 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTRIM: Hybrid Inference via Targeted Stepwise Routing in Multi-Step Reasoning Tasks
Jan 15, 2026Multi-step reasoning tasks like mathematical problem solving are vulnerable to cascading failures, where a single incorrect step leads to complete solution breakdown. Current LLM routing methods assign entire queries to one model, treating all reasoning steps as equal. We propose TRIM (Targeted routing in multi-step reasoning tasks), which routes only critical steps$\unicode{x2013}$those likely to derail the solution$\unicode{x2013}$to larger models while letting smaller models handle routine continuations. Our key insight is that targeted step-level interventions can fundamentally transform inference efficiency by confining expensive calls to precisely those steps where stronger models prevent cascading errors. TRIM operates at the step-level: it uses process reward models to identify erroneous steps and makes routing decisions based on step-level uncertainty and budget constraints. We develop several routing strategies within TRIM, ranging from a simple threshold-based policy to more expressive policies that reason about long-horizon accuracy-cost trade-offs and uncertainty in step-level correctness estimates. On MATH-500, even the simplest thresholding strategy surpasses prior routing methods with 5x higher cost efficiency, while more advanced policies match the strong, expensive model's performance using 80% fewer expensive model tokens. On harder benchmarks such as AIME, TRIM achieves up to 6x higher cost efficiency. All methods generalize effectively across math reasoning tasks, demonstrating that step-level difficulty represents fundamental characteristics of reasoning.
Beyond Correctness: Harmonizing Process and Outcome Rewards through RL Training
Sep 03, 2025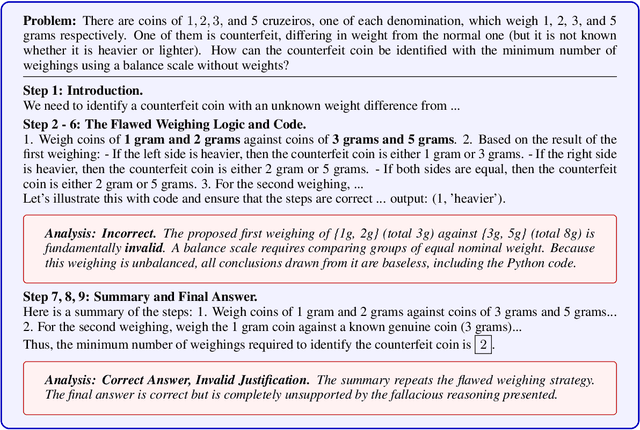

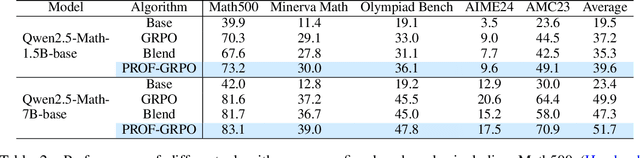
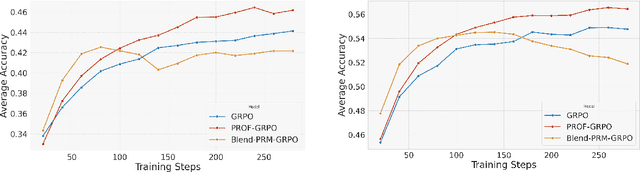
Reinforcement learning with verifiable rewards (RLVR) has emerged to be a predominant paradigm for mathematical reasoning tasks, offering stable improvements in reasoning ability. However, Outcome Reward Models (ORMs) in RLVR are too coarse-grained to distinguish flawed reasoning within correct answers or valid reasoning within incorrect answers. This lack of granularity introduces noisy and misleading gradients significantly and hinders further progress in reasoning process quality. While Process Reward Models (PRMs) offer fine-grained guidance for intermediate steps, they frequently suffer from inaccuracies and are susceptible to reward hacking. To resolve this dilemma, we introduce PRocess cOnsistency Filter (PROF), an effective data process curation method that harmonizes noisy, fine-grained process rewards with accurate, coarse-grained outcome rewards. Rather than naively blending PRM and ORM in the objective function (arXiv:archive/2506.18896), PROF leverages their complementary strengths through consistency-driven sample selection. Our approach retains correct responses with higher averaged process values and incorrect responses with lower averaged process values, while maintaining positive/negative training sample balance. Extensive experiments demonstrate that our method not only consistently improves the final accuracy over $4\%$ compared to the blending approaches, but also strengthens the quality of intermediate reasoning steps. Codes and training recipes are available at https://github.com/Chenluye99/PROF.
When Thinking Fails: The Pitfalls of Reasoning for Instruction-Following in LLMs
May 16, 2025Reasoning-enhanced large language models (RLLMs), whether explicitly trained for reasoning or prompted via chain-of-thought (CoT), have achieved state-of-the-art performance on many complex reasoning tasks. However, we uncover a surprising and previously overlooked phenomenon: explicit CoT reasoning can significantly degrade instruction-following accuracy. Evaluating 15 models on two benchmarks: IFEval (with simple, rule-verifiable constraints) and ComplexBench (with complex, compositional constraints), we consistently observe performance drops when CoT prompting is applied. Through large-scale case studies and an attention-based analysis, we identify common patterns where reasoning either helps (e.g., with formatting or lexical precision) or hurts (e.g., by neglecting simple constraints or introducing unnecessary content). We propose a metric, constraint attention, to quantify model focus during generation and show that CoT reasoning often diverts attention away from instruction-relevant tokens. To mitigate these effects, we introduce and evaluate four strategies: in-context learning, self-reflection, self-selective reasoning, and classifier-selective reasoning. Our results demonstrate that selective reasoning strategies, particularly classifier-selective reasoning, can substantially recover lost performance. To our knowledge, this is the first work to systematically expose reasoning-induced failures in instruction-following and offer practical mitigation strategies.
Semantic Volume: Quantifying and Detecting both External and Internal Uncertainty in LLMs
Feb 28, 2025Large language models (LLMs) have demonstrated remarkable performance across diverse tasks by encoding vast amounts of factual knowledge. However, they are still prone to hallucinations, generating incorrect or misleading information, often accompanied by high uncertainty. Existing methods for hallucination detection primarily focus on quantifying internal uncertainty, which arises from missing or conflicting knowledge within the model. However, hallucinations can also stem from external uncertainty, where ambiguous user queries lead to multiple possible interpretations. In this work, we introduce Semantic Volume, a novel mathematical measure for quantifying both external and internal uncertainty in LLMs. Our approach perturbs queries and responses, embeds them in a semantic space, and computes the determinant of the Gram matrix of the embedding vectors, capturing their dispersion as a measure of uncertainty. Our framework provides a generalizable and unsupervised uncertainty detection method without requiring white-box access to LLMs. We conduct extensive experiments on both external and internal uncertainty detection, demonstrating that our Semantic Volume method consistently outperforms existing baselines in both tasks. Additionally, we provide theoretical insights linking our measure to differential entropy, unifying and extending previous sampling-based uncertainty measures such as the semantic entropy. Semantic Volume is shown to be a robust and interpretable approach to improving the reliability of LLMs by systematically detecting uncertainty in both user queries and model responses.
DARD: A Multi-Agent Approach for Task-Oriented Dialog Systems
Nov 01, 2024



Task-oriented dialogue systems are essential for applications ranging from customer service to personal assistants and are widely used across various industries. However, developing effective multi-domain systems remains a significant challenge due to the complexity of handling diverse user intents, entity types, and domain-specific knowledge across several domains. In this work, we propose DARD (Domain Assigned Response Delegation), a multi-agent conversational system capable of successfully handling multi-domain dialogs. DARD leverages domain-specific agents, orchestrated by a central dialog manager agent. Our extensive experiments compare and utilize various agent modeling approaches, combining the strengths of smaller fine-tuned models (Flan-T5-large & Mistral-7B) with their larger counterparts, Large Language Models (LLMs) (Claude Sonnet 3.0). We provide insights into the strengths and limitations of each approach, highlighting the benefits of our multi-agent framework in terms of flexibility and composability. We evaluate DARD using the well-established MultiWOZ benchmark, achieving state-of-the-art performance by improving the dialogue inform rate by 6.6% and the success rate by 4.1% over the best-performing existing approaches. Additionally, we discuss various annotator discrepancies and issues within the MultiWOZ dataset and its evaluation system.
RecXplainer: Post-Hoc Attribute-Based Explanations for Recommender Systems
Nov 27, 2022Recommender systems are ubiquitous in most of our interactions in the current digital world. Whether shopping for clothes, scrolling YouTube for exciting videos, or searching for restaurants in a new city, the recommender systems at the back-end power these services. Most large-scale recommender systems are huge models trained on extensive datasets and are black-boxes to both their developers and end-users. Prior research has shown that providing recommendations along with their reason enhances trust, scrutability, and persuasiveness of the recommender systems. Recent literature in explainability has been inundated with works proposing several algorithms to this end. Most of these works provide item-style explanations, i.e., `We recommend item A because you bought item B.' We propose a novel approach, RecXplainer, to generate more fine-grained explanations based on the user's preference over the attributes of the recommended items. We perform experiments using real-world datasets and demonstrate the efficacy of RecXplainer in capturing users' preferences and using them to explain recommendations. We also propose ten new evaluation metrics and compare RecXplainer to six baseline methods.
Contrastive Learning for Interactive Recommendation in Fashion
Jul 25, 2022
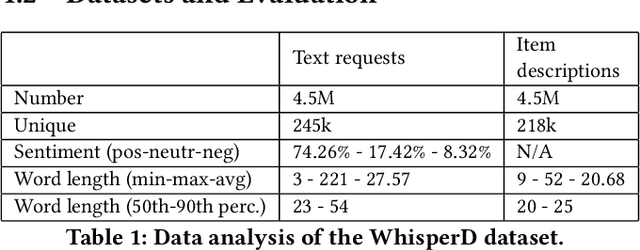
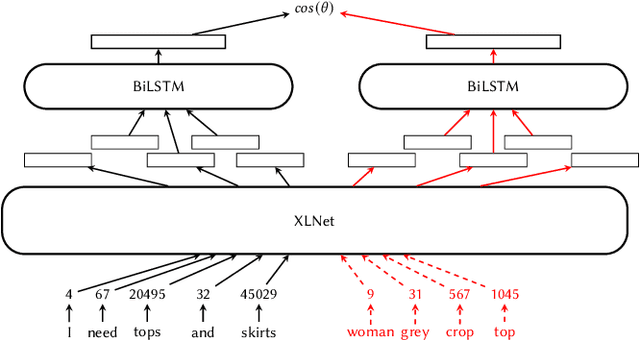
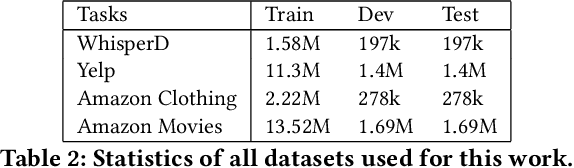
Recommender systems and search are both indispensable in facilitating personalization and ease of browsing in online fashion platforms. However, the two tools often operate independently, failing to combine the strengths of recommender systems to accurately capture user tastes with search systems' ability to process user queries. We propose a novel remedy to this problem by automatically recommending personalized fashion items based on a user-provided text request. Our proposed model, WhisperLite, uses contrastive learning to capture user intent from natural language text and improves the recommendation quality of fashion products. WhisperLite combines the strength of CLIP embeddings with additional neural network layers for personalization, and is trained using a composite loss function based on binary cross entropy and contrastive loss. The model demonstrates a significant improvement in offline recommendation retrieval metrics when tested on a real-world dataset collected from an online retail fashion store, as well as widely used open-source datasets in different e-commerce domains, such as restaurants, movies and TV shows, clothing and shoe reviews. We additionally conduct a user study that captures user judgements on the relevance of the model's recommended items, confirming the relevancy of WhisperLite's recommendations in an online setting.
OutfitTransformer: Learning Outfit Representations for Fashion Recommendation
Apr 15, 2022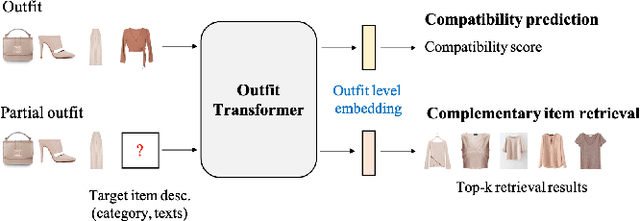

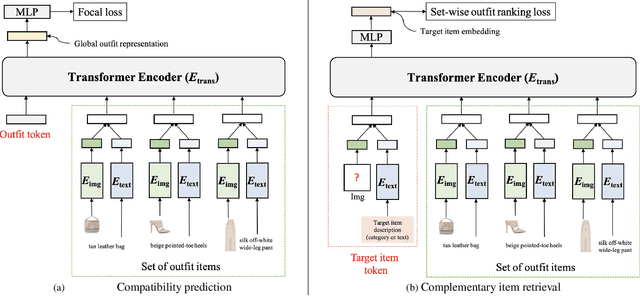
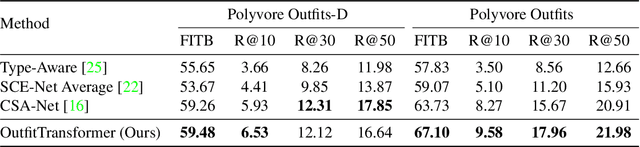
Learning an effective outfit-level representation is critical for predicting the compatibility of items in an outfit, and retrieving complementary items for a partial outfit. We present a framework, OutfitTransformer, that uses the proposed task-specific tokens and leverages the self-attention mechanism to learn effective outfit-level representations encoding the compatibility relationships between all items in the entire outfit for addressing both compatibility prediction and complementary item retrieval tasks. For compatibility prediction, we design an outfit token to capture a global outfit representation and train the framework using a classification loss. For complementary item retrieval, we design a target item token that additionally takes the target item specification (in the form of a category or text description) into consideration. We train our framework using a proposed set-wise outfit ranking loss to generate a target item embedding given an outfit, and a target item specification as inputs. The generated target item embedding is then used to retrieve compatible items that match the rest of the outfit. Additionally, we adopt a pre-training approach and a curriculum learning strategy to improve retrieval performance. Since our framework learns at an outfit-level, it allows us to learn a single embedding capturing higher-order relations among multiple items in the outfit more effectively than pairwise methods. Experiments demonstrate that our approach outperforms state-of-the-art methods on compatibility prediction, fill-in-the-blank, and complementary item retrieval tasks. We further validate the quality of our retrieval results with a user study.