 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe limits of bio-molecular modeling with large language models : a cross-scale evaluation
Apr 03, 2026The modeling of bio-molecular system across molecular scales remains a central challenge in scientific research. Large language models (LLMs) are increasingly applied to bio-molecular discovery, yet systematic evaluation across multi-scale biological problems and rigorous assessment of their tool-augmented capabilities remain limited. We reveal a systematic gap between LLM performance and mechanistic understanding through the proposed cross-scale bio-molecular benchmark: BioMol-LLM-Bench, a unified framework comprising 26 downstream tasks that covers 4 distinct difficulty levels, and computational tools are integrated for a more comprehensive evaluation. Evaluation on 13 representative models reveals 4 main findings: chain-of-thought data provides limited benefit and may even reduce performance on biological tasks; hybrid mamba-attention architectures are more effective for long bio-molecular sequences; supervised fine-tuning improves specialization at the cost of generalization; and current LLMs perform well on classification tasks but remain weak on challenging regression tasks. Together, these findings provide practical guidance for future LLM-based modeling of molecular systems.
TCPO: Thought-Centric Preference Optimization for Effective Embodied Decision-making
Sep 10, 2025



Using effective generalization capabilities of vision language models (VLMs) in context-specific dynamic tasks for embodied artificial intelligence remains a significant challenge. Although supervised fine-tuned models can better align with the real physical world, they still exhibit sluggish responses and hallucination issues in dynamically changing environments, necessitating further alignment. Existing post-SFT methods, reliant on reinforcement learning and chain-of-thought (CoT) approaches, are constrained by sparse rewards and action-only optimization, resulting in low sample efficiency, poor consistency, and model degradation. To address these issues, this paper proposes Thought-Centric Preference Optimization (TCPO) for effective embodied decision-making. Specifically, TCPO introduces a stepwise preference-based optimization approach, transforming sparse reward signals into richer step sample pairs. It emphasizes the alignment of the model's intermediate reasoning process, mitigating the problem of model degradation. Moreover, by incorporating Action Policy Consistency Constraint (APC), it further imposes consistency constraints on the model output. Experiments in the ALFWorld environment demonstrate an average success rate of 26.67%, achieving a 6% improvement over RL4VLM and validating the effectiveness of our approach in mitigating model degradation after fine-tuning. These results highlight the potential of integrating preference-based learning techniques with CoT processes to enhance the decision-making capabilities of vision-language models in embodied agents.
Structure-Aware NeRF without Posed Camera via Epipolar Constraint
Oct 01, 2022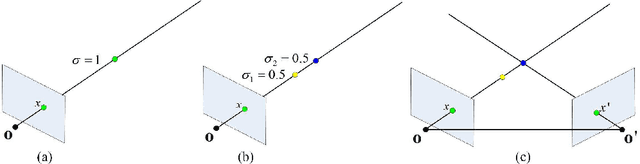
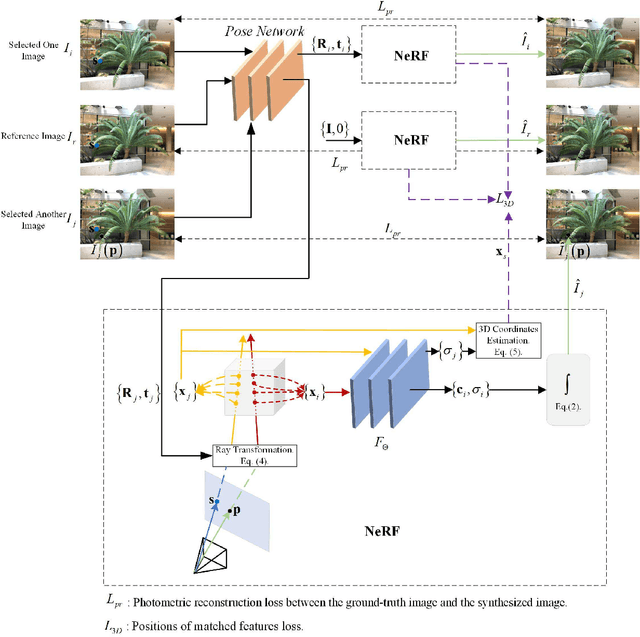


The neural radiance field (NeRF) for realistic novel view synthesis requires camera poses to be pre-acquired by a structure-from-motion (SfM) approach. This two-stage strategy is not convenient to use and degrades the performance because the error in the pose extraction can propagate to the view synthesis. We integrate the pose extraction and view synthesis into a single end-to-end procedure so they can benefit from each other. For training NeRF models, only RGB images are given, without pre-known camera poses. The camera poses are obtained by the epipolar constraint in which the identical feature in different views has the same world coordinates transformed from the local camera coordinates according to the extracted poses. The epipolar constraint is jointly optimized with pixel color constraint. The poses are represented by a CNN-based deep network, whose input is the related frames. This joint optimization enables NeRF to be aware of the scene's structure that has an improved generalization performance. Extensive experiments on a variety of scenes demonstrate the effectiveness of the proposed approach. Code is available at https://github.com/XTU-PR-LAB/SaNerf.