 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRegion Comparison Network for Interpretable Few-shot Image Classification
Sep 08, 2020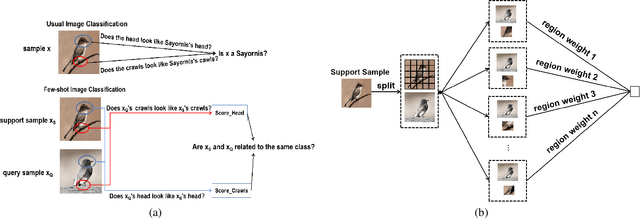
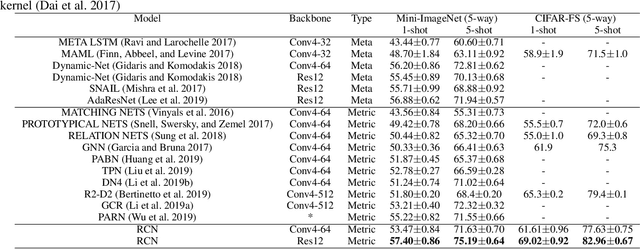
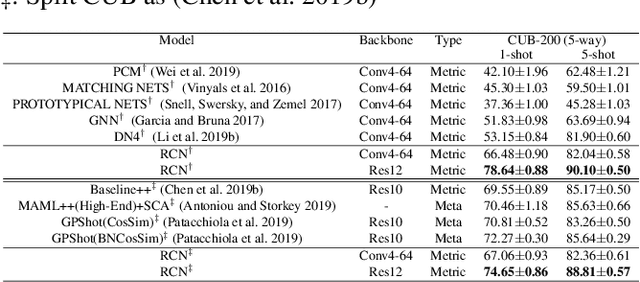
While deep learning has been successfully applied to many real-world computer vision tasks, training robust classifiers usually requires a large amount of well-labeled data. However, the annotation is often expensive and time-consuming. Few-shot image classification has thus been proposed to effectively use only a limited number of labeled examples to train models for new classes. Recent works based on transferable metric learning methods have achieved promising classification performance through learning the similarity between the features of samples from the query and support sets. However, rare of them explicitly considers the model interpretability, which can actually be revealed during the training phase. For that, in this work, we propose a metric learning based method named Region Comparison Network (RCN), which is able to reveal how few-shot learning works as in a neural network as well as to find out specific regions that are related to each other in images coming from the query and support sets. Moreover, we also present a visualization strategy named Region Activation Mapping (RAM) to intuitively explain what our method has learned by visualizing intermediate variables in our network. We also present a new way to generalize the interpretability from the level of tasks to categories, which can also be viewed as a method to find the prototypical parts for supporting the final decision of our RCN. Extensive experiments on four benchmark datasets clearly show the effectiveness of our method over existing baselines.
Dynamic Context-guided Capsule Network for Multimodal Machine Translation
Sep 04, 2020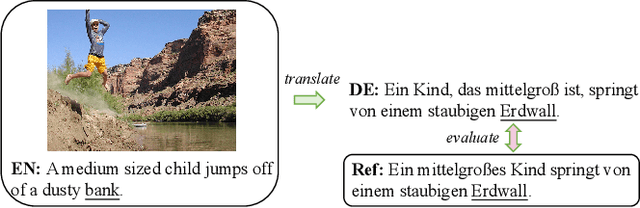
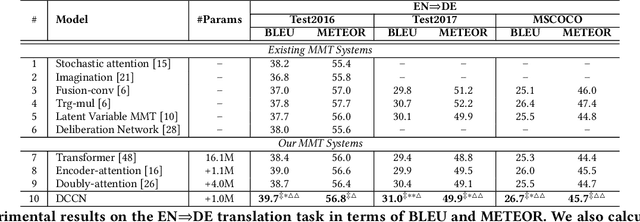
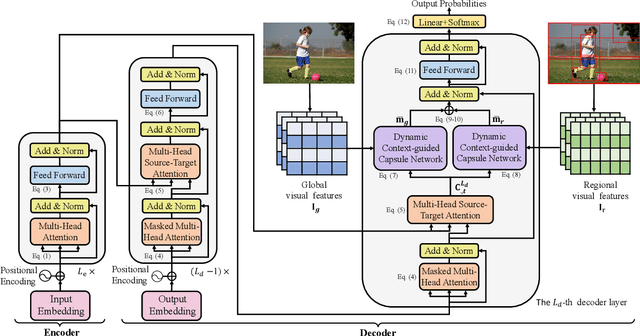
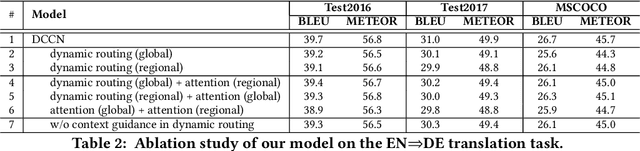
Multimodal machine translation (MMT), which mainly focuses on enhancing text-only translation with visual features, has attracted considerable attention from both computer vision and natural language processing communities. Most current MMT models resort to attention mechanism, global context modeling or multimodal joint representation learning to utilize visual features. However, the attention mechanism lacks sufficient semantic interactions between modalities while the other two provide fixed visual context, which is unsuitable for modeling the observed variability when generating translation. To address the above issues, in this paper, we propose a novel Dynamic Context-guided Capsule Network (DCCN) for MMT. Specifically, at each timestep of decoding, we first employ the conventional source-target attention to produce a timestep-specific source-side context vector. Next, DCCN takes this vector as input and uses it to guide the iterative extraction of related visual features via a context-guided dynamic routing mechanism. Particularly, we represent the input image with global and regional visual features, we introduce two parallel DCCNs to model multimodal context vectors with visual features at different granularities. Finally, we obtain two multimodal context vectors, which are fused and incorporated into the decoder for the prediction of the target word. Experimental results on the Multi30K dataset of English-to-German and English-to-French translation demonstrate the superiority of DCCN. Our code is available on https://github.com/DeepLearnXMU/MM-DCCN.
Learning to Localize Actions from Moments
Aug 31, 2020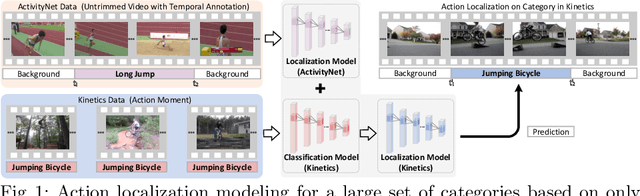
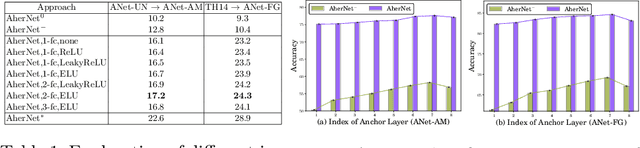
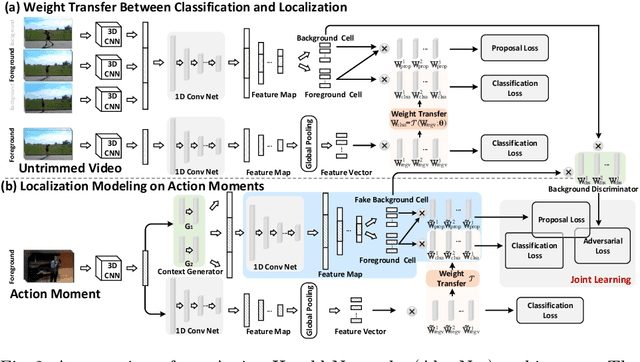
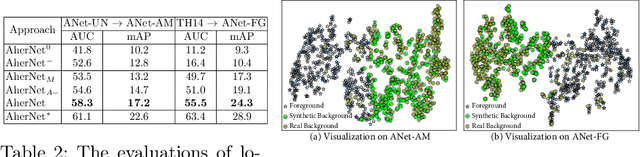
With the knowledge of action moments (i.e., trimmed video clips that each contains an action instance), humans could routinely localize an action temporally in an untrimmed video. Nevertheless, most practical methods still require all training videos to be labeled with temporal annotations (action category and temporal boundary) and develop the models in a fully-supervised manner, despite expensive labeling efforts and inapplicable to new categories. In this paper, we introduce a new design of transfer learning type to learn action localization for a large set of action categories, but only on action moments from the categories of interest and temporal annotations of untrimmed videos from a small set of action classes. Specifically, we present Action Herald Networks (AherNet) that integrate such design into an one-stage action localization framework. Technically, a weight transfer function is uniquely devised to build the transformation between classification of action moments or foreground video segments and action localization in synthetic contextual moments or untrimmed videos. The context of each moment is learnt through the adversarial mechanism to differentiate the generated features from those of background in untrimmed videos. Extensive experiments are conducted on the learning both across the splits of ActivityNet v1.3 and from THUMOS14 to ActivityNet v1.3. Our AherNet demonstrates the superiority even comparing to most fully-supervised action localization methods. More remarkably, we train AherNet to localize actions from 600 categories on the leverage of action moments in Kinetics-600 and temporal annotations from 200 classes in ActivityNet v1.3. Source code and data are available at \url{https://github.com/FuchenUSTC/AherNet}.
A Smartphone-based System for Real-time Early Childhood Caries Diagnosis
Aug 17, 2020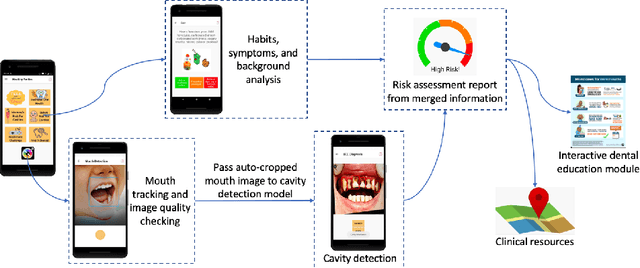


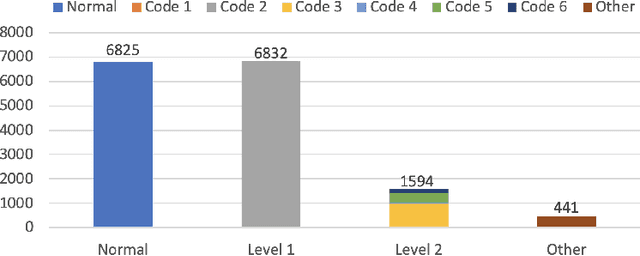
Early childhood caries (ECC) is the most common, yet preventable chronic disease in children under the age of 6. Treatments on severe ECC are extremely expensive and unaffordable for socioeconomically disadvantaged families. The identification of ECC in an early stage usually requires expertise in the field, and hence is often ignored by parents. Therefore, early prevention strategies and easy-to-adopt diagnosis techniques are desired. In this study, we propose a multistage deep learning-based system for cavity detection. We create a dataset containing RGB oral images labeled manually by dental practitioners. We then investigate the effectiveness of different deep learning models on the dataset. Furthermore, we integrate the deep learning system into an easy-to-use mobile application that can diagnose ECC from an early stage and provide real-time results to untrained users.
Improving One-stage Visual Grounding by Recursive Sub-query Construction
Aug 03, 2020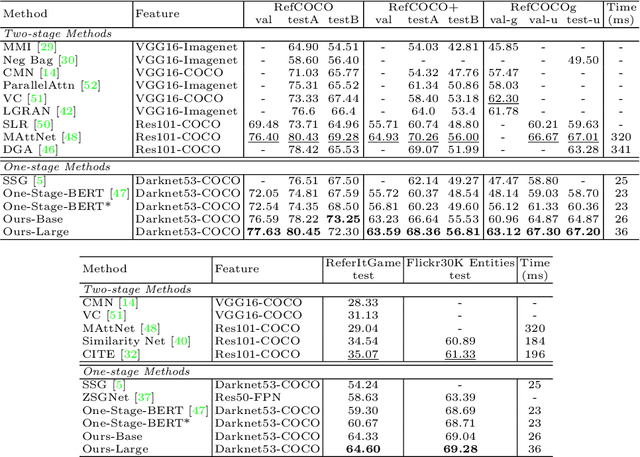

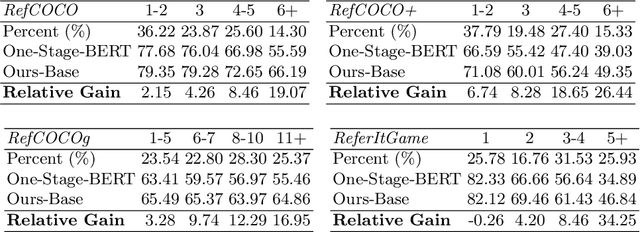
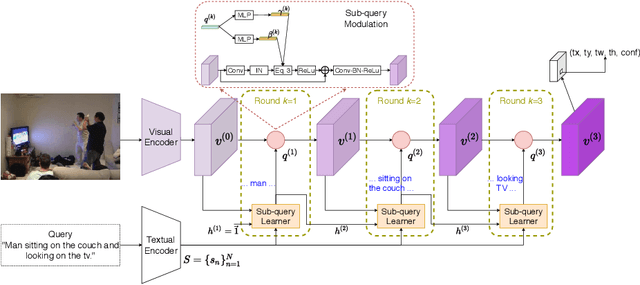
We improve one-stage visual grounding by addressing current limitations on grounding long and complex queries. Existing one-stage methods encode the entire language query as a single sentence embedding vector, e.g., taking the embedding from BERT or the hidden state from LSTM. This single vector representation is prone to overlooking the detailed descriptions in the query. To address this query modeling deficiency, we propose a recursive sub-query construction framework, which reasons between image and query for multiple rounds and reduces the referring ambiguity step by step. We show our new one-stage method obtains 5.0%, 4.5%, 7.5%, 12.8% absolute improvements over the state-of-the-art one-stage baseline on ReferItGame, RefCOCO, RefCOCO+, and RefCOCOg, respectively. In particular, superior performances on longer and more complex queries validates the effectiveness of our query modeling.
Dynamic Dual-Attentive Aggregation Learning for Visible-Infrared Person Re-Identification
Jul 18, 2020

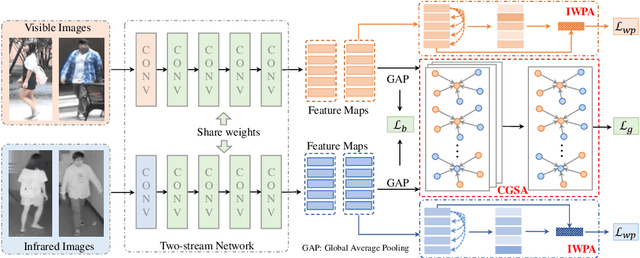

Visible-infrared person re-identification (VI-ReID) is a challenging cross-modality pedestrian retrieval problem. Due to the large intra-class variations and cross-modality discrepancy with large amount of sample noise, it is difficult to learn discriminative part features. Existing VI-ReID methods instead tend to learn global representations, which have limited discriminability and weak robustness to noisy images. In this paper, we propose a novel dynamic dual-attentive aggregation (DDAG) learning method by mining both intra-modality part-level and cross-modality graph-level contextual cues for VI-ReID. We propose an intra-modality weighted-part attention module to extract discriminative part-aggregated features, by imposing the domain knowledge on the part relationship mining. To enhance robustness against noisy samples, we introduce cross-modality graph structured attention to reinforce the representation with the contextual relations across the two modalities. We also develop a parameter-free dynamic dual aggregation learning strategy to adaptively integrate the two components in a progressive joint training manner. Extensive experiments demonstrate that DDAG outperforms the state-of-the-art methods under various settings.
A Novel Graph-based Multi-modal Fusion Encoder for Neural Machine Translation
Jul 17, 2020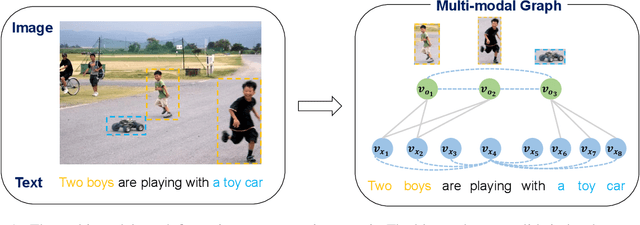
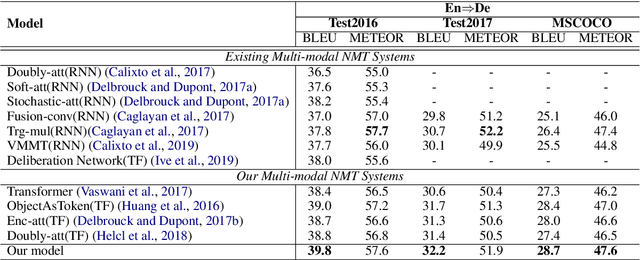
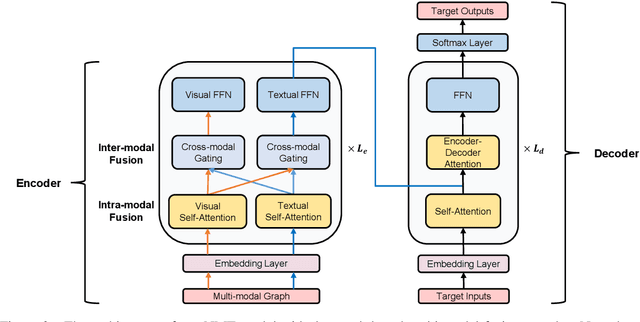
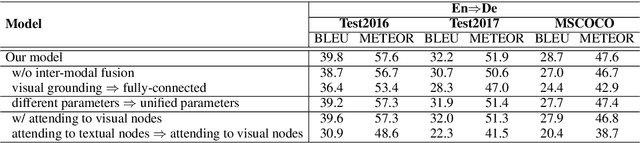
Multi-modal neural machine translation (NMT) aims to translate source sentences into a target language paired with images. However, dominant multi-modal NMT models do not fully exploit fine-grained semantic correspondences between semantic units of different modalities, which have potential to refine multi-modal representation learning. To deal with this issue, in this paper, we propose a novel graph-based multi-modal fusion encoder for NMT. Specifically, we first represent the input sentence and image using a unified multi-modal graph, which captures various semantic relationships between multi-modal semantic units (words and visual objects). We then stack multiple graph-based multi-modal fusion layers that iteratively perform semantic interactions to learn node representations. Finally, these representations provide an attention-based context vector for the decoder. We evaluate our proposed encoder on the Multi30K datasets. Experimental results and in-depth analysis show the superiority of our multi-modal NMT model.
Universal Model for Multi-Domain Medical Image Retrieval
Jul 14, 2020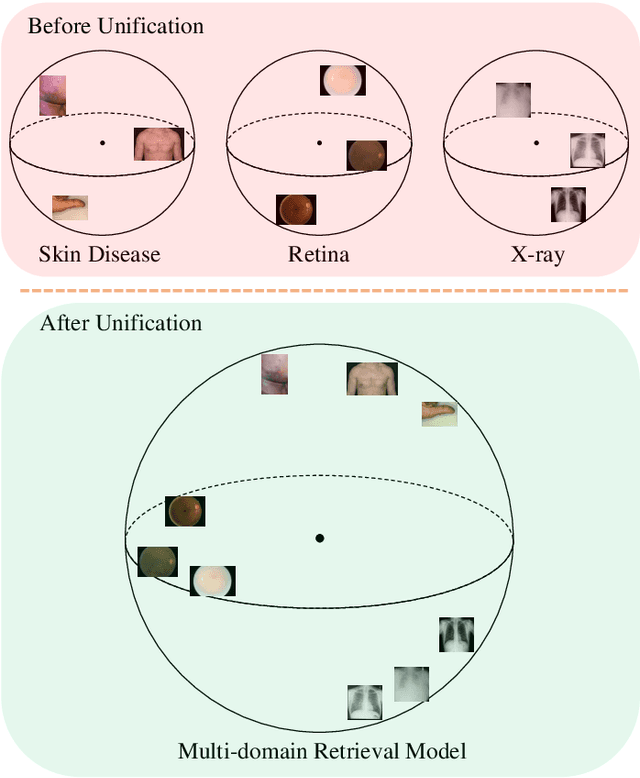
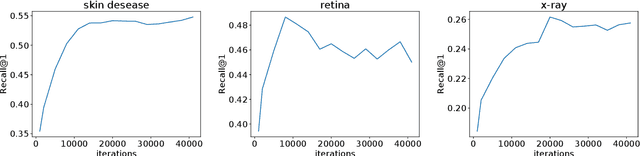
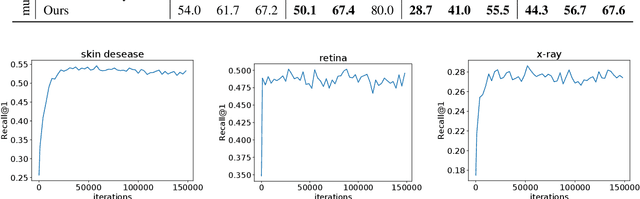
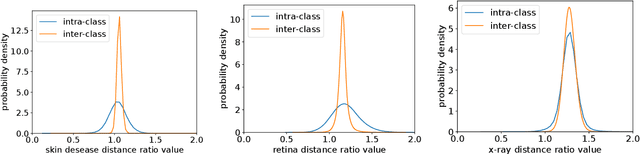
Medical Image Retrieval (MIR) helps doctors quickly find similar patients' data, which can considerably aid the diagnosis process. MIR is becoming increasingly helpful due to the wide use of digital imaging modalities and the growth of the medical image repositories. However, the popularity of various digital imaging modalities in hospitals also poses several challenges to MIR. Usually, one image retrieval model is only trained to handle images from one modality or one source. When there are needs to retrieve medical images from several sources or domains, multiple retrieval models need to be maintained, which is cost ineffective. In this paper, we study an important but unexplored task: how to train one MIR model that is applicable to medical images from multiple domains? Simply fusing the training data from multiple domains cannot solve this problem because some domains become over-fit sooner when trained together using existing methods. Therefore, we propose to distill the knowledge in multiple specialist MIR models into a single multi-domain MIR model via universal embedding to solve this problem. Using skin disease, x-ray, and retina image datasets, we validate that our proposed universal model can effectively accomplish multi-domain MIR.
Task-agnostic Temporally Consistent Facial Video Editing
Jul 03, 2020
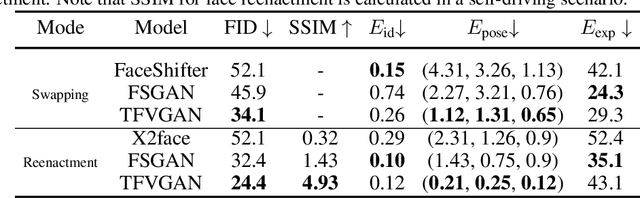
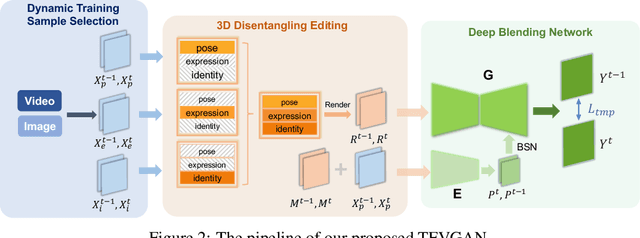
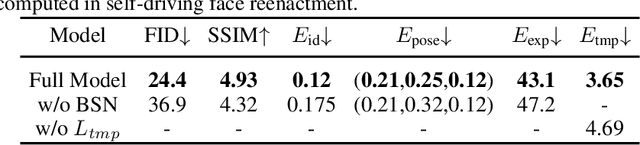
Recent research has witnessed the advances in facial image editing tasks. For video editing, however, previous methods either simply apply transformations frame by frame or utilize multiple frames in a concatenated or iterative fashion, which leads to noticeable visual flickers. In addition, these methods are confined to dealing with one specific task at a time without any extensibility. In this paper, we propose a task-agnostic temporally consistent facial video editing framework. Based on a 3D reconstruction model, our framework is designed to handle several editing tasks in a more unified and disentangled manner. The core design includes a dynamic training sample selection mechanism and a novel 3D temporal loss constraint that fully exploits both image and video datasets and enforces temporal consistency. Compared with the state-of-the-art facial image editing methods, our framework generates video portraits that are more photo-realistic and temporally smooth.
Real-time Universal Style Transfer on High-resolution Images via Zero-channel Pruning
Jun 23, 2020
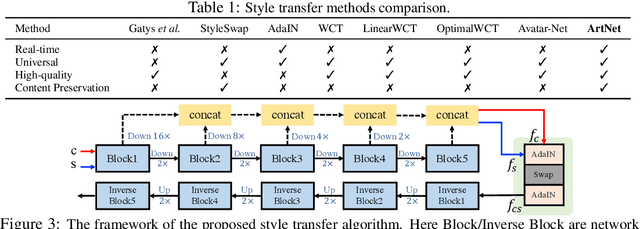


Extracting effective deep features to represent content and style information is the key to universal style transfer. Most existing algorithms use VGG19 as the feature extractor, which incurs a high computational cost and impedes real-time style transfer on high-resolution images. In this work, we propose a lightweight alternative architecture - ArtNet, which is based on GoogLeNet, and later pruned by a novel channel pruning method named Zero-channel Pruning specially designed for style transfer approaches. Besides, we propose a theoretically sound sandwich swap transform (S2) module to transfer deep features, which can create a pleasing holistic appearance and good local textures with an improved content preservation ability. By using ArtNet and S2, our method is 2.3 to 107.4 times faster than state-of-the-art approaches. The comprehensive experiments demonstrate that ArtNet can achieve universal, real-time, and high-quality style transfer on high-resolution images simultaneously, (68.03 FPS on 512 times 512 images).