 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCA$^2$T-Net: Category-Agnostic 3D Articulation Transfer from Single Image
Jan 05, 2023



We present a neural network approach to transfer the motion from a single image of an articulated object to a rest-state (i.e., unarticulated) 3D model. Our network learns to predict the object's pose, part segmentation, and corresponding motion parameters to reproduce the articulation shown in the input image. The network is composed of three distinct branches that take a shared joint image-shape embedding and is trained end-to-end. Unlike previous methods, our approach is independent of the topology of the object and can work with objects from arbitrary categories. Our method, trained with only synthetic data, can be used to automatically animate a mesh, infer motion from real images, and transfer articulation to functionally similar but geometrically distinct 3D models at test time.
Does unsupervised grammar induction need pixels?
Dec 20, 2022Are extralinguistic signals such as image pixels crucial for inducing constituency grammars? While past work has shown substantial gains from multimodal cues, we investigate whether such gains persist in the presence of rich information from large language models (LLMs). We find that our approach, LLM-based C-PCFG (LC-PCFG), outperforms previous multi-modal methods on the task of unsupervised constituency parsing, achieving state-of-the-art performance on a variety of datasets. Moreover, LC-PCFG results in an over 50% reduction in parameter count, and speedups in training time of 1.7x for image-aided models and more than 5x for video-aided models, respectively. These results challenge the notion that extralinguistic signals such as image pixels are needed for unsupervised grammar induction, and point to the need for better text-only baselines in evaluating the need of multi-modality for the task.
MAViL: Masked Audio-Video Learners
Dec 15, 2022



We present Masked Audio-Video Learners (MAViL) to train audio-visual representations. Our approach learns with three complementary forms of self-supervision: (1) reconstruction of masked audio and video input data, (2) intra- and inter-modal contrastive learning with masking, and (3) self-training by reconstructing joint audio-video contextualized features learned from the first two objectives. Pre-training with MAViL not only enables the model to perform well in audio-visual classification and retrieval tasks but also improves representations of each modality in isolation, without using information from the other modality for fine-tuning or inference. Empirically, MAViL sets a new state-of-the-art on AudioSet (53.1 mAP) and VGGSound (67.1% accuracy). For the first time, a self-supervised audio-visual model outperforms ones that use external supervision on these benchmarks. Code will be available soon.
Navigating to Objects in the Real World
Dec 02, 2022Semantic navigation is necessary to deploy mobile robots in uncontrolled environments like our homes, schools, and hospitals. Many learning-based approaches have been proposed in response to the lack of semantic understanding of the classical pipeline for spatial navigation, which builds a geometric map using depth sensors and plans to reach point goals. Broadly, end-to-end learning approaches reactively map sensor inputs to actions with deep neural networks, while modular learning approaches enrich the classical pipeline with learning-based semantic sensing and exploration. But learned visual navigation policies have predominantly been evaluated in simulation. How well do different classes of methods work on a robot? We present a large-scale empirical study of semantic visual navigation methods comparing representative methods from classical, modular, and end-to-end learning approaches across six homes with no prior experience, maps, or instrumentation. We find that modular learning works well in the real world, attaining a 90% success rate. In contrast, end-to-end learning does not, dropping from 77% simulation to 23% real-world success rate due to a large image domain gap between simulation and reality. For practitioners, we show that modular learning is a reliable approach to navigate to objects: modularity and abstraction in policy design enable Sim-to-Real transfer. For researchers, we identify two key issues that prevent today's simulators from being reliable evaluation benchmarks - (A) a large Sim-to-Real gap in images and (B) a disconnect between simulation and real-world error modes - and propose concrete steps forward.
Instance-Specific Image Goal Navigation: Training Embodied Agents to Find Object Instances
Nov 29, 2022



We consider the problem of embodied visual navigation given an image-goal (ImageNav) where an agent is initialized in an unfamiliar environment and tasked with navigating to a location 'described' by an image. Unlike related navigation tasks, ImageNav does not have a standardized task definition which makes comparison across methods difficult. Further, existing formulations have two problematic properties; (1) image-goals are sampled from random locations which can lead to ambiguity (e.g., looking at walls), and (2) image-goals match the camera specification and embodiment of the agent; this rigidity is limiting when considering user-driven downstream applications. We present the Instance-specific ImageNav task (InstanceImageNav) to address these limitations. Specifically, the goal image is 'focused' on some particular object instance in the scene and is taken with camera parameters independent of the agent. We instantiate InstanceImageNav in the Habitat Simulator using scenes from the Habitat-Matterport3D dataset (HM3D) and release a standardized benchmark to measure community progress.
Learning to Imitate Object Interactions from Internet Videos
Nov 23, 2022



We study the problem of imitating object interactions from Internet videos. This requires understanding the hand-object interactions in 4D, spatially in 3D and over time, which is challenging due to mutual hand-object occlusions. In this paper we make two main contributions: (1) a novel reconstruction technique RHOV (Reconstructing Hands and Objects from Videos), which reconstructs 4D trajectories of both the hand and the object using 2D image cues and temporal smoothness constraints; (2) a system for imitating object interactions in a physics simulator with reinforcement learning. We apply our reconstruction technique to 100 challenging Internet videos. We further show that we can successfully imitate a range of different object interactions in a physics simulator. Our object-centric approach is not limited to human-like end-effectors and can learn to imitate object interactions using different embodiments, like a robotic arm with a parallel jaw gripper.
Legged Locomotion in Challenging Terrains using Egocentric Vision
Nov 14, 2022



Animals are capable of precise and agile locomotion using vision. Replicating this ability has been a long-standing goal in robotics. The traditional approach has been to decompose this problem into elevation mapping and foothold planning phases. The elevation mapping, however, is susceptible to failure and large noise artifacts, requires specialized hardware, and is biologically implausible. In this paper, we present the first end-to-end locomotion system capable of traversing stairs, curbs, stepping stones, and gaps. We show this result on a medium-sized quadruped robot using a single front-facing depth camera. The small size of the robot necessitates discovering specialized gait patterns not seen elsewhere. The egocentric camera requires the policy to remember past information to estimate the terrain under its hind feet. We train our policy in simulation. Training has two phases - first, we train a policy using reinforcement learning with a cheap-to-compute variant of depth image and then in phase 2 distill it into the final policy that uses depth using supervised learning. The resulting policy transfers to the real world and is able to run in real-time on the limited compute of the robot. It can traverse a large variety of terrain while being robust to perturbations like pushes, slippery surfaces, and rocky terrain. Videos are at https://vision-locomotion.github.io
Learning Visual Locomotion with Cross-Modal Supervision
Nov 07, 2022



In this work, we show how to learn a visual walking policy that only uses a monocular RGB camera and proprioception. Since simulating RGB is hard, we necessarily have to learn vision in the real world. We start with a blind walking policy trained in simulation. This policy can traverse some terrains in the real world but often struggles since it lacks knowledge of the upcoming geometry. This can be resolved with the use of vision. We train a visual module in the real world to predict the upcoming terrain with our proposed algorithm Cross-Modal Supervision (CMS). CMS uses time-shifted proprioception to supervise vision and allows the policy to continually improve with more real-world experience. We evaluate our vision-based walking policy over a diverse set of terrains including stairs (up to 19cm high), slippery slopes (inclination of 35 degrees), curbs and tall steps (up to 20cm), and complex discrete terrains. We achieve this performance with less than 30 minutes of real-world data. Finally, we show that our policy can adapt to shifts in the visual field with a limited amount of real-world experience. Video results and code at https://antonilo.github.io/vision_locomotion/.
In-Hand Object Rotation via Rapid Motor Adaptation
Oct 10, 2022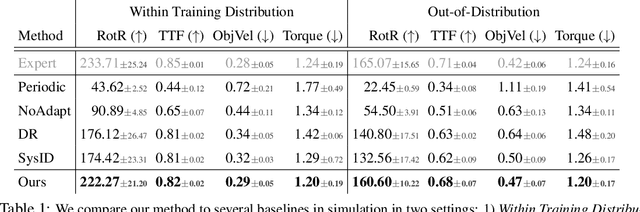
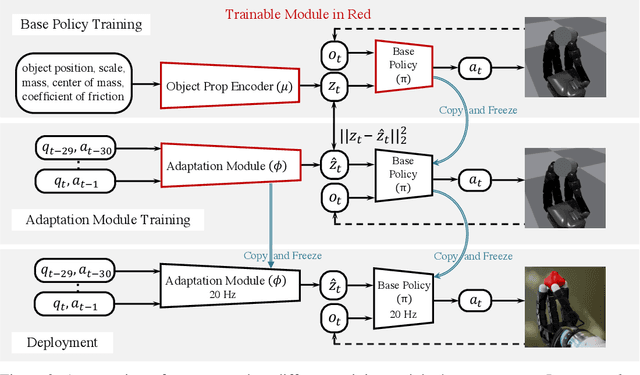


Generalized in-hand manipulation has long been an unsolved challenge of robotics. As a small step towards this grand goal, we demonstrate how to design and learn a simple adaptive controller to achieve in-hand object rotation using only fingertips. The controller is trained entirely in simulation on only cylindrical objects, which then - without any fine-tuning - can be directly deployed to a real robot hand to rotate dozens of objects with diverse sizes, shapes, and weights over the z-axis. This is achieved via rapid online adaptation of the controller to the object properties using only proprioception history. Furthermore, natural and stable finger gaits automatically emerge from training the control policy via reinforcement learning. Code and more videos are available at https://haozhi.io/hora
Real-World Robot Learning with Masked Visual Pre-training
Oct 06, 2022

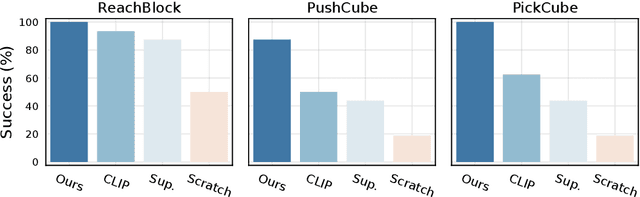
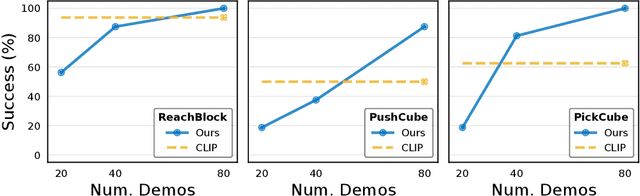
In this work, we explore self-supervised visual pre-training on images from diverse, in-the-wild videos for real-world robotic tasks. Like prior work, our visual representations are pre-trained via a masked autoencoder (MAE), frozen, and then passed into a learnable control module. Unlike prior work, we show that the pre-trained representations are effective across a range of real-world robotic tasks and embodiments. We find that our encoder consistently outperforms CLIP (up to 75%), supervised ImageNet pre-training (up to 81%), and training from scratch (up to 81%). Finally, we train a 307M parameter vision transformer on a massive collection of 4.5M images from the Internet and egocentric videos, and demonstrate clearly the benefits of scaling visual pre-training for robot learning.