 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaking Mathematical Reasoning Adaptive
Oct 06, 2025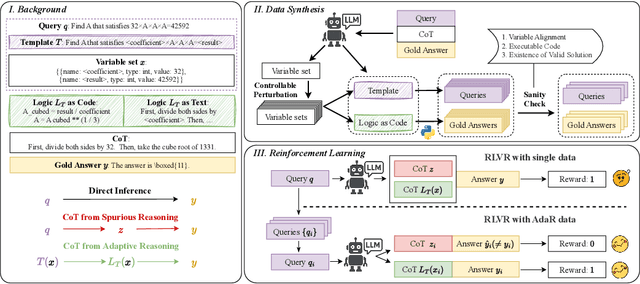
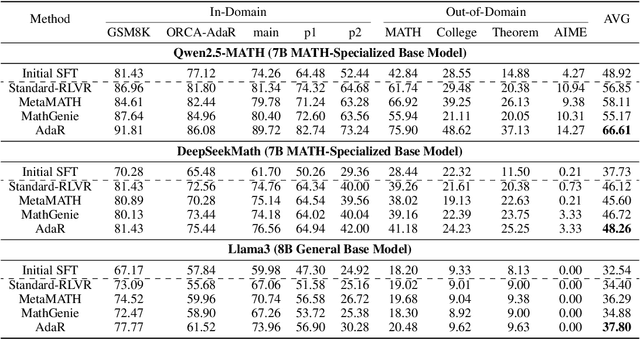


Mathematical reasoning is a primary indicator of large language models (LLMs) intelligence. However, existing LLMs exhibit failures of robustness and generalization. This paper attributes these deficiencies to spurious reasoning, i.e., producing answers from superficial features. To address this challenge, we propose the AdaR framework to enable adaptive reasoning, wherein models rely on problem-solving logic to produce answers. AdaR synthesizes logically equivalent queries by varying variable values, and trains models with RLVR on these data to penalize spurious logic while encouraging adaptive logic. To improve data quality, we extract the problem-solving logic from the original query and generate the corresponding answer by code execution, then apply a sanity check. Experimental results demonstrate that AdaR improves robustness and generalization, achieving substantial improvement in mathematical reasoning while maintaining high data efficiency. Analysis indicates that data synthesis and RLVR function in a coordinated manner to enable adaptive reasoning in LLMs. Subsequent analyses derive key design insights into the effect of critical factors and the applicability to instruct LLMs. Our project is available at https://github.com/LaiZhejian/AdaR
Fine-tuning Done Right in Model Editing
Sep 26, 2025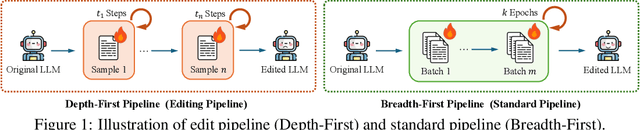

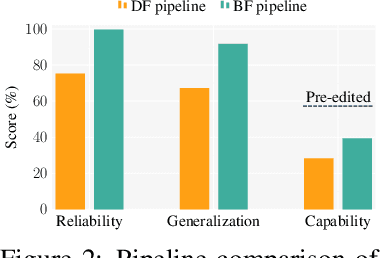

Fine-tuning, a foundational method for adapting large language models, has long been considered ineffective for model editing. Here, we challenge this belief, arguing that the reported failure arises not from the inherent limitation of fine-tuning itself, but from adapting it to the sequential nature of the editing task, a single-pass depth-first pipeline that optimizes each sample to convergence before moving on. While intuitive, this depth-first pipeline coupled with sample-wise updating over-optimizes each edit and induces interference across edits. Our controlled experiments reveal that simply restoring fine-tuning to the standard breadth-first (i.e., epoch-based) pipeline with mini-batch optimization substantially improves its effectiveness for model editing. Moreover, fine-tuning in editing also suffers from suboptimal tuning parameter locations inherited from prior methods. Through systematic analysis of tuning locations, we derive LocFT-BF, a simple and effective localized editing method built on the restored fine-tuning framework. Extensive experiments across diverse LLMs and datasets demonstrate that LocFT-BF outperforms state-of-the-art methods by large margins. Notably, to our knowledge, it is the first to sustain 100K edits and 72B-parameter models,10 x beyond prior practice, without sacrificing general capabilities. By clarifying a long-standing misconception and introducing a principled localized tuning strategy, we advance fine-tuning from an underestimated baseline to a leading method for model editing, establishing a solid foundation for future research.
IIET: Efficient Numerical Transformer via Implicit Iterative Euler Method
Sep 26, 2025



High-order numerical methods enhance Transformer performance in tasks like NLP and CV, but introduce a performance-efficiency trade-off due to increased computational overhead. Our analysis reveals that conventional efficiency techniques, such as distillation, can be detrimental to the performance of these models, exemplified by PCformer. To explore more optimizable ODE-based Transformer architectures, we propose the \textbf{I}terative \textbf{I}mplicit \textbf{E}uler \textbf{T}ransformer \textbf{(IIET)}, which simplifies high-order methods using an iterative implicit Euler approach. This simplification not only leads to superior performance but also facilitates model compression compared to PCformer. To enhance inference efficiency, we introduce \textbf{I}teration \textbf{I}nfluence-\textbf{A}ware \textbf{D}istillation \textbf{(IIAD)}. Through a flexible threshold, IIAD allows users to effectively balance the performance-efficiency trade-off. On lm-evaluation-harness, IIET boosts average accuracy by 2.65\% over vanilla Transformers and 0.8\% over PCformer. Its efficient variant, E-IIET, significantly cuts inference overhead by 55\% while retaining 99.4\% of the original task accuracy. Moreover, the most efficient IIET variant achieves an average performance gain exceeding 1.6\% over vanilla Transformer with comparable speed.
TCPO: Thought-Centric Preference Optimization for Effective Embodied Decision-making
Sep 10, 2025



Using effective generalization capabilities of vision language models (VLMs) in context-specific dynamic tasks for embodied artificial intelligence remains a significant challenge. Although supervised fine-tuned models can better align with the real physical world, they still exhibit sluggish responses and hallucination issues in dynamically changing environments, necessitating further alignment. Existing post-SFT methods, reliant on reinforcement learning and chain-of-thought (CoT) approaches, are constrained by sparse rewards and action-only optimization, resulting in low sample efficiency, poor consistency, and model degradation. To address these issues, this paper proposes Thought-Centric Preference Optimization (TCPO) for effective embodied decision-making. Specifically, TCPO introduces a stepwise preference-based optimization approach, transforming sparse reward signals into richer step sample pairs. It emphasizes the alignment of the model's intermediate reasoning process, mitigating the problem of model degradation. Moreover, by incorporating Action Policy Consistency Constraint (APC), it further imposes consistency constraints on the model output. Experiments in the ALFWorld environment demonstrate an average success rate of 26.67%, achieving a 6% improvement over RL4VLM and validating the effectiveness of our approach in mitigating model degradation after fine-tuning. These results highlight the potential of integrating preference-based learning techniques with CoT processes to enhance the decision-making capabilities of vision-language models in embodied agents.
OneCAT: Decoder-Only Auto-Regressive Model for Unified Understanding and Generation
Sep 03, 2025



We introduce OneCAT, a unified multimodal model that seamlessly integrates understanding, generation, and editing within a novel, pure decoder-only transformer architecture. Our framework uniquely eliminates the need for external components such as Vision Transformers (ViT) or vision tokenizer during inference, leading to significant efficiency gains, especially for high-resolution inputs. This is achieved through a modality-specific Mixture-of-Experts (MoE) structure trained with a single autoregressive (AR) objective, which also natively supports dynamic resolutions. Furthermore, we pioneer a multi-scale visual autoregressive mechanism within the Large Language Model (LLM) that drastically reduces decoding steps compared to diffusion-based methods while maintaining state-of-the-art performance. Our findings demonstrate the powerful potential of pure autoregressive modeling as a sufficient and elegant foundation for unified multimodal intelligence. As a result, OneCAT sets a new performance standard, outperforming existing open-source unified multimodal models across benchmarks for multimodal generation, editing, and understanding.
Stop Spinning Wheels: Mitigating LLM Overthinking via Mining Patterns for Early Reasoning Exit
Aug 25, 2025



Large language models (LLMs) enhance complex reasoning tasks by scaling the individual thinking process. However, prior work shows that overthinking can degrade overall performance. Motivated by observed patterns in thinking length and content length, we categorize reasoning into three stages: insufficient exploration stage, compensatory reasoning stage, and reasoning convergence stage. Typically, LLMs produce correct answers in the compensatory reasoning stage, whereas reasoning convergence often triggers overthinking, causing increased resource usage or even infinite loops. Therefore, mitigating overthinking hinges on detecting the end of the compensatory reasoning stage, defined as the Reasoning Completion Point (RCP). RCP typically appears at the end of the first complete reasoning cycle and can be identified by querying the LLM sentence by sentence or monitoring the probability of an end-of-thinking token (e.g., \texttt{</think>}), though these methods lack an efficient and precise balance. To improve this, we mine more sensitive and consistent RCP patterns and develop a lightweight thresholding strategy based on heuristic rules. Experimental evaluations on benchmarks (AIME24, AIME25, GPQA-D) demonstrate that the proposed method reduces token consumption while preserving or enhancing reasoning accuracy.
Too Consistent to Detect: A Study of Self-Consistent Errors in LLMs
May 23, 2025As large language models (LLMs) often generate plausible but incorrect content, error detection has become increasingly critical to ensure truthfulness. However, existing detection methods often overlook a critical problem we term as self-consistent error, where LLMs repeatly generate the same incorrect response across multiple stochastic samples. This work formally defines self-consistent errors and evaluates mainstream detection methods on them. Our investigation reveals two key findings: (1) Unlike inconsistent errors, whose frequency diminishes significantly as LLM scale increases, the frequency of self-consistent errors remains stable or even increases. (2) All four types of detection methshods significantly struggle to detect self-consistent errors. These findings reveal critical limitations in current detection methods and underscore the need for improved methods. Motivated by the observation that self-consistent errors often differ across LLMs, we propose a simple but effective cross-model probe method that fuses hidden state evidence from an external verifier LLM. Our method significantly enhances performance on self-consistent errors across three LLM families.
Rethinking the Sampling Criteria in Reinforcement Learning for LLM Reasoning: A Competence-Difficulty Alignment Perspective
May 23, 2025


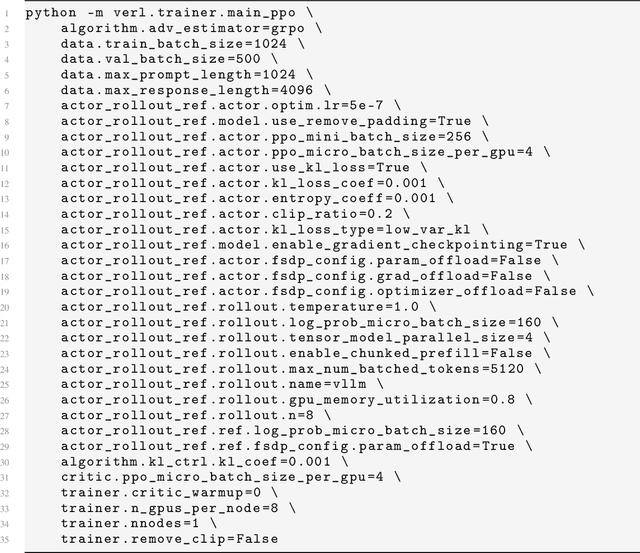
Reinforcement learning exhibits potential in enhancing the reasoning abilities of large language models, yet it is hard to scale for the low sample efficiency during the rollout phase. Existing methods attempt to improve efficiency by scheduling problems based on problem difficulties. However, these approaches suffer from unstable and biased estimations of problem difficulty and fail to capture the alignment between model competence and problem difficulty in RL training, leading to suboptimal results. To tackle these limitations, this paper introduces \textbf{C}ompetence-\textbf{D}ifficulty \textbf{A}lignment \textbf{S}ampling (\textbf{CDAS}), which enables accurate and stable estimation of problem difficulties by aggregating historical performance discrepancies of problems. Then the model competence is quantified to adaptively select problems whose difficulty is in alignment with the model's current competence using a fixed-point system. Experimental results across a range of challenging mathematical benchmarks show that CDAS achieves great improvements in both accuracy and efficiency. CDAS attains the highest average accuracy against baselines and exhibits significant speed advantages compared to Dynamic Sampling, a competitive strategy in DAPO, which is \textbf{2.33} times slower than CDAS.
Two Minds Better Than One: Collaborative Reward Modeling for LLM Alignment
May 19, 2025Reward models (RMs) play a pivotal role in aligning large language models (LLMs) with human values. However, noisy preferences in human feedback can lead to reward misgeneralization - a phenomenon where reward models learn spurious correlations or overfit to noisy preferences, which poses important challenges to the generalization of RMs. This paper systematically analyzes the characteristics of preference pairs and aims to identify how noisy preferences differ from human-aligned preferences in reward modeling. Our analysis reveals that noisy preferences are difficult for RMs to fit, as they cause sharp training fluctuations and irregular gradient updates. These distinctive dynamics suggest the feasibility of identifying and excluding such noisy preferences. Empirical studies demonstrate that policy LLM optimized with a reward model trained on the full preference dataset, which includes substantial noise, performs worse than the one trained on a subset of exclusively high quality preferences. To address this challenge, we propose an online Collaborative Reward Modeling (CRM) framework to achieve robust preference learning through peer review and curriculum learning. In particular, CRM maintains two RMs that collaboratively filter potential noisy preferences by peer-reviewing each other's data selections. Curriculum learning synchronizes the capabilities of two models, mitigating excessive disparities to promote the utility of peer review. Extensive experiments demonstrate that CRM significantly enhances RM generalization, with up to 9.94 points improvement on RewardBench under an extreme 40\% noise. Moreover, CRM can seamlessly extend to implicit-reward alignment methods, offering a robust and versatile alignment strategy.
Dynamic Fisher-weighted Model Merging via Bayesian Optimization
Apr 26, 2025



The fine-tuning of pre-trained language models has resulted in the widespread availability of task-specific models. Model merging offers an efficient way to create multi-task models by combining these fine-tuned models at the parameter level, without the need for training data or joint training on multiple datasets. Existing merging approaches typically involve scaling the parameters model-wise or integrating parameter importance parameter-wise. Both approaches exhibit their own weaknesses, leading to a notable performance gap compared to multi-task fine-tuning. In this paper, we unify these seemingly distinct strategies into a more general merging framework, and introduce Dynamic Fisher-weighted Merging (DF-Merge). Specifically, candidate models are associated with a set of coefficients that linearly scale their fine-tuned parameters. Bayesian optimization is applied to dynamically adjust these coefficients, aiming to maximize overall performance on validation sets. Each iteration of this process integrates parameter importance based on the Fisher information conditioned by the coefficients. Experimental results show that DF-Merge outperforms strong baselines across models of different sizes and a variety of tasks. Our analysis shows that the effectiveness of DF-Merge arises from the unified view of merging and that near-optimal performance is achievable in a few iterations, even with minimal validation data.