 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTARIC: Memory-Augmented Traversability-Aware Outdoor VLN under Interrupted Semantic Cues
May 29, 2026Outdoor vision-language navigation (VLN) in long-range, open-world environments is frequently disrupted by semantic-cue interruptions, where informative goal cues become sparse, occluded, or leave the field of view. Once such cues disappear, agents enter a cue-free phase and often degrade into backtracking, oscillatory headings, or aimless exploration. While memory-based methods attempt to bridge these gaps, they often fail under traversability-driven detours: the remembered cue direction may be infeasible, forcing detours that prolong cue-free phases and gradually render robot-centric cues stale and implicit histories blurred. This makes traversability a stability condition for maintaining goal-directed guidance, rather than merely a local safety concern. We propose a unified outdoor VLN framework that survives semantic-cue interruptions by maintaining traversability-consistent executable guidance throughout prolonged cue-free phases. Specifically, our method extracts semantic bearings from visibility-gated goal or exploration cues and grounds them into executable headings using a real-time near-field traversability profile, providing goal-consistent feasible guidance beyond reject-only safety filtering. To prevent guidance degradation during detours, we lift intermittent 2D evidence into a world-aligned 3D cue memory with an uncertainty-aware readout mechanism, ensuring guidance remains continuously reachable and stable as the robot moves. We evaluate the framework on quadrupedal and wheeled platforms over 600--1000 m routes. Our method improves simulation success rate by over 10 percentage points over the strongest baseline and achieves a real-world success rate of 40%, compared to 17.5% for the strongest baseline, with substantially higher robustness during prolonged cue-free intervals.
CosFly: Plan in the Matrix, Fly in the World
May 18, 2026We present CosFly, a box-structured planning and multimodal simulation pipeline for aerial tracking, together with CosFly-Track, a large-scale UAV dataset for dynamic target tracking across diverse environments including urban centers, highways, rural landscapes, forests, and coastal towns. In our current implementation on CARLA, CosFly provides a modular 7-step construction pipeline that converts complex 3D worlds into structured obstacle representations for planning, then projects the resulting trajectories back into multi-modal sensor data -- including RGB images, high-precision depth maps, and semantic segmentation masks -- paired with natural language navigation instructions. A key feature is the support for configurable fixed-FOV zoom levels (one FOV setting drawn per trajectory and held constant throughout), enabling simulation of various focal lengths through camera-intrinsic adjustments. The pipeline covers the complete workflow from 3D map export through grid simplification, pedestrian and drone trajectory planning, multi-modal rendering with 6-DOF pose annotations, quality inspection, and teacher-student caption generation. We analyze two trajectory-planning paradigms for aerial target tracking: a conventional two-stage pipeline with front-end candidate generation and backend refinement, and a direct gradient-based formulation that optimizes multiple tracking constraints in a single objective. The public CosFly-Track release contains 250 validated trajectories and approximately 100,000 rendered images with complete 6-DOF drone pose annotations (position x, y, z and orientation yaw, pitch, roll). Together, the pipeline and dataset establish a scalable foundation for aerial-ground collaborative research, supporting dynamic target tracking, UAV navigation, and multi-modal perception across diverse environments.
Vision-and-Language Navigation for UAVs: Progress, Challenges, and a Research Roadmap
Apr 15, 2026Vision-and-Language Navigation for Unmanned Aerial Vehicles (UAV-VLN) represents a pivotal challenge in embodied artificial intelligence, focused on enabling UAVs to interpret high-level human commands and execute long-horizon tasks in complex 3D environments. This paper provides a comprehensive and structured survey of the field, from its formal task definition to the current state of the art. We establish a methodological taxonomy that charts the technological evolution from early modular and deep learning approaches to contemporary agentic systems driven by large foundation models, including Vision-Language Models (VLMs), Vision-Language-Action (VLA) models, and the emerging integration of generative world models with VLA architectures for physically-grounded reasoning. The survey systematically reviews the ecosystem of essential resources simulators, datasets, and evaluation metrics that facilitates standardized research. Furthermore, we conduct a critical analysis of the primary challenges impeding real-world deployment: the simulation-to-reality gap, robust perception in dynamic outdoor settings, reasoning with linguistic ambiguity, and the efficient deployment of large models on resource-constrained hardware. By synthesizing current benchmarks and limitations, this survey concludes by proposing a forward-looking research roadmap to guide future inquiry into key frontiers such as multi-agent swarm coordination and air-ground collaborative robotics.
CARLA-Air: Fly Drones Inside a CARLA World -- A Unified Infrastructure for Air-Ground Embodied Intelligence
Mar 30, 2026The convergence of low-altitude economies, embodied intelligence, and air-ground cooperative systems creates growing demand for simulation infrastructure capable of jointly modeling aerial and ground agents within a single physically coherent environment. Existing open-source platforms remain domain-segregated: driving simulators lack aerial dynamics, while multirotor simulators lack realistic ground scenes. Bridge-based co-simulation introduces synchronization overhead and cannot guarantee strict spatial-temporal consistency. We present CARLA-Air, an open-source infrastructure that unifies high-fidelity urban driving and physics-accurate multirotor flight within a single Unreal Engine process. The platform preserves both CARLA and AirSim native Python APIs and ROS 2 interfaces, enabling zero-modification code reuse. Within a shared physics tick and rendering pipeline, CARLA-Air delivers photorealistic environments with rule-compliant traffic, socially-aware pedestrians, and aerodynamically consistent UAV dynamics, synchronously capturing up to 18 sensor modalities across all platforms at each tick. The platform supports representative air-ground embodied intelligence workloads spanning cooperation, embodied navigation and vision-language action, multi-modal perception and dataset construction, and reinforcement-learning-based policy training. An extensible asset pipeline allows integration of custom robot platforms into the shared world. By inheriting AirSim's aerial capabilities -- whose upstream development has been archived -- CARLA-Air ensures this widely adopted flight stack continues to evolve within a modern infrastructure. Released with prebuilt binaries and full source: https://github.com/louiszengCN/CarlaAir
Ternary Singular Value Decomposition as a Better Parameterized Form in Linear Mapping
Aug 15, 2023
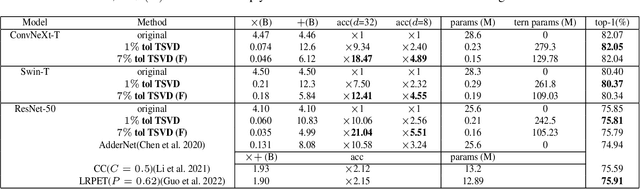


We present a simple yet novel parameterized form of linear mapping to achieves remarkable network compression performance: a pseudo SVD called Ternary SVD (TSVD). Unlike vanilla SVD, TSVD limits the $U$ and $V$ matrices in SVD to ternary matrices form in $\{\pm 1, 0\}$. This means that instead of using the expensive multiplication instructions, TSVD only requires addition instructions when computing $U(\cdot)$ and $V(\cdot)$. We provide direct and training transition algorithms for TSVD like Post Training Quantization and Quantization Aware Training respectively. Additionally, we analyze the convergence of the direct transition algorithms in theory. In experiments, we demonstrate that TSVD can achieve state-of-the-art network compression performance in various types of networks and tasks, including current baseline models such as ConvNext, Swim, BERT, and large language model like OPT.