 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFedCoE: Bridging Generalization and Personalization via Federated Coordinated Dual-level MoEs
May 20, 2026Federated Learning (FL) has emerged as a promising paradigm for privacy-preserving distributed learning. However, existing FL methods face a fundamental challenge. Traditional averaging-based approaches suffer from parameter divergence under non-IID conditions, while personalized FL methods overfit to local data and fail to generalize to new clients (cold-start problem). Mixture-of-Experts naturally addresses this by routing heterogeneous data to specialized experts rather than forcing uniform aggregation. In this paper, we propose FedCoE, a Federated Coordinated dual-level mixture-of-Experts framework that effectively balances global generalization with local personalization. FedCoE maintains multiple independent global expert models on the server and employs a shared gating network to dynamically model client-expert correlations during aggregation, effectively mitigating expert drift and gating inconsistency. To address the cold-start challenge, we introduce an adaptive mechanism that enables new clients to immediately leverage the global expert pool without extensive local training. Extensive experiments demonstrate that FedCoE achieves 78.00% global accuracy and 89.32% personalized accuracy on average, outperforming the baseline by 8.82% and 29.19%, respectively. In cold-start scenarios, FedCoE delivers 77.27% accuracy without any local fine-tuning, outperforming baselines by over 12.54%.
AutoMCU: Feasibility-First MCU Neural Network Customization via LLM-based Multi-Agent Systems
May 20, 2026Deploying neural networks on microcontroller units (MCUs) is critical for edge intelligence but remains challenging due to tight memory, storage, and computation constraints. Existing approaches, such as model compression and hardware-aware neural architecture search (HW-NAS), often depend on proxy metrics, incur high search cost, and do not fully bridge the gap between architecture design and verified deployment. This paper presents AutoMCU, a feasibility-first large language model (LLM)-based multi-agent system for automated neural network customization under MCU constraints. Given natural-language task requirements and hardware specifications, AutoMCU iteratively generates structured architecture candidates, filters infeasible designs through vendor toolchain feedback before training, evaluates feasible models under a controlled protocol, and verifies deployability through backend-grounded deployment analysis. AutoMCU includes two key mechanisms: 1) hardware-in-the-loop architecture generation for early elimination of undeployable candidates under RAM and Flash constraints, and 2) state-isolated multi-agent scheduling for stable coordination of proposal, training, evaluation, and deployment stages. Experiments on CIFAR-10 and CIFAR-100 under strict MCU constraints show that AutoMCU achieves competitive accuracy while reducing customization time to about 1--2 hours, compared with hundreds of GPU hours for representative MCU-oriented HW-NAS baselines. Comparisons with ColabNAS and the LLM-based NAS method GENIUS on NAS-Bench-201 further demonstrate the effectiveness and stability of AutoMCU. Real-device deployments on multiple STM32 microcontrollers validate its practical applicability to MCU-scale edge intelligence.
MixRea: Benchmarking Explicit-Implicit Reasoning in Large Language Models
May 19, 2026Large language models (LLMs) are increasingly integrated into high-stakes decision-making. Inspired by the theory of \emph{inattentional blindness} in human cognition, we investigate whether LLMs, trained on human-preferred corpora that embed attentional biases, exhibit a similar limitation: \emph{failing to attend to subtle yet important contextual cues under explicit task instructions}. To evaluate this, we introduce the task of \textbf{explicit-implicit reasoning} and present \textbf{MixRea}, a benchmark of 2,246 multiple-choice questions across 9 reasoning types with varying distributions of explicit and implicit information. Evaluation of 21 advanced LLMs shows that even the best-performing reasoning model (Gemini 2.5 Pro) achieves only 42.8\% consistency, revealing widespread inattentional blindness. To mitigate this, we propose \textbf{Potential Relation Completion Prompting (PRCP)}, a prompting method that improves reasoning by recovering overlooked causal relations. Further analysis shows that this limitation persists across diverse multi-source reasoning tasks, highlighting the need for more cognitively aligned models.
GeoQuery: Geometry-Query Diffusion for Sparse-View Reconstruction
May 12, 20263D Gaussian Splatting (3DGS) has emerged as a prominent paradigm for 3D reconstruction and novel view synthesis. However, it remains vulnerable to severe artifacts when trained under sparse-view constraints. While recent methods attempt to rectify artifacts in rendered views using image diffusion models, they typically rely on multi-view self-attention to retrieve information from reference images. We observe that this mechanism often fails when the rendered novel views output by 3DGS are heavily corrupted: damaged query features lead to erroneous cross-view retrieval, resulting in inconsistent rendering refinement. To address this, we propose GeoQuery, a geometry-guided diffusion framework that integrates generative priors with explicit geometric cues via a novel Geometry-guided Cross-view Attention (GCA) mechanism. First, by leveraging predicted depth maps and camera poses, we construct a geometry-induced correspondence field to sample reference features, forming a geometry-aligned proxy query that replaces the corrupted rendering features. Furthermore, we design a new cross-view feature aggregation pipeline, in which we restrict the cross-view attention to a local window around each proxy query to effectively retrieve useful features while suppressing spurious matches. GeoQuery can be seamlessly integrated into existing diffusion-based pipelines, enabling robust reconstruction even under extreme view sparsity. Extensive experiments on sparse-view novel view synthesis and rendering artifact removal demonstrate the effectiveness of our approach.
PokeGym: A Visually-Driven Long-Horizon Benchmark for Vision-Language Models
Apr 09, 2026While Vision-Language Models (VLMs) have achieved remarkable progress in static visual understanding, their deployment in complex 3D embodied environments remains severely limited. Existing benchmarks suffer from four critical deficiencies: (1) passive perception tasks circumvent interactive dynamics; (2) simplified 2D environments fail to assess depth perception; (3) privileged state leakage bypasses genuine visual processing; and (4) human evaluation is prohibitively expensive and unscalable. We introduce PokeGym, a visually-driven long-horizon benchmark instantiated within Pokemon Legends: Z-A, a visually complex 3D open-world Role-Playing Game. PokeGym enforces strict code-level isolation: agents operate solely on raw RGB observations while an independent evaluator verifies success via memory scanning, ensuring pure vision-based decision-making and automated, scalable assessment. The benchmark comprises 30 tasks (30-220 steps) spanning navigation, interaction, and mixed scenarios, with three instruction granularities (Visual-Guided, Step-Guided, Goal-Only) to systematically deconstruct visual grounding, semantic reasoning, and autonomous exploration capabilities. Our evaluation reveals a key limitation of current VLMs: physical deadlock recovery, rather than high-level planning, constitutes the primary bottleneck, with deadlocks showing a strong negative correlation with task success. Furthermore, we uncover a metacognitive divergence: weaker models predominantly suffer from Unaware Deadlocks (oblivious to entrapment), whereas advanced models exhibit Aware Deadlocks (recognizing entrapment yet failing to recover). These findings highlight the need to integrate explicit spatial intuition into VLM architectures. The code and benchmark will be available on GitHub.
Instance-Free Domain Adaptive Object Detection
Feb 06, 2026While Domain Adaptive Object Detection (DAOD) has made significant strides, most methods rely on unlabeled target data that is assumed to contain sufficient foreground instances. However, in many practical scenarios (e.g., wildlife monitoring, lesion detection), collecting target domain data with objects of interest is prohibitively costly, whereas background-only data is abundant. This common practical constraint introduces a significant technical challenge: the difficulty of achieving domain alignment when target instances are unavailable, forcing adaptation to rely solely on the target background information. We formulate this challenge as the novel problem of Instance-Free Domain Adaptive Object Detection. To tackle this, we propose the Relational and Structural Consistency Network (RSCN) which pioneers an alignment strategy based on background feature prototypes while simultaneously encouraging consistency in the relationship between the source foreground features and the background features within each domain, enabling robust adaptation even without target instances. To facilitate research, we further curate three specialized benchmarks, including simulative auto-driving detection, wildlife detection, and lung nodule detection. Extensive experiments show that RSCN significantly outperforms existing DAOD methods across all three benchmarks in the instance-free scenario. The code and benchmarks will be released soon.
Collaborative Group-Aware Hashing for Fast Recommender Systems
Dec 23, 2025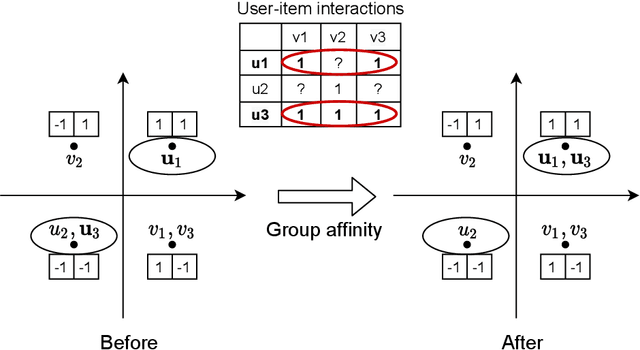

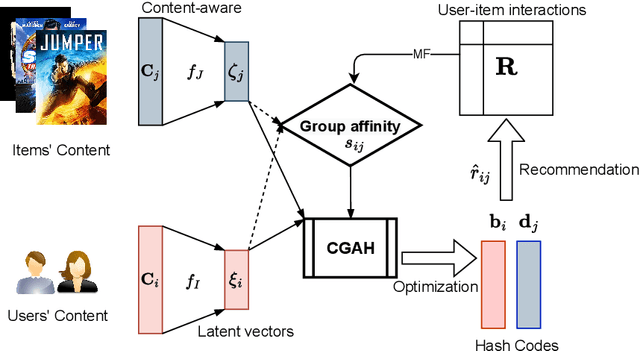
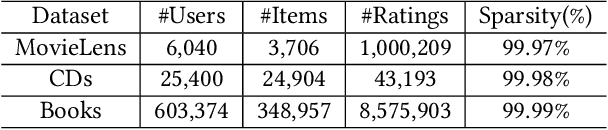
The fast online recommendation is critical for applications with large-scale databases; meanwhile, it is challenging to provide accurate recommendations in sparse scenarios. Hash technique has shown its superiority for speeding up the online recommendation by bit operations on Hamming distance computations. However, existing hashing-based recommendations suffer from low accuracy, especially with sparse settings, due to the limited representation capability of each bit and neglected inherent relations among users and items. To this end, this paper lodges a Collaborative Group-Aware Hashing (CGAH) method for both collaborative filtering (namely CGAH-CF) and content-aware recommendations (namely CGAH) by integrating the inherent group information to alleviate the sparse issue. Firstly, we extract inherent group affinities of users and items by classifying their latent vectors into different groups. Then, the preference is formulated as the inner product of the group affinity and the similarity of hash codes. By learning hash codes with the inherent group information, CGAH obtains more effective hash codes than other discrete methods with sparse interactive data. Extensive experiments on three public datasets show the superior performance of our proposed CGAH and CGAH-CF over the state-of-the-art discrete collaborative filtering methods and discrete content-aware recommendations under different sparse settings.
The Devil is in Attention Sharing: Improving Complex Non-rigid Image Editing Faithfulness via Attention Synergy
Dec 17, 2025Training-free image editing with large diffusion models has become practical, yet faithfully performing complex non-rigid edits (e.g., pose or shape changes) remains highly challenging. We identify a key underlying cause: attention collapse in existing attention sharing mechanisms, where either positional embeddings or semantic features dominate visual content retrieval, leading to over-editing or under-editing. To address this issue, we introduce SynPS, a method that Synergistically leverages Positional embeddings and Semantic information for faithful non-rigid image editing. We first propose an editing measurement that quantifies the required editing magnitude at each denoising step. Based on this measurement, we design an attention synergy pipeline that dynamically modulates the influence of positional embeddings, enabling SynPS to balance semantic modifications and fidelity preservation. By adaptively integrating positional and semantic cues, SynPS effectively avoids both over- and under-editing. Extensive experiments on public and newly curated benchmarks demonstrate the superior performance and faithfulness of our approach.
Balanced Sharpness-Aware Minimization for Imbalanced Regression
Aug 23, 2025Regression is fundamental in computer vision and is widely used in various tasks including age estimation, depth estimation, target localization, \etc However, real-world data often exhibits imbalanced distribution, making regression models perform poorly especially for target values with rare observations~(known as the imbalanced regression problem). In this paper, we reframe imbalanced regression as an imbalanced generalization problem. To tackle that, we look into the loss sharpness property for measuring the generalization ability of regression models in the observation space. Namely, given a certain perturbation on the model parameters, we check how model performance changes according to the loss values of different target observations. We propose a simple yet effective approach called Balanced Sharpness-Aware Minimization~(BSAM) to enforce the uniform generalization ability of regression models for the entire observation space. In particular, we start from the traditional sharpness-aware minimization and then introduce a novel targeted reweighting strategy to homogenize the generalization ability across the observation space, which guarantees a theoretical generalization bound. Extensive experiments on multiple vision regression tasks, including age and depth estimation, demonstrate that our BSAM method consistently outperforms existing approaches. The code is available \href{https://github.com/manmanjun/BSAM_for_Imbalanced_Regression}{here}.
Discrete Scale-invariant Metric Learning for Efficient Collaborative Filtering
Jun 11, 2025Metric learning has attracted extensive interest for its ability to provide personalized recommendations based on the importance of observed user-item interactions. Current metric learning methods aim to push negative items away from the corresponding users and positive items by an absolute geometrical distance margin. However, items may come from imbalanced categories with different intra-class variations. Thus, the absolute distance margin may not be ideal for estimating the difference between user preferences over imbalanced items. To this end, we propose a new method, named discrete scale-invariant metric learning (DSIML), by adding binary constraints to users and items, which maps users and items into binary codes of a shared Hamming subspace to speed up the online recommendation. Specifically, we firstly propose a scale-invariant margin based on angles at the negative item points in the shared Hamming subspace. Then, we derive a scale-invariant triple hinge loss based on the margin. To capture more preference difference information, we integrate a pairwise ranking loss into the scale-invariant loss in the proposed model. Due to the difficulty of directly optimizing the mixed integer optimization problem formulated with \textit{log-sum-exp} functions, we seek to optimize its variational quadratic upper bound and learn hash codes with an alternating optimization strategy. Experiments on benchmark datasets clearly show that our proposed method is superior to competitive metric learning and hashing-based baselines for recommender systems. The implementation code is available at https://github.com/AnonyFeb/dsml.