 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Correctness: Harmonizing Process and Outcome Rewards through RL Training
Sep 03, 2025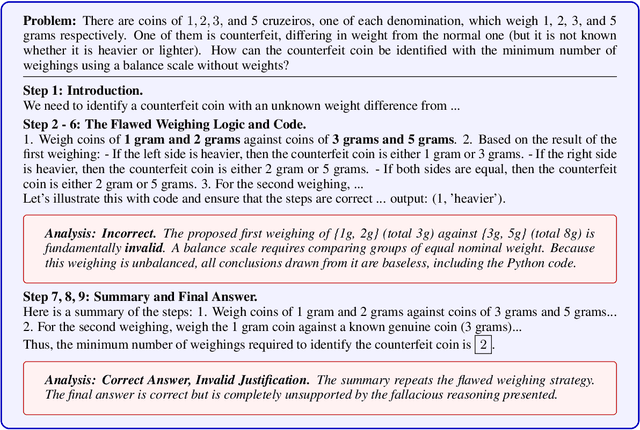

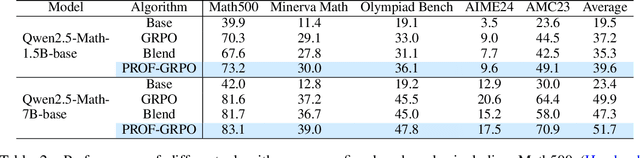
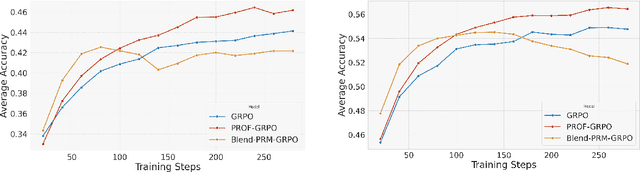
Reinforcement learning with verifiable rewards (RLVR) has emerged to be a predominant paradigm for mathematical reasoning tasks, offering stable improvements in reasoning ability. However, Outcome Reward Models (ORMs) in RLVR are too coarse-grained to distinguish flawed reasoning within correct answers or valid reasoning within incorrect answers. This lack of granularity introduces noisy and misleading gradients significantly and hinders further progress in reasoning process quality. While Process Reward Models (PRMs) offer fine-grained guidance for intermediate steps, they frequently suffer from inaccuracies and are susceptible to reward hacking. To resolve this dilemma, we introduce PRocess cOnsistency Filter (PROF), an effective data process curation method that harmonizes noisy, fine-grained process rewards with accurate, coarse-grained outcome rewards. Rather than naively blending PRM and ORM in the objective function (arXiv:archive/2506.18896), PROF leverages their complementary strengths through consistency-driven sample selection. Our approach retains correct responses with higher averaged process values and incorrect responses with lower averaged process values, while maintaining positive/negative training sample balance. Extensive experiments demonstrate that our method not only consistently improves the final accuracy over $4\%$ compared to the blending approaches, but also strengthens the quality of intermediate reasoning steps. Codes and training recipes are available at https://github.com/Chenluye99/PROF.
UItron: Foundational GUI Agent with Advanced Perception and Planning
Aug 29, 2025GUI agent aims to enable automated operations on Mobile/PC devices, which is an important task toward achieving artificial general intelligence. The rapid advancement of VLMs accelerates the development of GUI agents, owing to their powerful capabilities in visual understanding and task planning. However, building a GUI agent remains a challenging task due to the scarcity of operation trajectories, the availability of interactive infrastructure, and the limitation of initial capabilities in foundation models. In this work, we introduce UItron, an open-source foundational model for automatic GUI agents, featuring advanced GUI perception, grounding, and planning capabilities. UItron highlights the necessity of systemic data engineering and interactive infrastructure as foundational components for advancing GUI agent development. It not only systematically studies a series of data engineering strategies to enhance training effects, but also establishes an interactive environment connecting both Mobile and PC devices. In training, UItron adopts supervised finetuning over perception and planning tasks in various GUI scenarios, and then develop a curriculum reinforcement learning framework to enable complex reasoning and exploration for online environments. As a result, UItron achieves superior performance in benchmarks of GUI perception, grounding, and planning. In particular, UItron highlights the interaction proficiency with top-tier Chinese mobile APPs, as we identified a general lack of Chinese capabilities even in state-of-the-art solutions. To this end, we manually collect over one million steps of operation trajectories across the top 100 most popular apps, and build the offline and online agent evaluation environments. Experimental results demonstrate that UItron achieves significant progress in Chinese app scenarios, propelling GUI agents one step closer to real-world application.
DyCrowd: Towards Dynamic Crowd Reconstruction from a Large-scene Video
Aug 18, 20253D reconstruction of dynamic crowds in large scenes has become increasingly important for applications such as city surveillance and crowd analysis. However, current works attempt to reconstruct 3D crowds from a static image, causing a lack of temporal consistency and inability to alleviate the typical impact caused by occlusions. In this paper, we propose DyCrowd, the first framework for spatio-temporally consistent 3D reconstruction of hundreds of individuals' poses, positions and shapes from a large-scene video. We design a coarse-to-fine group-guided motion optimization strategy for occlusion-robust crowd reconstruction in large scenes. To address temporal instability and severe occlusions, we further incorporate a VAE (Variational Autoencoder)-based human motion prior along with a segment-level group-guided optimization. The core of our strategy leverages collective crowd behavior to address long-term dynamic occlusions. By jointly optimizing the motion sequences of individuals with similar motion segments and combining this with the proposed Asynchronous Motion Consistency (AMC) loss, we enable high-quality unoccluded motion segments to guide the motion recovery of occluded ones, ensuring robust and plausible motion recovery even in the presence of temporal desynchronization and rhythmic inconsistencies. Additionally, in order to fill the gap of no existing well-annotated large-scene video dataset, we contribute a virtual benchmark dataset, VirtualCrowd, for evaluating dynamic crowd reconstruction from large-scene videos. Experimental results demonstrate that the proposed method achieves state-of-the-art performance in the large-scene dynamic crowd reconstruction task. The code and dataset will be available for research purposes.
DocTron-Formula: Generalized Formula Recognition in Complex and Structured Scenarios
Aug 01, 2025

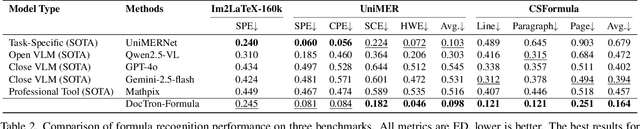
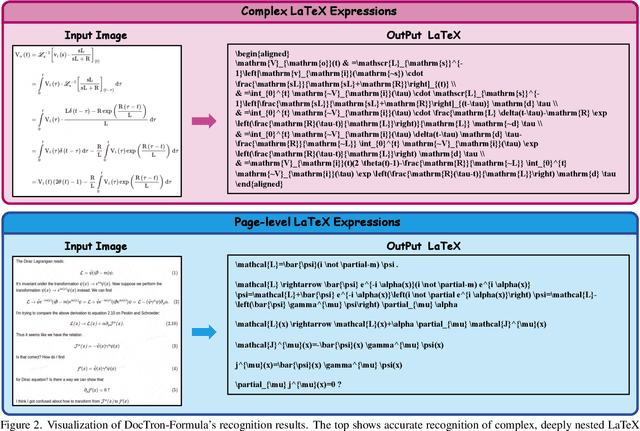
Optical Character Recognition (OCR) for mathematical formula is essential for the intelligent analysis of scientific literature. However, both task-specific and general vision-language models often struggle to handle the structural diversity, complexity, and real-world variability inherent in mathematical content. In this work, we present DocTron-Formula, a unified framework built upon general vision-language models, thereby eliminating the need for specialized architectures. Furthermore, we introduce CSFormula, a large-scale and challenging dataset that encompasses multidisciplinary and structurally complex formulas at the line, paragraph, and page levels. Through straightforward supervised fine-tuning, our approach achieves state-of-the-art performance across a variety of styles, scientific domains, and complex layouts. Experimental results demonstrate that our method not only surpasses specialized models in terms of accuracy and robustness, but also establishes a new paradigm for the automated understanding of complex scientific documents.
Multi-Agent-as-Judge: Aligning LLM-Agent-Based Automated Evaluation with Multi-Dimensional Human Evaluation
Jul 28, 2025



Nearly all human work is collaborative; thus, the evaluation of real-world NLP applications often requires multiple dimensions that align with diverse human perspectives. As real human evaluator resources are often scarce and costly, the emerging "LLM-as-a-judge" paradigm sheds light on a promising approach to leverage LLM agents to believably simulate human evaluators. Yet, to date, existing LLM-as-a-judge approaches face two limitations: persona descriptions of agents are often arbitrarily designed, and the frameworks are not generalizable to other tasks. To address these challenges, we propose MAJ-EVAL, a Multi-Agent-as-Judge evaluation framework that can automatically construct multiple evaluator personas with distinct dimensions from relevant text documents (e.g., research papers), instantiate LLM agents with the personas, and engage in-group debates with multi-agents to Generate multi-dimensional feedback. Our evaluation experiments in both the educational and medical domains demonstrate that MAJ-EVAL can generate evaluation results that better align with human experts' ratings compared with conventional automated evaluation metrics and existing LLM-as-a-judge methods.
RESCUE: Crowd Evacuation Simulation via Controlling SDM-United Characters
Jul 27, 2025



Crowd evacuation simulation is critical for enhancing public safety, and demanded for realistic virtual environments. Current mainstream evacuation models overlook the complex human behaviors that occur during evacuation, such as pedestrian collisions, interpersonal interactions, and variations in behavior influenced by terrain types or individual body shapes. This results in the failure to accurately simulate the escape of people in the real world. In this paper, aligned with the sensory-decision-motor (SDM) flow of the human brain, we propose a real-time 3D crowd evacuation simulation framework that integrates a 3D-adaptive SFM (Social Force Model) Decision Mechanism and a Personalized Gait Control Motor. This framework allows multiple agents to move in parallel and is suitable for various scenarios, with dynamic crowd awareness. Additionally, we introduce Part-level Force Visualization to assist in evacuation analysis. Experimental results demonstrate that our framework supports dynamic trajectory planning and personalized behavior for each agent throughout the evacuation process, and is compatible with uneven terrain. Visually, our method generates evacuation results that are more realistic and plausible, providing enhanced insights for crowd simulation. The code is available at http://cic.tju.edu.cn/faculty/likun/projects/RESCUE.
LLMs Encode Harmfulness and Refusal Separately
Jul 16, 2025LLMs are trained to refuse harmful instructions, but do they truly understand harmfulness beyond just refusing? Prior work has shown that LLMs' refusal behaviors can be mediated by a one-dimensional subspace, i.e., a refusal direction. In this work, we identify a new dimension to analyze safety mechanisms in LLMs, i.e., harmfulness, which is encoded internally as a separate concept from refusal. There exists a harmfulness direction that is distinct from the refusal direction. As causal evidence, steering along the harmfulness direction can lead LLMs to interpret harmless instructions as harmful, but steering along the refusal direction tends to elicit refusal responses directly without reversing the model's judgment on harmfulness. Furthermore, using our identified harmfulness concept, we find that certain jailbreak methods work by reducing the refusal signals without reversing the model's internal belief of harmfulness. We also find that adversarially finetuning models to accept harmful instructions has minimal impact on the model's internal belief of harmfulness. These insights lead to a practical safety application: The model's latent harmfulness representation can serve as an intrinsic safeguard (Latent Guard) for detecting unsafe inputs and reducing over-refusals that is robust to finetuning attacks. For instance, our Latent Guard achieves performance comparable to or better than Llama Guard 3 8B, a dedicated finetuned safeguard model, across different jailbreak methods. Our findings suggest that LLMs' internal understanding of harmfulness is more robust than their refusal decision to diverse input instructions, offering a new perspective to study AI safety
OPeRA: A Dataset of Observation, Persona, Rationale, and Action for Evaluating LLMs on Human Online Shopping Behavior Simulation
Jun 05, 2025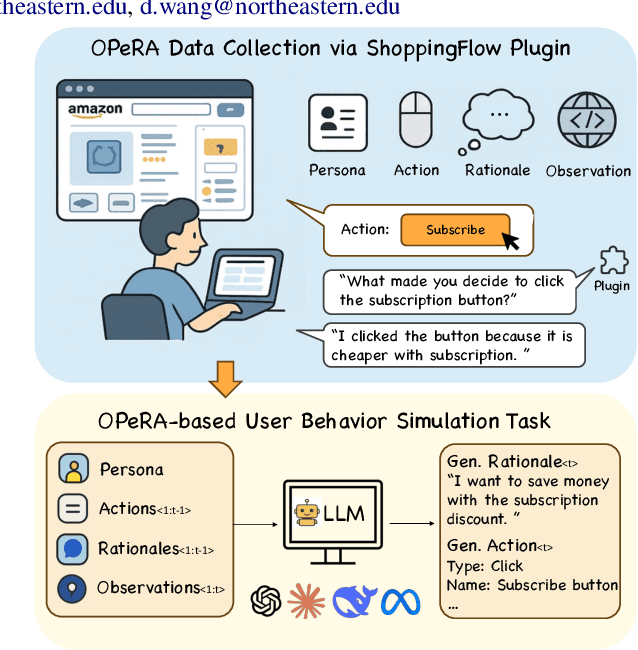
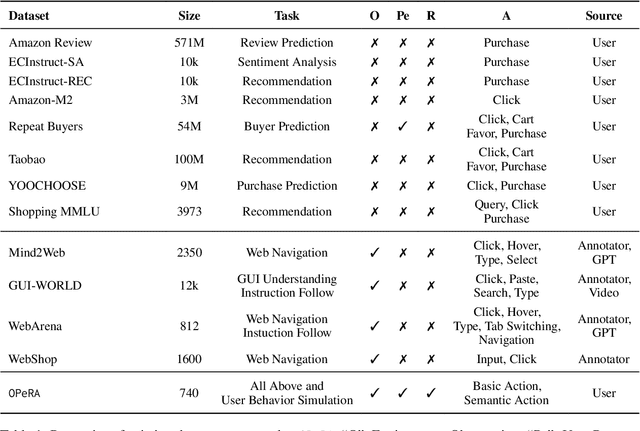
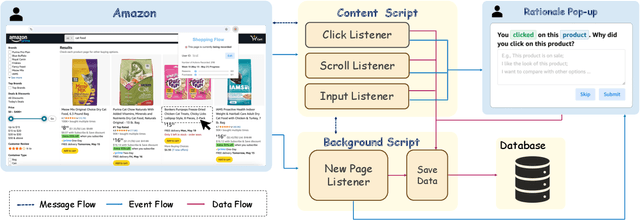
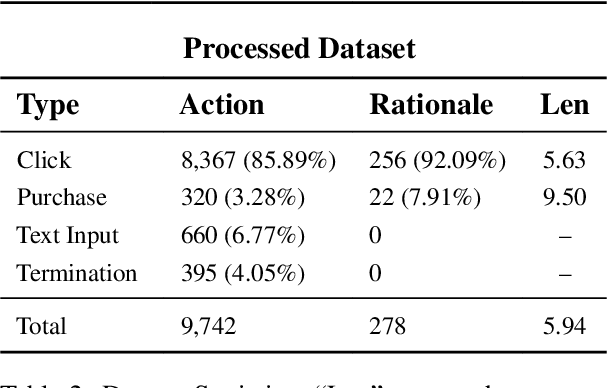
Can large language models (LLMs) accurately simulate the next web action of a specific user? While LLMs have shown promising capabilities in generating ``believable'' human behaviors, evaluating their ability to mimic real user behaviors remains an open challenge, largely due to the lack of high-quality, publicly available datasets that capture both the observable actions and the internal reasoning of an actual human user. To address this gap, we introduce OPERA, a novel dataset of Observation, Persona, Rationale, and Action collected from real human participants during online shopping sessions. OPERA is the first public dataset that comprehensively captures: user personas, browser observations, fine-grained web actions, and self-reported just-in-time rationales. We developed both an online questionnaire and a custom browser plugin to gather this dataset with high fidelity. Using OPERA, we establish the first benchmark to evaluate how well current LLMs can predict a specific user's next action and rationale with a given persona and <observation, action, rationale> history. This dataset lays the groundwork for future research into LLM agents that aim to act as personalized digital twins for human.
ACM-UNet: Adaptive Integration of CNNs and Mamba for Efficient Medical Image Segmentation
May 30, 2025The U-shaped encoder-decoder architecture with skip connections has become a prevailing paradigm in medical image segmentation due to its simplicity and effectiveness. While many recent works aim to improve this framework by designing more powerful encoders and decoders, employing advanced convolutional neural networks (CNNs) for local feature extraction, Transformers or state space models (SSMs) such as Mamba for global context modeling, or hybrid combinations of both, these methods often struggle to fully utilize pretrained vision backbones (e.g., ResNet, ViT, VMamba) due to structural mismatches. To bridge this gap, we introduce ACM-UNet, a general-purpose segmentation framework that retains a simple UNet-like design while effectively incorporating pretrained CNNs and Mamba models through a lightweight adapter mechanism. This adapter resolves architectural incompatibilities and enables the model to harness the complementary strengths of CNNs and SSMs-namely, fine-grained local detail extraction and long-range dependency modeling. Additionally, we propose a hierarchical multi-scale wavelet transform module in the decoder to enhance feature fusion and reconstruction fidelity. Extensive experiments on the Synapse and ACDC benchmarks demonstrate that ACM-UNet achieves state-of-the-art performance while remaining computationally efficient. Notably, it reaches 85.12% Dice Score and 13.89mm HD95 on the Synapse dataset with 17.93G FLOPs, showcasing its effectiveness and scalability. Code is available at: https://github.com/zyklcode/ACM-UNet.
GIM: Improved Interpretability for Large Language Models
May 23, 2025Ensuring faithful interpretability in large language models is imperative for trustworthy and reliable AI. A key obstacle is self-repair, a phenomenon where networks compensate for reduced signal in one component by amplifying others, masking the true importance of the ablated component. While prior work attributes self-repair to layer normalization and back-up components that compensate for ablated components, we identify a novel form occurring within the attention mechanism, where softmax redistribution conceals the influence of important attention scores. This leads traditional ablation and gradient-based methods to underestimate the significance of all components contributing to these attention scores. We introduce Gradient Interaction Modifications (GIM), a technique that accounts for self-repair during backpropagation. Extensive experiments across multiple large language models (Gemma 2B/9B, LLAMA 1B/3B/8B, Qwen 1.5B/3B) and diverse tasks demonstrate that GIM significantly improves faithfulness over existing circuit identification and feature attribution methods. Our work is a significant step toward better understanding the inner mechanisms of LLMs, which is crucial for improving them and ensuring their safety. Our code is available at https://github.com/JoakimEdin/gim.