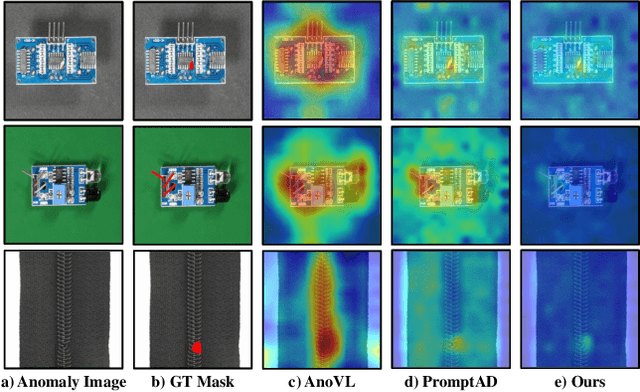
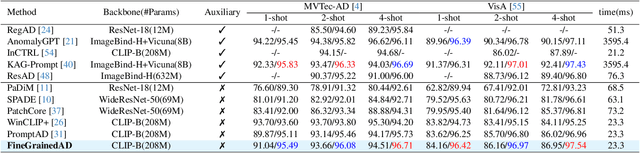
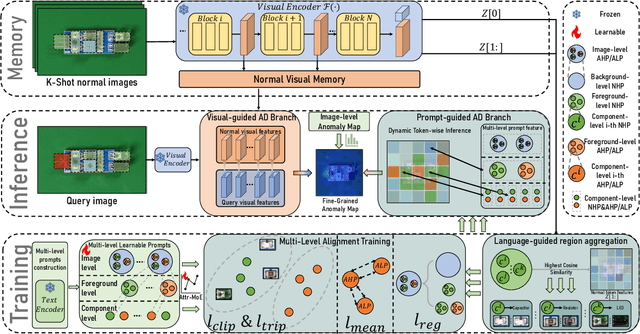
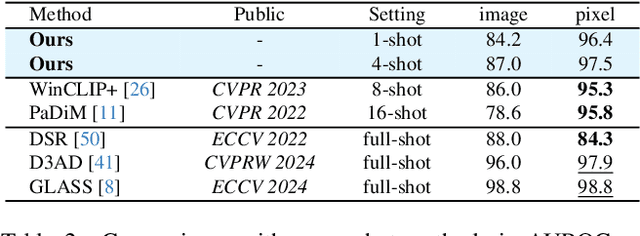
Few-shot anomaly detection (FSAD) methods identify anomalous regions with few known normal samples. Most existing methods rely on the generalization ability of pre-trained vision-language models (VLMs) to recognize potentially anomalous regions through feature similarity between text descriptions and images. However, due to the lack of detailed textual descriptions, these methods can only pre-define image-level descriptions to match each visual patch token to identify potential anomalous regions, which leads to the semantic misalignment between image descriptions and patch-level visual anomalies, achieving sub-optimal localization performance. To address the above issues, we propose the Multi-Level Fine-Grained Semantic Caption (MFSC) to provide multi-level and fine-grained textual descriptions for existing anomaly detection datasets with automatic construction pipeline. Based on the MFSC, we propose a novel framework named FineGrainedAD to improve anomaly localization performance, which consists of two components: Multi-Level Learnable Prompt (MLLP) and Multi-Level Semantic Alignment (MLSA). MLLP introduces fine-grained semantics into multi-level learnable prompts through automatic replacement and concatenation mechanism, while MLSA designs region aggregation strategy and multi-level alignment training to facilitate learnable prompts better align with corresponding visual regions. Experiments demonstrate that the proposed FineGrainedAD achieves superior overall performance in few-shot settings on MVTec-AD and VisA datasets.
CoFFT: Chain of Foresight-Focus Thought for Visual Language Models
Sep 26, 2025Despite significant advances in Vision Language Models (VLMs), they remain constrained by the complexity and redundancy of visual input. When images contain large amounts of irrelevant information, VLMs are susceptible to interference, thus generating excessive task-irrelevant reasoning processes or even hallucinations. This limitation stems from their inability to discover and process the required regions during reasoning precisely. To address this limitation, we present the Chain of Foresight-Focus Thought (CoFFT), a novel training-free approach that enhances VLMs' visual reasoning by emulating human visual cognition. Each Foresight-Focus Thought consists of three stages: (1) Diverse Sample Generation: generates diverse reasoning samples to explore potential reasoning paths, where each sample contains several reasoning steps; (2) Dual Foresight Decoding: rigorously evaluates these samples based on both visual focus and reasoning progression, adding the first step of optimal sample to the reasoning process; (3) Visual Focus Adjustment: precisely adjust visual focus toward regions most beneficial for future reasoning, before returning to stage (1) to generate subsequent reasoning samples until reaching the final answer. These stages function iteratively, creating an interdependent cycle where reasoning guides visual focus and visual focus informs subsequent reasoning. Empirical results across multiple benchmarks using Qwen2.5-VL, InternVL-2.5, and Llava-Next demonstrate consistent performance improvements of 3.1-5.8\% with controllable increasing computational overhead.
Dual-Scale Volume Priors with Wasserstein-Based Consistency for Semi-Supervised Medical Image Segmentation
Sep 04, 2025Despite signi cant progress in semi-supervised medical image segmentation, most existing segmentation networks overlook e ective methodological guidance for feature extraction and important prior information from datasets. In this paper, we develop a semi-supervised medical image segmentation framework that e ectively integrates spatial regularization methods and volume priors. Speci cally, our approach integrates a strong explicit volume prior at the image scale and Threshold Dynamics spatial regularization, both derived from variational models, into the backbone segmentation network. The target region volumes for each unlabeled image are estimated by a regression network, which e ectively regularizes the backbone segmentation network through an image-scale Wasserstein distance constraint, ensuring that the class ratios in the segmentation results for each unlabeled image match those predicted by the regression network. Additionally, we design a dataset-scale Wasserstein distance loss function based on a weak implicit volume prior, which enforces that the volume distribution predicted for the unlabeled dataset is similar to that of labeled dataset. Experimental results on the 2017 ACDC dataset, PROMISE12 dataset, and thigh muscle MR image dataset show the superiority of the proposed method.
LLM-based Agentic Reasoning Frameworks: A Survey from Methods to Scenarios
Aug 25, 2025Recent advances in the intrinsic reasoning capabilities of large language models (LLMs) have given rise to LLM-based agent systems that exhibit near-human performance on a variety of automated tasks. However, although these systems share similarities in terms of their use of LLMs, different reasoning frameworks of the agent system steer and organize the reasoning process in different ways. In this survey, we propose a systematic taxonomy that decomposes agentic reasoning frameworks and analyze how these frameworks dominate framework-level reasoning by comparing their applications across different scenarios. Specifically, we propose an unified formal language to further classify agentic reasoning systems into single-agent methods, tool-based methods, and multi-agent methods. After that, we provide a comprehensive review of their key application scenarios in scientific discovery, healthcare, software engineering, social simulation, and economics. We also analyze the characteristic features of each framework and summarize different evaluation strategies. Our survey aims to provide the research community with a panoramic view to facilitate understanding of the strengths, suitable scenarios, and evaluation practices of different agentic reasoning frameworks.
TSLA: A Task-Specific Learning Adaptation for Semantic Segmentation on Autonomous Vehicles Platform
Aug 17, 2025



Autonomous driving platforms encounter diverse driving scenarios, each with varying hardware resources and precision requirements. Given the computational limitations of embedded devices, it is crucial to consider computing costs when deploying on target platforms like the NVIDIA\textsuperscript{\textregistered} DRIVE PX 2. Our objective is to customize the semantic segmentation network according to the computing power and specific scenarios of autonomous driving hardware. We implement dynamic adaptability through a three-tier control mechanism -- width multiplier, classifier depth, and classifier kernel -- allowing fine-grained control over model components based on hardware constraints and task requirements. This adaptability facilitates broad model scaling, targeted refinement of the final layers, and scenario-specific optimization of kernel sizes, leading to improved resource allocation and performance. Additionally, we leverage Bayesian Optimization with surrogate modeling to efficiently explore hyperparameter spaces under tight computational budgets. Our approach addresses scenario-specific and task-specific requirements through automatic parameter search, accommodating the unique computational complexity and accuracy needs of autonomous driving. It scales its Multiply-Accumulate Operations (MACs) for Task-Specific Learning Adaptation (TSLA), resulting in alternative configurations tailored to diverse self-driving tasks. These TSLA customizations maximize computational capacity and model accuracy, optimizing hardware utilization.
SGDFuse: SAM-Guided Diffusion for High-Fidelity Infrared and Visible Image Fusion
Aug 07, 2025Infrared and visible image fusion (IVIF) aims to combine the thermal radiation information from infrared images with the rich texture details from visible images to enhance perceptual capabilities for downstream visual tasks. However, existing methods often fail to preserve key targets due to a lack of deep semantic understanding of the scene, while the fusion process itself can also introduce artifacts and detail loss, severely compromising both image quality and task performance. To address these issues, this paper proposes SGDFuse, a conditional diffusion model guided by the Segment Anything Model (SAM), to achieve high-fidelity and semantically-aware image fusion. The core of our method is to utilize high-quality semantic masks generated by SAM as explicit priors to guide the optimization of the fusion process via a conditional diffusion model. Specifically, the framework operates in a two-stage process: it first performs a preliminary fusion of multi-modal features, and then utilizes the semantic masks from SAM jointly with the preliminary fused image as a condition to drive the diffusion model's coarse-to-fine denoising generation. This ensures the fusion process not only has explicit semantic directionality but also guarantees the high fidelity of the final result. Extensive experiments demonstrate that SGDFuse achieves state-of-the-art performance in both subjective and objective evaluations, as well as in its adaptability to downstream tasks, providing a powerful solution to the core challenges in image fusion. The code of SGDFuse is available at https://github.com/boshizhang123/SGDFuse.
RCR-Router: Efficient Role-Aware Context Routing for Multi-Agent LLM Systems with Structured Memory
Aug 06, 2025Multi-agent large language model (LLM) systems have shown strong potential in complex reasoning and collaborative decision-making tasks. However, most existing coordination schemes rely on static or full-context routing strategies, which lead to excessive token consumption, redundant memory exposure, and limited adaptability across interaction rounds. We introduce RCR-Router, a modular and role-aware context routing framework designed to enable efficient, adaptive collaboration in multi-agent LLMs. To our knowledge, this is the first routing approach that dynamically selects semantically relevant memory subsets for each agent based on its role and task stage, while adhering to a strict token budget. A lightweight scoring policy guides memory selection, and agent outputs are iteratively integrated into a shared memory store to facilitate progressive context refinement. To better evaluate model behavior, we further propose an Answer Quality Score metric that captures LLM-generated explanations beyond standard QA accuracy. Experiments on three multi-hop QA benchmarks -- HotPotQA, MuSiQue, and 2WikiMultihop -- demonstrate that RCR-Router reduces token usage (up to 30%) while improving or maintaining answer quality. These results highlight the importance of structured memory routing and output-aware evaluation in advancing scalable multi-agent LLM systems.
Modality-Aware Feature Matching: A Comprehensive Review of Single- and Cross-Modality Techniques
Jul 30, 2025



Feature matching is a cornerstone task in computer vision, essential for applications such as image retrieval, stereo matching, 3D reconstruction, and SLAM. This survey comprehensively reviews modality-based feature matching, exploring traditional handcrafted methods and emphasizing contemporary deep learning approaches across various modalities, including RGB images, depth images, 3D point clouds, LiDAR scans, medical images, and vision-language interactions. Traditional methods, leveraging detectors like Harris corners and descriptors such as SIFT and ORB, demonstrate robustness under moderate intra-modality variations but struggle with significant modality gaps. Contemporary deep learning-based methods, exemplified by detector-free strategies like CNN-based SuperPoint and transformer-based LoFTR, substantially improve robustness and adaptability across modalities. We highlight modality-aware advancements, such as geometric and depth-specific descriptors for depth images, sparse and dense learning methods for 3D point clouds, attention-enhanced neural networks for LiDAR scans, and specialized solutions like the MIND descriptor for complex medical image matching. Cross-modal applications, particularly in medical image registration and vision-language tasks, underscore the evolution of feature matching to handle increasingly diverse data interactions.