 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTAR-Net: An Interpretable Model-Aided Network for Remote Sensing Image Denoising
May 30, 2025Remote sensing image (RSI) denoising is an important topic in the field of remote sensing. Despite the impressive denoising performance of RSI denoising methods, most current deep learning-based approaches function as black boxes and lack integration with physical information models, leading to limited interpretability. Additionally, many methods may struggle with insufficient attention to non-local self-similarity in RSI and require tedious tuning of regularization parameters to achieve optimal performance, particularly in conventional iterative optimization approaches. In this paper, we first propose a novel RSI denoising method named sparse tensor-aided representation network (STAR-Net), which leverages a low-rank prior to effectively capture the non-local self-similarity within RSI. Furthermore, we extend STAR-Net to a sparse variant called STAR-Net-S to deal with the interference caused by non-Gaussian noise in original RSI for the purpose of improving robustness. Different from conventional iterative optimization, we develop an alternating direction method of multipliers (ADMM)-guided deep unrolling network, in which all regularization parameters can be automatically learned, thus inheriting the advantages of both model-based and deep learning-based approaches and successfully addressing the above-mentioned shortcomings. Comprehensive experiments on synthetic and real-world datasets demonstrate that STAR-Net and STAR-Net-S outperform state-of-the-art RSI denoising methods.
Bi-Level Unsupervised Feature Selection
May 26, 2025Unsupervised feature selection (UFS) is an important task in data engineering. However, most UFS methods construct models from a single perspective and often fail to simultaneously evaluate feature importance and preserve their inherent data structure, thus limiting their performance. To address this challenge, we propose a novel bi-level unsupervised feature selection (BLUFS) method, including a clustering level and a feature level. Specifically, at the clustering level, spectral clustering is used to generate pseudo-labels for representing the data structure, while a continuous linear regression model is developed to learn the projection matrix. At the feature level, the $\ell_{2,0}$-norm constraint is imposed on the projection matrix for more effectively selecting features. To the best of our knowledge, this is the first work to combine a bi-level framework with the $\ell_{2,0}$-norm. To solve the proposed bi-level model, we design an efficient proximal alternating minimization (PAM) algorithm, whose subproblems either have explicit solutions or can be computed by fast solvers. Furthermore, we establish the convergence result and computational complexity. Finally, extensive experiments on two synthetic datasets and eight real datasets demonstrate the superiority of BLUFS in clustering and classification tasks.
Robust Orthogonal NMF with Label Propagation for Image Clustering
Apr 30, 2025



Non-negative matrix factorization (NMF) is a popular unsupervised learning approach widely used in image clustering. However, in real-world clustering scenarios, most existing NMF methods are highly sensitive to noise corruption and are unable to effectively leverage limited supervised information. To overcome these drawbacks, we propose a unified non-convex framework with label propagation called robust orthogonal nonnegative matrix factorization (RONMF). This method not only considers the graph Laplacian and label propagation as regularization terms but also introduces a more effective non-convex structure to measure the reconstruction error and imposes orthogonal constraints on the basis matrix to reduce the noise corruption, thereby achieving higher robustness. To solve RONMF, we develop an alternating direction method of multipliers (ADMM)-based optimization algorithm. In particular, all subproblems have closed-form solutions, which ensures its efficiency. Experimental evaluations on eight public image datasets demonstrate that the proposed RONMF outperforms state-of-the-art NMF methods across various standard metrics and shows excellent robustness. The code will be available at https://github.com/slinda-liu.
Unsupervised Cross-Domain 3D Human Pose Estimation via Pseudo-Label-Guided Global Transforms
Apr 17, 2025Existing 3D human pose estimation methods often suffer in performance, when applied to cross-scenario inference, due to domain shifts in characteristics such as camera viewpoint, position, posture, and body size. Among these factors, camera viewpoints and locations {have been shown} to contribute significantly to the domain gap by influencing the global positions of human poses. To address this, we propose a novel framework that explicitly conducts global transformations between pose positions in the camera coordinate systems of source and target domains. We start with a Pseudo-Label Generation Module that is applied to the 2D poses of the target dataset to generate pseudo-3D poses. Then, a Global Transformation Module leverages a human-centered coordinate system as a novel bridging mechanism to seamlessly align the positional orientations of poses across disparate domains, ensuring consistent spatial referencing. To further enhance generalization, a Pose Augmentor is incorporated to address variations in human posture and body size. This process is iterative, allowing refined pseudo-labels to progressively improve guidance for domain adaptation. Our method is evaluated on various cross-dataset benchmarks, including Human3.6M, MPI-INF-3DHP, and 3DPW. The proposed method outperforms state-of-the-art approaches and even outperforms the target-trained model.
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Mar 18, 2025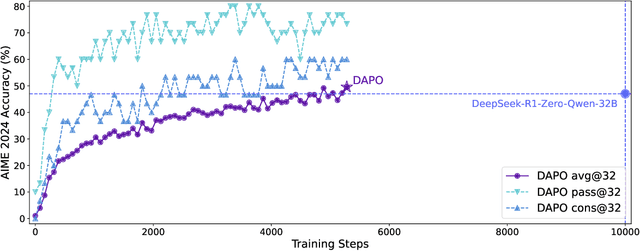

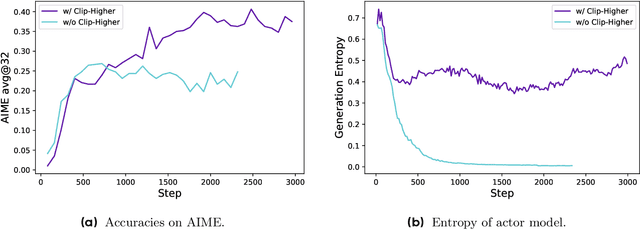

Inference scaling empowers LLMs with unprecedented reasoning ability, with reinforcement learning as the core technique to elicit complex reasoning. However, key technical details of state-of-the-art reasoning LLMs are concealed (such as in OpenAI o1 blog and DeepSeek R1 technical report), thus the community still struggles to reproduce their RL training results. We propose the $\textbf{D}$ecoupled Clip and $\textbf{D}$ynamic s$\textbf{A}$mpling $\textbf{P}$olicy $\textbf{O}$ptimization ($\textbf{DAPO}$) algorithm, and fully open-source a state-of-the-art large-scale RL system that achieves 50 points on AIME 2024 using Qwen2.5-32B base model. Unlike previous works that withhold training details, we introduce four key techniques of our algorithm that make large-scale LLM RL a success. In addition, we open-source our training code, which is built on the verl framework, along with a carefully curated and processed dataset. These components of our open-source system enhance reproducibility and support future research in large-scale LLM RL.
CoopDETR: A Unified Cooperative Perception Framework for 3D Detection via Object Query
Feb 26, 2025



Cooperative perception enhances the individual perception capabilities of autonomous vehicles (AVs) by providing a comprehensive view of the environment. However, balancing perception performance and transmission costs remains a significant challenge. Current approaches that transmit region-level features across agents are limited in interpretability and demand substantial bandwidth, making them unsuitable for practical applications. In this work, we propose CoopDETR, a novel cooperative perception framework that introduces object-level feature cooperation via object query. Our framework consists of two key modules: single-agent query generation, which efficiently encodes raw sensor data into object queries, reducing transmission cost while preserving essential information for detection; and cross-agent query fusion, which includes Spatial Query Matching (SQM) and Object Query Aggregation (OQA) to enable effective interaction between queries. Our experiments on the OPV2V and V2XSet datasets demonstrate that CoopDETR achieves state-of-the-art performance and significantly reduces transmission costs to 1/782 of previous methods.
Evaluating Entity Retrieval in Electronic Health Records: a Semantic Gap Perspective
Feb 10, 2025



Entity retrieval plays a crucial role in the utilization of Electronic Health Records (EHRs) and is applied across a wide range of clinical practices. However, a comprehensive evaluation of this task is lacking due to the absence of a public benchmark. In this paper, we propose the development and release of a novel benchmark for evaluating entity retrieval in EHRs, with a particular focus on the semantic gap issue. Using discharge summaries from the MIMIC-III dataset, we incorporate ICD codes and prescription labels associated with the notes as queries, and annotate relevance judgments using GPT-4. In total, we use 1,000 patient notes, generate 1,246 queries, and provide over 77,000 relevance annotations. To offer the first assessment of the semantic gap, we introduce a novel classification system for relevance matches. Leveraging GPT-4, we categorize each relevant pair into one of five categories: string, synonym, abbreviation, hyponym, and implication. Using the proposed benchmark, we evaluate several retrieval methods, including BM25, query expansion, and state-of-the-art dense retrievers. Our findings show that BM25 provides a strong baseline but struggles with semantic matches. Query expansion significantly improves performance, though it slightly reduces string match capabilities. Dense retrievers outperform traditional methods, particularly for semantic matches, and general-domain dense retrievers often surpass those trained specifically in the biomedical domain.
A Periodic Bayesian Flow for Material Generation
Feb 04, 2025



Generative modeling of crystal data distribution is an important yet challenging task due to the unique periodic physical symmetry of crystals. Diffusion-based methods have shown early promise in modeling crystal distribution. More recently, Bayesian Flow Networks were introduced to aggregate noisy latent variables, resulting in a variance-reduced parameter space that has been shown to be advantageous for modeling Euclidean data distributions with structural constraints (Song et al., 2023). Inspired by this, we seek to unlock its potential for modeling variables located in non-Euclidean manifolds e.g. those within crystal structures, by overcoming challenging theoretical issues. We introduce CrysBFN, a novel crystal generation method by proposing a periodic Bayesian flow, which essentially differs from the original Gaussian-based BFN by exhibiting non-monotonic entropy dynamics. To successfully realize the concept of periodic Bayesian flow, CrysBFN integrates a new entropy conditioning mechanism and empirically demonstrates its significance compared to time-conditioning. Extensive experiments over both crystal ab initio generation and crystal structure prediction tasks demonstrate the superiority of CrysBFN, which consistently achieves new state-of-the-art on all benchmarks. Surprisingly, we found that CrysBFN enjoys a significant improvement in sampling efficiency, e.g., ~100x speedup 10 v.s. 2000 steps network forwards) compared with previous diffusion-based methods on MP-20 dataset. Code is available at https://github.com/wu-han-lin/CrysBFN.
MATCNN: Infrared and Visible Image Fusion Method Based on Multi-scale CNN with Attention Transformer
Feb 04, 2025



While attention-based approaches have shown considerable progress in enhancing image fusion and addressing the challenges posed by long-range feature dependencies, their efficacy in capturing local features is compromised by the lack of diverse receptive field extraction techniques. To overcome the shortcomings of existing fusion methods in extracting multi-scale local features and preserving global features, this paper proposes a novel cross-modal image fusion approach based on a multi-scale convolutional neural network with attention Transformer (MATCNN). MATCNN utilizes the multi-scale fusion module (MSFM) to extract local features at different scales and employs the global feature extraction module (GFEM) to extract global features. Combining the two reduces the loss of detail features and improves the ability of global feature representation. Simultaneously, an information mask is used to label pertinent details within the images, aiming to enhance the proportion of preserving significant information in infrared images and background textures in visible images in fused images. Subsequently, a novel optimization algorithm is developed, leveraging the mask to guide feature extraction through the integration of content, structural similarity index measurement, and global feature loss. Quantitative and qualitative evaluations are conducted across various datasets, revealing that MATCNN effectively highlights infrared salient targets, preserves additional details in visible images, and achieves better fusion results for cross-modal images. The code of MATCNN will be available at https://github.com/zhang3849/MATCNN.git.
Rethinking Diffusion Posterior Sampling: From Conditional Score Estimator to Maximizing a Posterior
Jan 31, 2025Recent advancements in diffusion models have been leveraged to address inverse problems without additional training, and Diffusion Posterior Sampling (DPS) (Chung et al., 2022a) is among the most popular approaches. Previous analyses suggest that DPS accomplishes posterior sampling by approximating the conditional score. While in this paper, we demonstrate that the conditional score approximation employed by DPS is not as effective as previously assumed, but rather aligns more closely with the principle of maximizing a posterior (MAP). This assertion is substantiated through an examination of DPS on 512x512 ImageNet images, revealing that: 1) DPS's conditional score estimation significantly diverges from the score of a well-trained conditional diffusion model and is even inferior to the unconditional score; 2) The mean of DPS's conditional score estimation deviates significantly from zero, rendering it an invalid score estimation; 3) DPS generates high-quality samples with significantly lower diversity. In light of the above findings, we posit that DPS more closely resembles MAP than a conditional score estimator, and accordingly propose the following enhancements to DPS: 1) we explicitly maximize the posterior through multi-step gradient ascent and projection; 2) we utilize a light-weighted conditional score estimator trained with only 100 images and 8 GPU hours. Extensive experimental results indicate that these proposed improvements significantly enhance DPS's performance. The source code for these improvements is provided in https://github.com/tongdaxu/Rethinking-Diffusion-Posterior-Sampling-From-Conditional-Score-Estimator-to-Maximizing-a-Posterior.