 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExecTune: Effective Steering of Black-Box LLMs with Guide Models
Apr 09, 2026For large language models deployed through black-box APIs, recurring inference costs often exceed one-time training costs. This motivates composed agentic systems that amortize expensive reasoning into reusable intermediate representations. We study a broad class of such systems, termed Guide-Core Policies (GCoP), in which a guide model generates a structured strategy that is executed by a black-box core model. This abstraction subsumes base, supervised, and advisor-style approaches, which differ primarily in how the guide is trained. We formalize GCoP under a cost-sensitive utility objective and show that end-to-end performance is governed by guide-averaged executability: the probability that a strategy generated by the guide can be faithfully executed by the core. Our analysis shows that existing GCoP instantiations often fail to optimize executability under deployment constraints, resulting in brittle strategies and inefficient computation. Motivated by these insights, we propose ExecTune, a principled training recipe that combines teacher-guided acceptance sampling, supervised fine-tuning, and structure-aware reinforcement learning to directly optimize syntactic validity, execution success, and cost efficiency. Across mathematical reasoning and code-generation benchmarks, GCoP with ExecTune improves accuracy by up to 9.2% over prior state-of-the-art baselines while reducing inference cost by up to 22.4%. It enables Claude Haiku 3.5 to outperform Sonnet 3.5 on both math and code tasks, and to come within 1.7% absolute accuracy of Sonnet 4 at 38% lower cost. Beyond efficiency, GCoP also supports modular adaptation by updating the guide without retraining the core.
Beyond Correctness: Harmonizing Process and Outcome Rewards through RL Training
Sep 03, 2025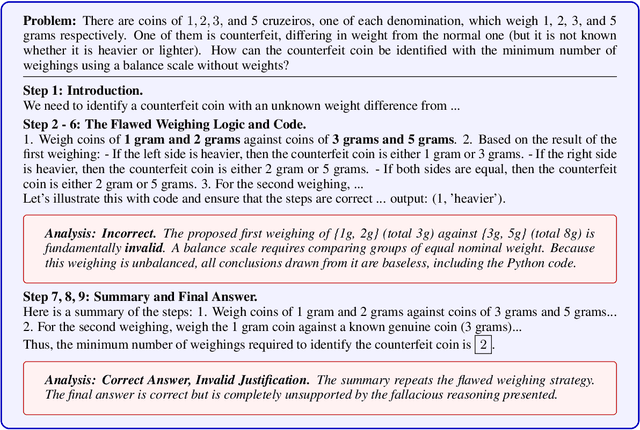

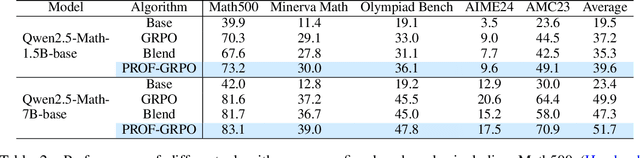
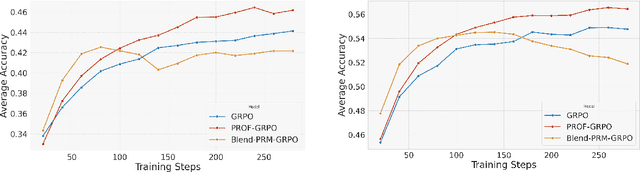
Reinforcement learning with verifiable rewards (RLVR) has emerged to be a predominant paradigm for mathematical reasoning tasks, offering stable improvements in reasoning ability. However, Outcome Reward Models (ORMs) in RLVR are too coarse-grained to distinguish flawed reasoning within correct answers or valid reasoning within incorrect answers. This lack of granularity introduces noisy and misleading gradients significantly and hinders further progress in reasoning process quality. While Process Reward Models (PRMs) offer fine-grained guidance for intermediate steps, they frequently suffer from inaccuracies and are susceptible to reward hacking. To resolve this dilemma, we introduce PRocess cOnsistency Filter (PROF), an effective data process curation method that harmonizes noisy, fine-grained process rewards with accurate, coarse-grained outcome rewards. Rather than naively blending PRM and ORM in the objective function (arXiv:archive/2506.18896), PROF leverages their complementary strengths through consistency-driven sample selection. Our approach retains correct responses with higher averaged process values and incorrect responses with lower averaged process values, while maintaining positive/negative training sample balance. Extensive experiments demonstrate that our method not only consistently improves the final accuracy over $4\%$ compared to the blending approaches, but also strengthens the quality of intermediate reasoning steps. Codes and training recipes are available at https://github.com/Chenluye99/PROF.
When Thinking Fails: The Pitfalls of Reasoning for Instruction-Following in LLMs
May 16, 2025Reasoning-enhanced large language models (RLLMs), whether explicitly trained for reasoning or prompted via chain-of-thought (CoT), have achieved state-of-the-art performance on many complex reasoning tasks. However, we uncover a surprising and previously overlooked phenomenon: explicit CoT reasoning can significantly degrade instruction-following accuracy. Evaluating 15 models on two benchmarks: IFEval (with simple, rule-verifiable constraints) and ComplexBench (with complex, compositional constraints), we consistently observe performance drops when CoT prompting is applied. Through large-scale case studies and an attention-based analysis, we identify common patterns where reasoning either helps (e.g., with formatting or lexical precision) or hurts (e.g., by neglecting simple constraints or introducing unnecessary content). We propose a metric, constraint attention, to quantify model focus during generation and show that CoT reasoning often diverts attention away from instruction-relevant tokens. To mitigate these effects, we introduce and evaluate four strategies: in-context learning, self-reflection, self-selective reasoning, and classifier-selective reasoning. Our results demonstrate that selective reasoning strategies, particularly classifier-selective reasoning, can substantially recover lost performance. To our knowledge, this is the first work to systematically expose reasoning-induced failures in instruction-following and offer practical mitigation strategies.
DARD: A Multi-Agent Approach for Task-Oriented Dialog Systems
Nov 01, 2024



Task-oriented dialogue systems are essential for applications ranging from customer service to personal assistants and are widely used across various industries. However, developing effective multi-domain systems remains a significant challenge due to the complexity of handling diverse user intents, entity types, and domain-specific knowledge across several domains. In this work, we propose DARD (Domain Assigned Response Delegation), a multi-agent conversational system capable of successfully handling multi-domain dialogs. DARD leverages domain-specific agents, orchestrated by a central dialog manager agent. Our extensive experiments compare and utilize various agent modeling approaches, combining the strengths of smaller fine-tuned models (Flan-T5-large & Mistral-7B) with their larger counterparts, Large Language Models (LLMs) (Claude Sonnet 3.0). We provide insights into the strengths and limitations of each approach, highlighting the benefits of our multi-agent framework in terms of flexibility and composability. We evaluate DARD using the well-established MultiWOZ benchmark, achieving state-of-the-art performance by improving the dialogue inform rate by 6.6% and the success rate by 4.1% over the best-performing existing approaches. Additionally, we discuss various annotator discrepancies and issues within the MultiWOZ dataset and its evaluation system.
AXCEL: Automated eXplainable Consistency Evaluation using LLMs
Sep 25, 2024



Large Language Models (LLMs) are widely used in both industry and academia for various tasks, yet evaluating the consistency of generated text responses continues to be a challenge. Traditional metrics like ROUGE and BLEU show a weak correlation with human judgment. More sophisticated metrics using Natural Language Inference (NLI) have shown improved correlations but are complex to implement, require domain-specific training due to poor cross-domain generalization, and lack explainability. More recently, prompt-based metrics using LLMs as evaluators have emerged; while they are easier to implement, they still lack explainability and depend on task-specific prompts, which limits their generalizability. This work introduces Automated eXplainable Consistency Evaluation using LLMs (AXCEL), a prompt-based consistency metric which offers explanations for the consistency scores by providing detailed reasoning and pinpointing inconsistent text spans. AXCEL is also a generalizable metric which can be adopted to multiple tasks without changing the prompt. AXCEL outperforms both non-prompt and prompt-based state-of-the-art (SOTA) metrics in detecting inconsistencies across summarization by 8.7%, free text generation by 6.2%, and data-to-text conversion tasks by 29.4%. We also evaluate the influence of underlying LLMs on prompt based metric performance and recalibrate the SOTA prompt-based metrics with the latest LLMs for fair comparison. Further, we show that AXCEL demonstrates strong performance using open source LLMs.
PATCorrect: Non-autoregressive Phoneme-augmented Transformer for ASR Error Correction
Feb 10, 2023Speech-to-text errors made by automatic speech recognition (ASR) system negatively impact downstream models relying on ASR transcriptions. Language error correction models as a post-processing text editing approach have been recently developed for refining the source sentences. However, efficient models for correcting errors in ASR transcriptions that meet the low latency requirements of industrial grade production systems have not been well studied. In this work, we propose a novel non-autoregressive (NAR) error correction approach to improve the transcription quality by reducing word error rate (WER) and achieve robust performance across different upstream ASR systems. Our approach augments the text encoding of the Transformer model with a phoneme encoder that embeds pronunciation information. The representations from phoneme encoder and text encoder are combined via multi-modal fusion before feeding into the length tagging predictor for predicting target sequence lengths. The joint encoders also provide inputs to the attention mechanism in the NAR decoder. We experiment on 3 open-source ASR systems with varying speech-to-text transcription quality and their erroneous transcriptions on 2 public English corpus datasets. Results show that our PATCorrect (Phoneme Augmented Transformer for ASR error Correction) consistently outperforms state-of-the-art NAR error correction method on English corpus across different upstream ASR systems. For example, PATCorrect achieves 11.62% WER reduction (WERR) averaged on 3 ASR systems compared to 9.46% WERR achieved by other method using text only modality and also achieves an inference latency comparable to other NAR models at tens of millisecond scale, especially on GPU hardware, while still being 4.2 - 6.7x times faster than autoregressive models on Common Voice and LibriSpeech datasets.
RecXplainer: Post-Hoc Attribute-Based Explanations for Recommender Systems
Nov 27, 2022Recommender systems are ubiquitous in most of our interactions in the current digital world. Whether shopping for clothes, scrolling YouTube for exciting videos, or searching for restaurants in a new city, the recommender systems at the back-end power these services. Most large-scale recommender systems are huge models trained on extensive datasets and are black-boxes to both their developers and end-users. Prior research has shown that providing recommendations along with their reason enhances trust, scrutability, and persuasiveness of the recommender systems. Recent literature in explainability has been inundated with works proposing several algorithms to this end. Most of these works provide item-style explanations, i.e., `We recommend item A because you bought item B.' We propose a novel approach, RecXplainer, to generate more fine-grained explanations based on the user's preference over the attributes of the recommended items. We perform experiments using real-world datasets and demonstrate the efficacy of RecXplainer in capturing users' preferences and using them to explain recommendations. We also propose ten new evaluation metrics and compare RecXplainer to six baseline methods.
Contextual Multi-Armed Bandits for Causal Marketing
Oct 02, 2018
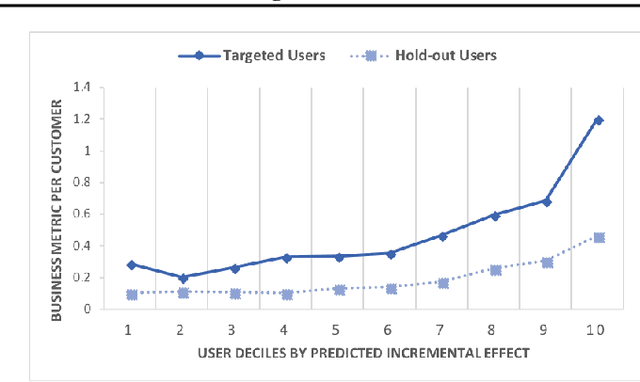
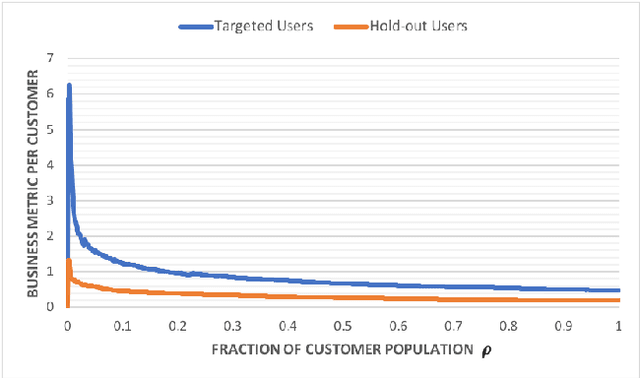
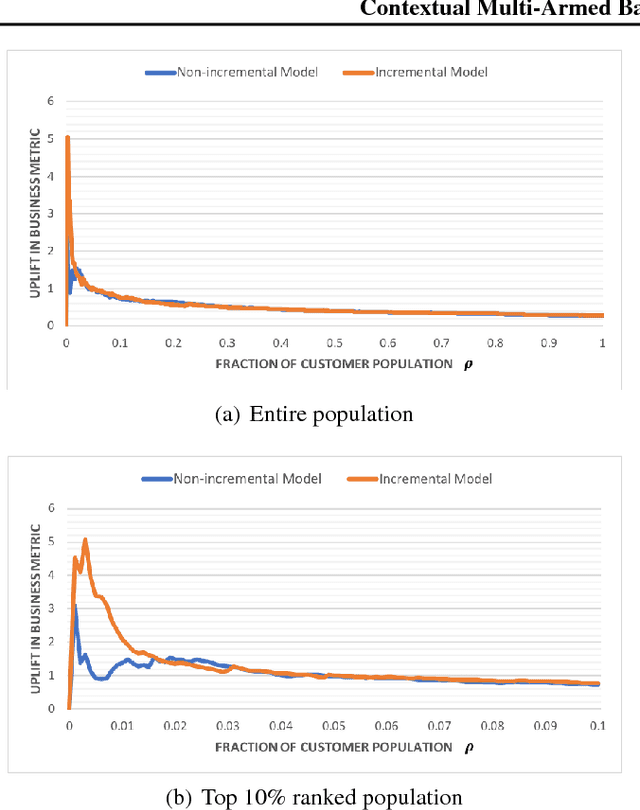
This work explores the idea of a causal contextual multi-armed bandit approach to automated marketing, where we estimate and optimize the causal (incremental) effects. Focusing on causal effect leads to better return on investment (ROI) by targeting only the persuadable customers who wouldn't have taken the action organically. Our approach draws on strengths of causal inference, uplift modeling, and multi-armed bandits. It optimizes on causal treatment effects rather than pure outcome, and incorporates counterfactual generation within data collection. Following uplift modeling results, we optimize over the incremental business metric. Multi-armed bandit methods allow us to scale to multiple treatments and to perform off-policy policy evaluation on logged data. The Thompson sampling strategy in particular enables exploration of treatments on similar customer contexts and materialization of counterfactual outcomes. Preliminary offline experiments on a retail Fashion marketing dataset show merits of our proposal.