 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNavIsaacLab: Generating Realistic Crowd via Parallel Robot Learning for Benchmarking Human-aware Navigation
Jun 24, 2026Robot autonomous navigation that accounts for surrounding human activities is crucial for ensuring both safety and natural human-robot interaction in real-world environments shared by humans and robots. Simulation of complex and diverse navigation scenarios serves as the foundation for training reliable robot navigation policies and accurately evaluating the performance of algorithms, offering an efficient alternative to manual supervision of real data. However, current human-aware navigation research faces significant challenges due to the scarcity of diverse, high-quality scene data. Existing simulation platforms often rely on handcrafted rules to approximate pedestrian behavior and lack the capability to provide extensive sensor signals, typically assuming perfect observations. To address these limitations, this paper presents NavIsaacLab, a comprehensive framework for benchmarking and training human-aware navigation policies through physics-based and photo-realistic simulations of pedestrians and scenes. Based on Isaac Lab, the proposed framework employs photo-realistic scene rendering capabilities and supports parallel simulation on GPU, delivering real-time and accurate 3D visual feedback to robots. To enhance the realism of human behavior, a data-driven approach is employed that incorporates a trajectory diffusion model and an adversarial motion learning controller, enabling controllable, physics-based pedestrian simulation. Furthermore, the integration of diverse cross-scale scenes provides a robust benchmark for state-of-the-art human-aware navigation methods.
Can Single-View Mesh Reconstruction Generalize to Robot Camera Rotation?
Jun 22, 2026Single-view mesh reconstruction predicts object meshes and spatial layouts from a single observation, making it attractive for fast robot spatial reasoning and real-to-sim digital twins. However, robot-mounted cameras naturally rotate during manipulation and navigation, while learned single-view reconstruction models often rely on view-dependent priors and may generalize poorly to out-of-distribution camera rotations. Such rotations can introduce 3D inconsistencies, incorrect layouts, and violations of physical constraints, but this failure mode remains under-evaluated. We introduce an evaluation protocol with controlled axis-wise roll, pitch, and yaw sweeps to trace errors in monocular depth estimation (MDE), canonical object meshes, camera-space layout, and physical plausibility within a representative SAM3D-style pipeline. On the Aria Digital Twin dataset and a real Franka wrist-camera sequence, camera rotations induce MDE distortion, layout drift, and collision penetration, while canonical mesh predictions remain relatively stable. A two-stage SAM3D+FoundationPose pipeline is more robust than one-stage feed-forward layout prediction, and our Gravity-Aware Refinement reduces one-stage pairwise ICP-based layout-orientation error by 47.1$\%$. Our evaluation reveals that current single-view mesh reconstruction methods generalize poorly to robot camera rotation, and suggests that explicit gravity cues are important for reliable robotic single-view mesh reconstruction.
FLM-Occ: Feed-forward Likelihood Maximization for Efficient Indoor Occupancy Prediction
Jun 19, 2026Recent indoor occupancy prediction methods adopt Gaussian primitives as a sparse 3D representation for computational efficiency. However, their training relies on voxel classification, which imposes only local constraints and lacks global supervision on the distribution of the primitives. Therefore, they inevitably predict spurious primitives in empty regions, undermining both representational and computational efficiency. To address this, we propose Feed-forward Likelihood Maximization (FLM), a novel framework that reformulates occupancy prediction as voxel distribution estimation. In FLM, a network is trained to predict a mixture model that maximizes the likelihood over ground-truth occupied voxels in a feed-forward manner. To enable end-to-end training of networks and voxelization of a standard mixture model, we define mixture weights as normalized primitive volumes to implicitly enforce simplex constraints and derive novel voxelization formulas. Based on FLM, our FLM-Occ, a novel method that is capable of relocating randomly initialized primitives over long distances to model a scene. On Occ-ScanNet, FLM-Occ achieves superior accuracy using only 32 superquadrics, 2.7% of the prior SoTA, while running 3.7 times faster.
Enhancing Glass Surface Reconstruction via Depth Prior for Robot Navigation
Apr 20, 2026Indoor robot navigation is often compromised by glass surfaces, which severely corrupt depth sensor measurements. While foundation models like Depth Anything 3 provide excellent geometric priors, they lack an absolute metric scale. We propose a training-free framework that leverages depth foundation models as a structural prior, employing a robust local RANSAC-based alignment to fuse it with raw sensor depth. This naturally avoids contamination from erroneous glass measurements and recovers an accurate metric scale. Furthermore, we introduce \ti{GlassRecon}, a novel RGB-D dataset with geometrically derived ground truth for glass regions. Extensive experiments demonstrate that our approach consistently outperforms state-of-the-art baselines, especially under severe sensor depth corruption. The dataset and related code will be released at https://github.com/jarvisyjw/GlassRecon.
Hierarchical Visual Relocalization with Nearest View Synthesis from Feature Gaussian Splatting
Mar 31, 2026Visual relocalization is a fundamental task in the field of 3D computer vision, estimating a camera's pose when it revisits a previously known scene. While point-based hierarchical relocalization methods have shown strong scalability and efficiency, they are often limited by sparse image observations and weak feature matching. In this work, we propose SplatHLoc, a novel hierarchical visual relocalization framework that uses Feature Gaussian Splatting as the scene representation. To address the sparsity of database images, we propose an adaptive viewpoint retrieval method that synthesizes virtual candidates with viewpoints more closely aligned with the query, thereby improving the accuracy of initial pose estimation. For feature matching, we observe that Gaussian-rendered features and those extracted directly from images exhibit different strengths across the two-stage matching process: the former performs better in the coarse stage, while the latter proves more effective in the fine stage. Therefore, we introduce a hybrid feature matching strategy, enabling more accurate and efficient pose estimation. Extensive experiments on both indoor and outdoor datasets show that SplatHLoc enhances the robustness of visual relocalization, setting a new state-of-the-art.
TPT-Bench: A Large-Scale, Long-Term and Robot-Egocentric Dataset for Benchmarking Target Person Tracking
May 12, 2025Tracking a target person from robot-egocentric views is crucial for developing autonomous robots that provide continuous personalized assistance or collaboration in Human-Robot Interaction (HRI) and Embodied AI. However, most existing target person tracking (TPT) benchmarks are limited to controlled laboratory environments with few distractions, clean backgrounds, and short-term occlusions. In this paper, we introduce a large-scale dataset designed for TPT in crowded and unstructured environments, demonstrated through a robot-person following task. The dataset is collected by a human pushing a sensor-equipped cart while following a target person, capturing human-like following behavior and emphasizing long-term tracking challenges, including frequent occlusions and the need for re-identification from numerous pedestrians. It includes multi-modal data streams, including odometry, 3D LiDAR, IMU, panoptic, and RGB-D images, along with exhaustively annotated 2D bounding boxes of the target person across 35 sequences, both indoors and outdoors. Using this dataset and visual annotations, we perform extensive experiments with existing TPT methods, offering a thorough analysis of their limitations and suggesting future research directions.
Optimizing NeRF-based SLAM with Trajectory Smoothness Constraints
Oct 11, 2024



The joint optimization of Neural Radiance Fields (NeRF) and camera trajectories has been widely applied in SLAM tasks due to its superior dense mapping quality and consistency. NeRF-based SLAM learns camera poses using constraints by implicit map representation. A widely observed phenomenon that results from the constraints of this form is jerky and physically unrealistic estimated camera motion, which in turn affects the map quality. To address this deficiency of current NeRF-based SLAM, we propose in this paper TS-SLAM (TS for Trajectory Smoothness). It introduces smoothness constraints on camera trajectories by representing them with uniform cubic B-splines with continuous acceleration that guarantees smooth camera motion. Benefiting from the differentiability and local control properties of B-splines, TS-SLAM can incrementally learn the control points end-to-end using a sliding window paradigm. Additionally, we regularize camera trajectories by exploiting the dynamics prior to further smooth trajectories. Experimental results demonstrate that TS-SLAM achieves superior trajectory accuracy and improves mapping quality versus NeRF-based SLAM that does not employ the above smoothness constraints.
PISR: Polarimetric Neural Implicit Surface Reconstruction for Textureless and Specular Objects
Sep 22, 2024



Neural implicit surface reconstruction has achieved remarkable progress recently. Despite resorting to complex radiance modeling, state-of-the-art methods still struggle with textureless and specular surfaces. Different from RGB images, polarization images can provide direct constraints on the azimuth angles of the surface normals. In this paper, we present PISR, a novel method that utilizes a geometrically accurate polarimetric loss to refine shape independently of appearance. In addition, PISR smooths surface normals in image space to eliminate severe shape distortions and leverages the hash-grid-based neural signed distance function to accelerate the reconstruction. Experimental results demonstrate that PISR achieves higher accuracy and robustness, with an L1 Chamfer distance of 0.5 mm and an F-score of 99.5% at 1 mm, while converging 4~30 times faster than previous polarimetric surface reconstruction methods.
Perspective Phase Angle Model for Polarimetric 3D Reconstruction
Jul 21, 2022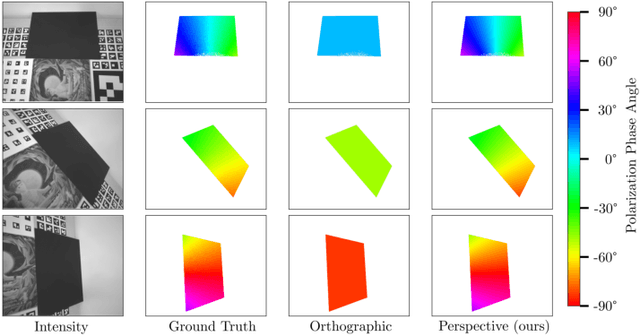

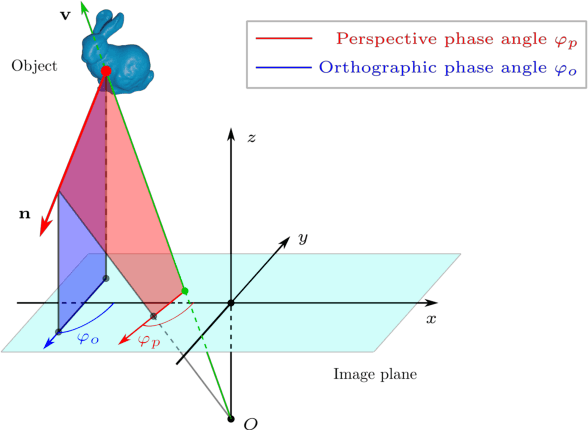
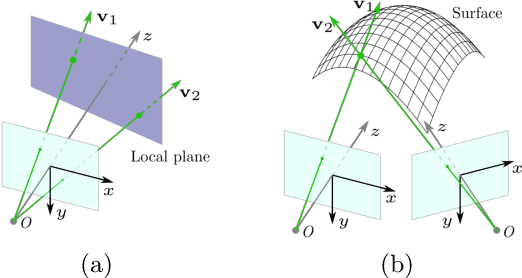
Current polarimetric 3D reconstruction methods, including those in the well-established shape from polarization literature, are all developed under the orthographic projection assumption. In the case of a large field of view, however, this assumption does not hold and may result in significant reconstruction errors in methods that make this assumption. To address this problem, we present the perspective phase angle (PPA) model that is applicable to perspective cameras. Compared with the orthographic model, the proposed PPA model accurately describes the relationship between polarization phase angle and surface normal under perspective projection. In addition, the PPA model makes it possible to estimate surface normals from only one single-view phase angle map and does not suffer from the so-called $\pi$-ambiguity problem. Experiments on real data show that the PPA model is more accurate for surface normal estimation with a perspective camera than the orthographic model.
Mapping While Following: 2D LiDAR SLAM in Indoor Dynamic Environments with a Person Tracker
Apr 18, 2022
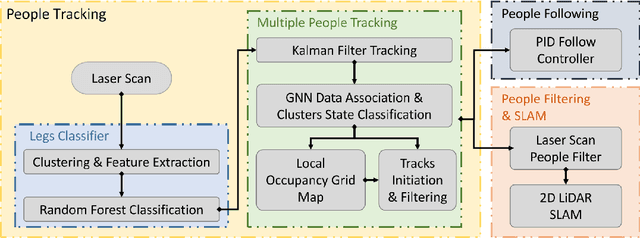

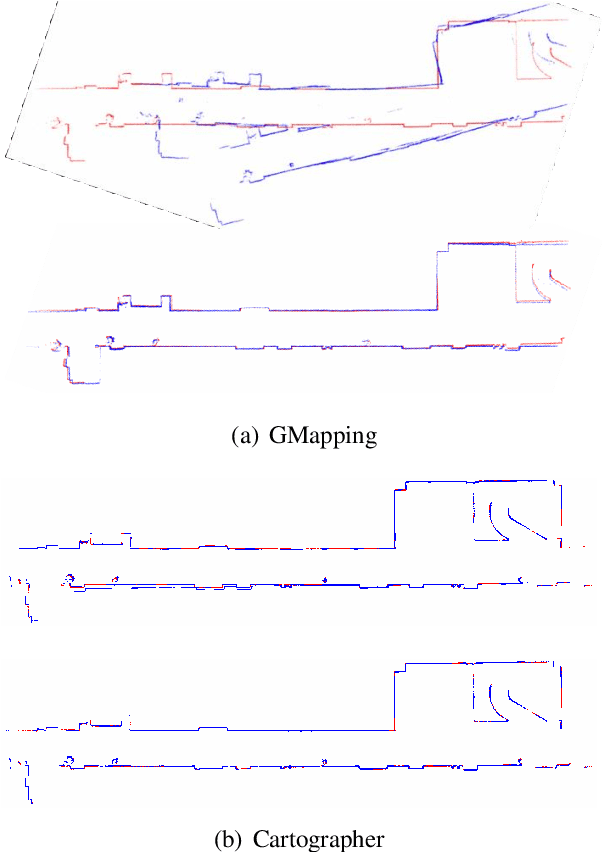
2D LiDAR SLAM (Simultaneous Localization and Mapping) is widely used in indoor environments due to its stability and flexibility. However, its mapping procedure is usually operated by a joystick in static environments, while indoor environments often are dynamic with moving objects such as people. The generated map with noisy points due to the dynamic objects is usually incomplete and distorted. To address this problem, we propose a framework of 2D-LiDAR-based SLAM without manual control that effectively excludes dynamic objects (people) and simplify the process for a robot to map an environment. The framework, which includes three parts: people tracking, filtering and following. We verify our proposed framework in experiments with two classic 2D-LiDAR-based SLAM algorithms in indoor environments. The results show that this framework is effective in handling dynamic objects and reducing the mapping error.
* Presented at 2021 IEEE International Conference on Robotics and Biomimetics (ROBIO)