 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpaceEdit: Learning a Unified Editing Space for Open-Domain Image Editing
Nov 30, 2021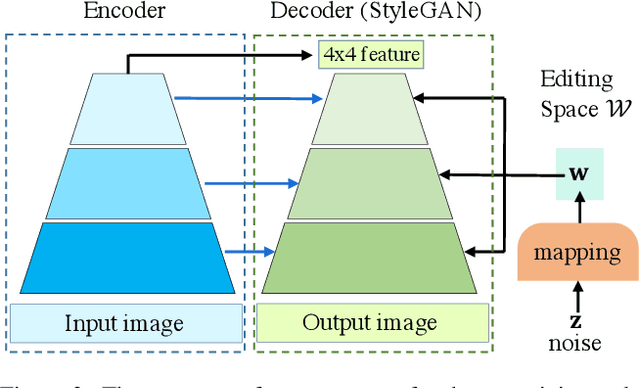
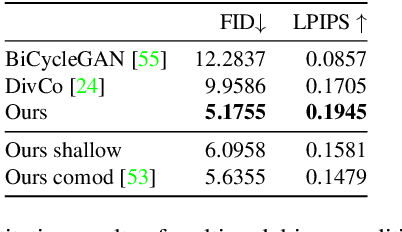


Recently, large pretrained models (e.g., BERT, StyleGAN, CLIP) have shown great knowledge transfer and generalization capability on various downstream tasks within their domains. Inspired by these efforts, in this paper we propose a unified model for open-domain image editing focusing on color and tone adjustment of open-domain images while keeping their original content and structure. Our model learns a unified editing space that is more semantic, intuitive, and easy to manipulate than the operation space (e.g., contrast, brightness, color curve) used in many existing photo editing softwares. Our model belongs to the image-to-image translation framework which consists of an image encoder and decoder, and is trained on pairs of before- and after-images to produce multimodal outputs. We show that by inverting image pairs into latent codes of the learned editing space, our model can be leveraged for various downstream editing tasks such as language-guided image editing, personalized editing, editing-style clustering, retrieval, etc. We extensively study the unique properties of the editing space in experiments and demonstrate superior performance on the aforementioned tasks.
Music Sentiment Transfer
Oct 12, 2021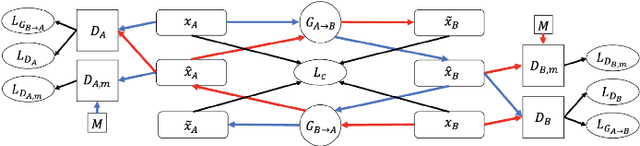
Music sentiment transfer is a completely novel task. Sentiment transfer is a natural evolution of the heavily-studied style transfer task, as sentiment transfer is rooted in applying the sentiment of a source to be the new sentiment for a target piece of media; yet compared to style transfer, sentiment transfer has been only scantily studied on images. Music sentiment transfer attempts to apply the high level objective of sentiment transfer to the domain of music. We propose CycleGAN to bridge disparate domains. In order to use the network, we choose to use symbolic, MIDI, data as the music format. Through the use of a cycle consistency loss, we are able to create one-to-one mappings that preserve the content and realism of the source data. Results and literature suggest that the task of music sentiment transfer is more difficult than image sentiment transfer because of the temporal characteristics of music and lack of existing datasets.
Procedure Planning in Instructional Videos via Contextual Modeling and Model-based Policy Learning
Oct 08, 2021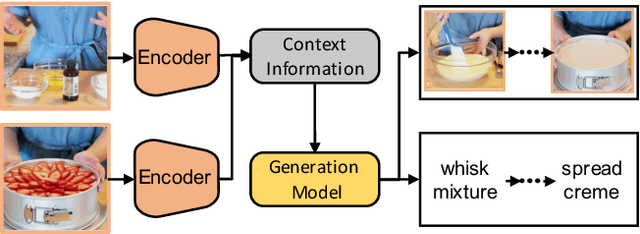
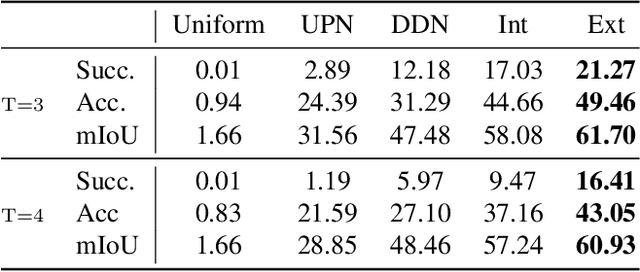
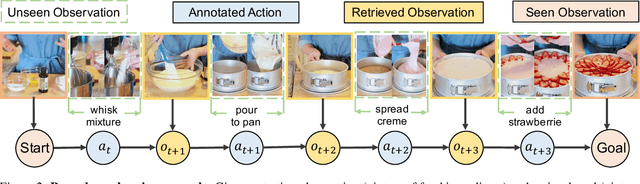
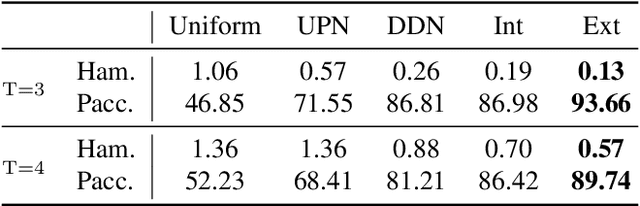
Learning new skills by observing humans' behaviors is an essential capability of AI. In this work, we leverage instructional videos to study humans' decision-making processes, focusing on learning a model to plan goal-directed actions in real-life videos. In contrast to conventional action recognition, goal-directed actions are based on expectations of their outcomes requiring causal knowledge of potential consequences of actions. Thus, integrating the environment structure with goals is critical for solving this task. Previous works learn a single world model will fail to distinguish various tasks, resulting in an ambiguous latent space; planning through it will gradually neglect the desired outcomes since the global information of the future goal degrades quickly as the procedure evolves. We address these limitations with a new formulation of procedure planning and propose novel algorithms to model human behaviors through Bayesian Inference and model-based Imitation Learning. Experiments conducted on real-world instructional videos show that our method can achieve state-of-the-art performance in reaching the indicated goals. Furthermore, the learned contextual information presents interesting features for planning in a latent space.
CoSeg: Cognitively Inspired Unsupervised Generic Event Segmentation
Sep 30, 2021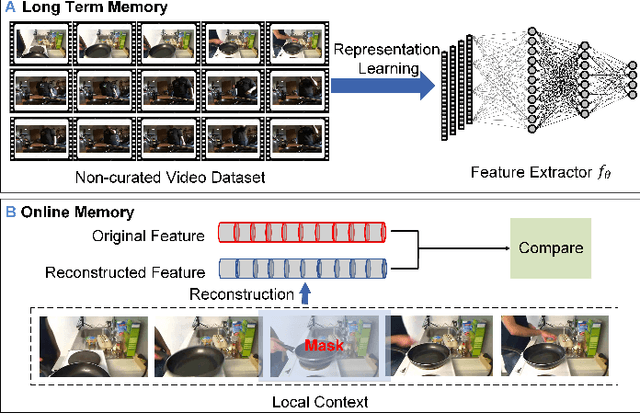
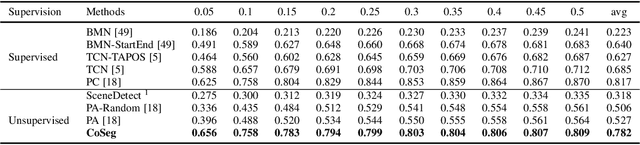
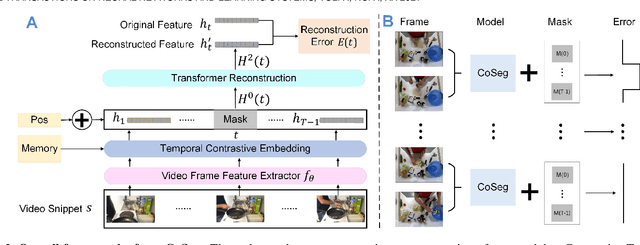
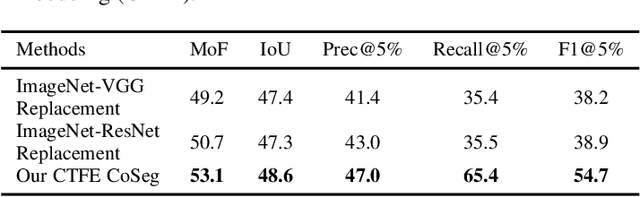
Some cognitive research has discovered that humans accomplish event segmentation as a side effect of event anticipation. Inspired by this discovery, we propose a simple yet effective end-to-end self-supervised learning framework for event segmentation/boundary detection. Unlike the mainstream clustering-based methods, our framework exploits a transformer-based feature reconstruction scheme to detect event boundary by reconstruction errors. This is consistent with the fact that humans spot new events by leveraging the deviation between their prediction and what is actually perceived. Thanks to their heterogeneity in semantics, the frames at boundaries are difficult to be reconstructed (generally with large reconstruction errors), which is favorable for event boundary detection. Additionally, since the reconstruction occurs on the semantic feature level instead of pixel level, we develop a temporal contrastive feature embedding module to learn the semantic visual representation for frame feature reconstruction. This procedure is like humans building up experiences with "long-term memory". The goal of our work is to segment generic events rather than localize some specific ones. We focus on achieving accurate event boundaries. As a result, we adopt F1 score (Precision/Recall) as our primary evaluation metric for a fair comparison with previous approaches. Meanwhile, we also calculate the conventional frame-based MoF and IoU metric. We thoroughly benchmark our work on four publicly available datasets and demonstrate much better results.
Learning to Aggregate and Refine Noisy Labels for Visual Sentiment Analysis
Sep 15, 2021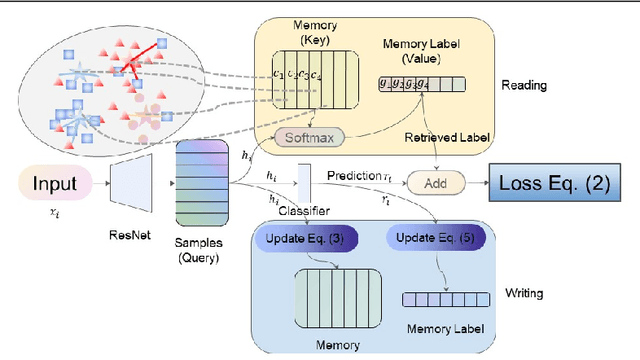
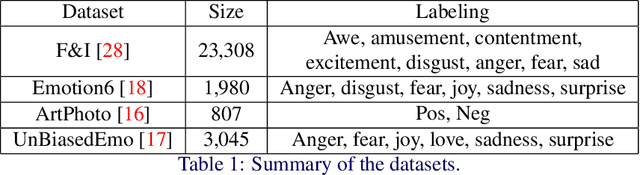

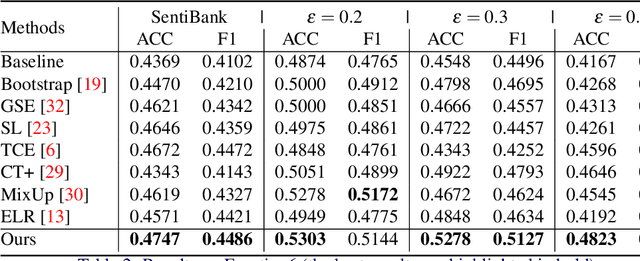
Visual sentiment analysis has received increasing attention in recent years. However, the quality of the dataset is a concern because the sentiment labels are crowd-sourcing, subjective, and prone to mistakes. This poses a severe threat to the data-driven models including the deep neural networks which would generalize poorly on the testing cases if they are trained to over-fit the samples with noisy sentiment labels. Inspired by the recent progress on learning with noisy labels, we propose a robust learning method to perform robust visual sentiment analysis. Our method relies on an external memory to aggregate and filter noisy labels during training and thus can prevent the model from overfitting the noisy cases. The memory is composed of the prototypes with corresponding labels, both of which can be updated online. We establish a benchmark for visual sentiment analysis with label noise using publicly available datasets. The experiment results of the proposed benchmark settings comprehensively show the effectiveness of our method.
Federated Learning of Molecular Properties in a Heterogeneous Setting
Sep 15, 2021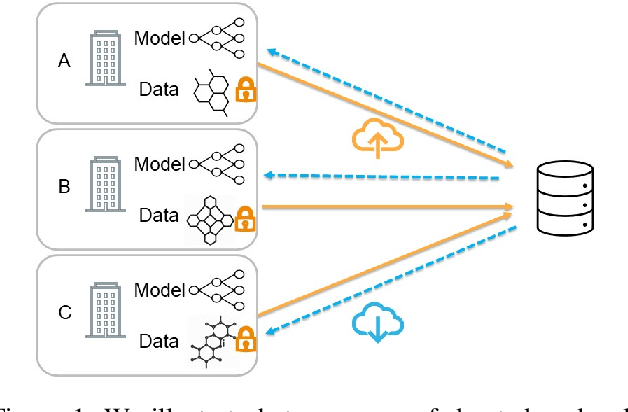
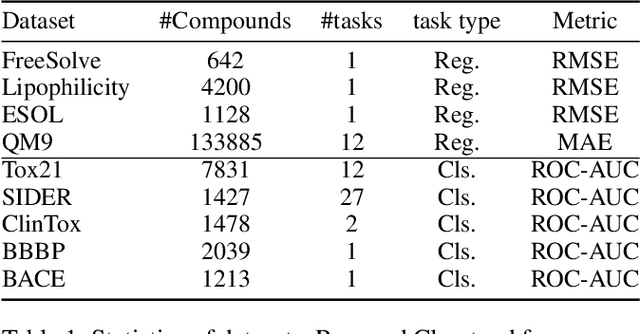
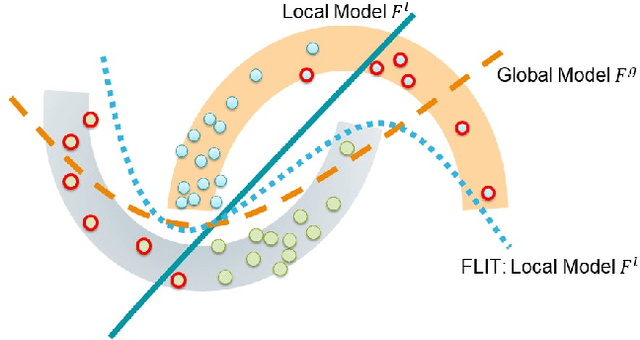
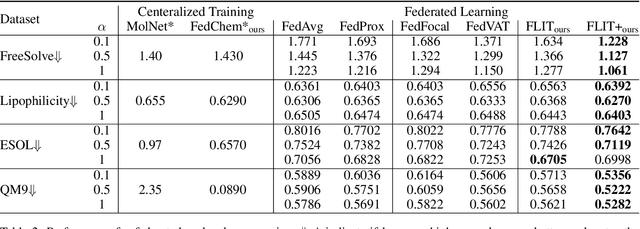
Chemistry research has both high material and computational costs to conduct experiments. Institutions thus consider chemical data to be valuable and there have been few efforts to construct large public datasets for machine learning. Another challenge is that different intuitions are interested in different classes of molecules, creating heterogeneous data that cannot be easily joined by conventional distributed training. In this work, we introduce federated heterogeneous molecular learning to address these challenges. Federated learning allows end-users to build a global model collaboratively while preserving the training data distributed over isolated clients. Due to the lack of related research, we first simulate a federated heterogeneous benchmark called FedChem. FedChem is constructed by jointly performing scaffold splitting and Latent Dirichlet Allocation on existing datasets. Our results on FedChem show that significant learning challenges arise when working with heterogeneous molecules. We then propose a method to alleviate the problem, namely Federated Learning by Instance reweighTing (FLIT). FLIT can align the local training across heterogeneous clients by improving the performance for uncertain samples. Comprehensive experiments conducted on our new benchmark FedChem validate the advantages of this method over other federated learning schemes. FedChem should enable a new type of collaboration for improving AI in chemistry that mitigates concerns about valuable chemical data.
Stock Price Prediction Under Anomalous Circumstances
Sep 14, 2021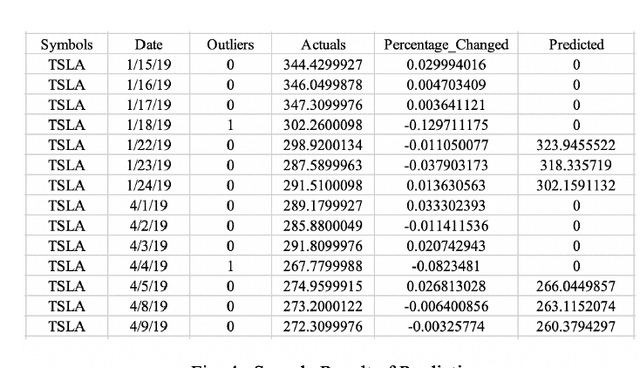
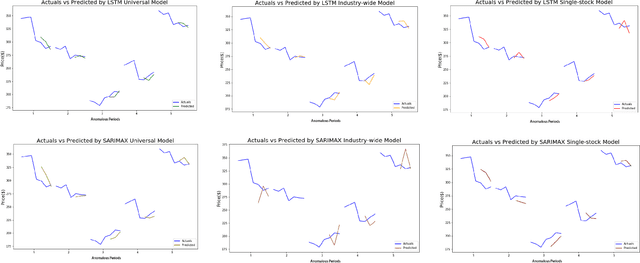
The stock market is volatile and complicated, especially in 2020. Because of a series of global and regional "black swans," such as the COVID-19 pandemic, the U.S. stock market triggered the circuit breaker three times within one week of March 9 to 16, which is unprecedented throughout history. Affected by the whole circumstance, the stock prices of individual corporations also plummeted by rates that were never predicted by any pre-developed forecasting models. It reveals that there was a lack of satisfactory models that could predict the changes in stocks prices when catastrophic, highly unlikely events occur. To fill the void of such models and to help prevent investors from heavy losses during uncertain times, this paper aims to capture the movement pattern of stock prices under anomalous circumstances. First, we detect outliers in sequential stock prices by fitting a standard ARIMA model and identifying the points where predictions deviate significantly from actual values. With the selected data points, we train ARIMA and LSTM models at the single-stock level, industry level, and general market level, respectively. Since the public moods affect the stock market tremendously, a sentiment analysis is also incorporated into the models in the form of sentiment scores, which are converted from comments about specific stocks on Reddit. Based on 100 companies' stock prices in the period of 2016 to 2020, the models achieve an average prediction accuracy of 98% which can be used to optimize existing prediction methodologies.
* 8 pages, 5 figures, 3 tables. 2020 IEEE International Conference on Big Data (Big Data)
Learning Fine-Grained Motion Embedding for Landscape Animation
Sep 13, 2021

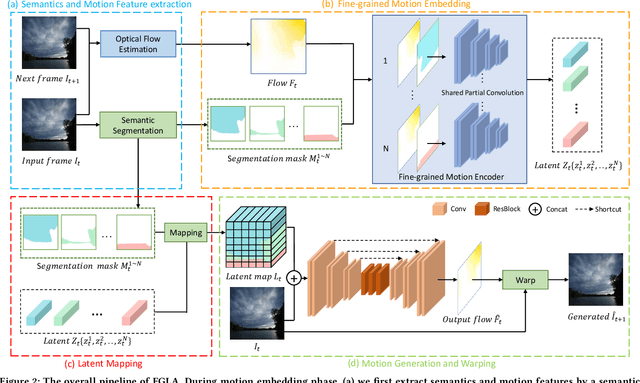
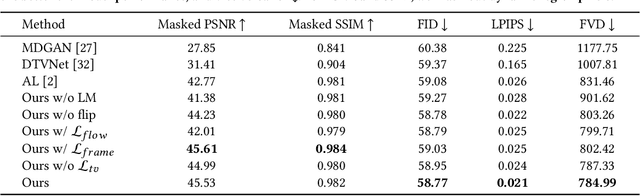
In this paper we focus on landscape animation, which aims to generate time-lapse videos from a single landscape image. Motion is crucial for landscape animation as it determines how objects move in videos. Existing methods are able to generate appealing videos by learning motion from real time-lapse videos. However, current methods suffer from inaccurate motion generation, which leads to unrealistic video results. To tackle this problem, we propose a model named FGLA to generate high-quality and realistic videos by learning Fine-Grained motion embedding for Landscape Animation. Our model consists of two parts: (1) a motion encoder which embeds time-lapse motion in a fine-grained way. (2) a motion generator which generates realistic motion to animate input images. To train and evaluate on diverse time-lapse videos, we build the largest high-resolution Time-lapse video dataset with Diverse scenes, namely Time-lapse-D, which includes 16,874 video clips with over 10 million frames. Quantitative and qualitative experimental results demonstrate the superiority of our method. In particular, our method achieves relative improvements by 19% on LIPIS and 5.6% on FVD compared with state-of-the-art methods on our dataset. A user study carried out with 700 human subjects shows that our approach visually outperforms existing methods by a large margin.
LibFewShot: A Comprehensive Library for Few-shot Learning
Sep 10, 2021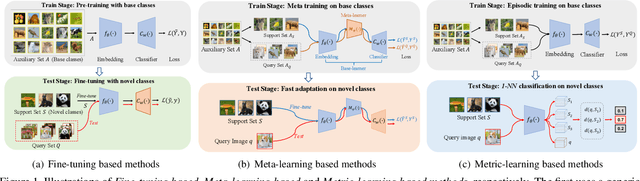
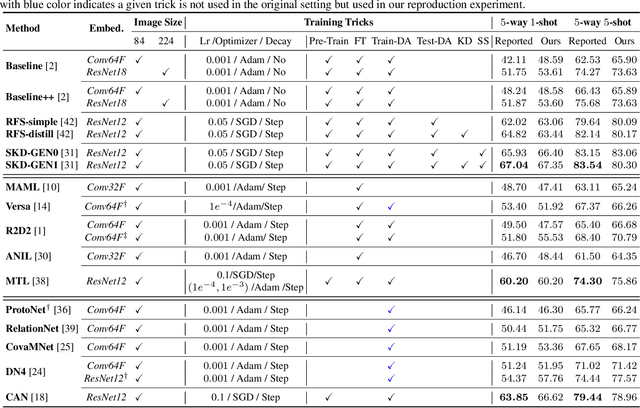
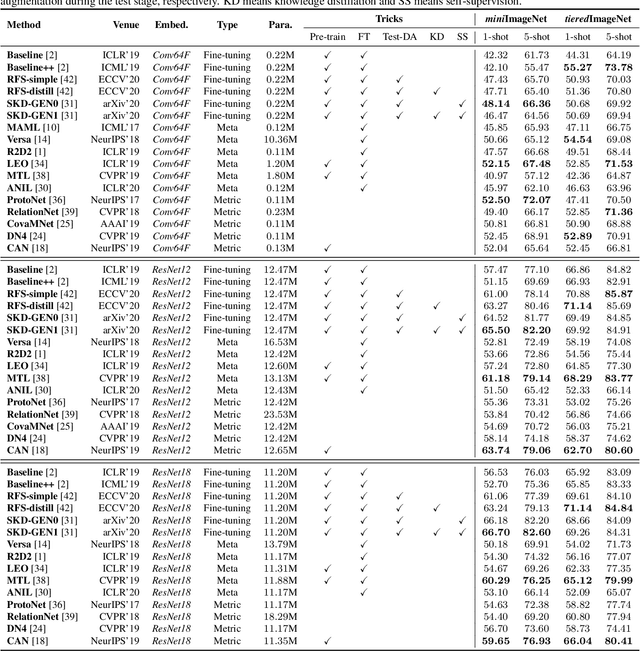
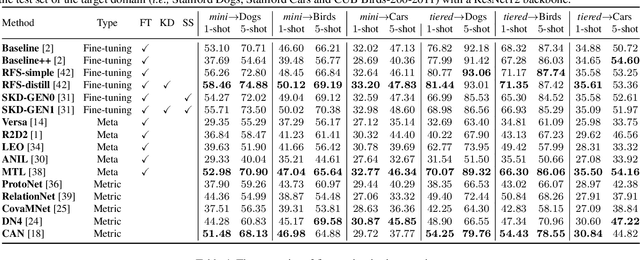
Few-shot learning, especially few-shot image classification, has received increasing attention and witnessed significant advances in recent years. Some recent studies implicitly show that many generic techniques or ``tricks'', such as data augmentation, pre-training, knowledge distillation, and self-supervision, may greatly boost the performance of a few-shot learning method. Moreover, different works may employ different software platforms, different training schedules, different backbone architectures and even different input image sizes, making fair comparisons difficult and practitioners struggle with reproducibility. To address these situations, we propose a comprehensive library for few-shot learning (LibFewShot) by re-implementing seventeen state-of-the-art few-shot learning methods in a unified framework with the same single codebase in PyTorch. Furthermore, based on LibFewShot, we provide comprehensive evaluations on multiple benchmark datasets with multiple backbone architectures to evaluate common pitfalls and effects of different training tricks. In addition, given the recent doubts on the necessity of meta- or episodic-training mechanism, our evaluation results show that such kind of mechanism is still necessary especially when combined with pre-training. We hope our work can not only lower the barriers for beginners to work on few-shot learning but also remove the effects of the nontrivial tricks to facilitate intrinsic research on few-shot learning. The source code is available from https://github.com/RL-VIG/LibFewShot.
LUAI Challenge 2021 on Learning to Understand Aerial Images
Aug 30, 2021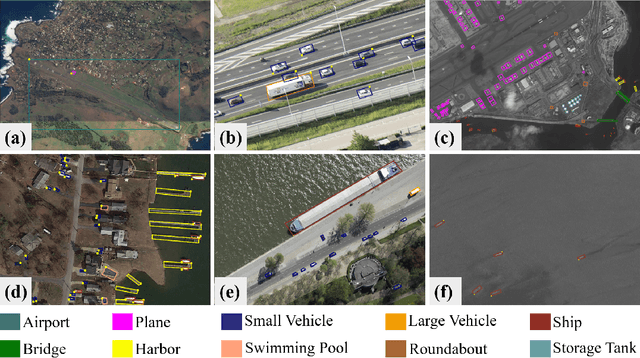

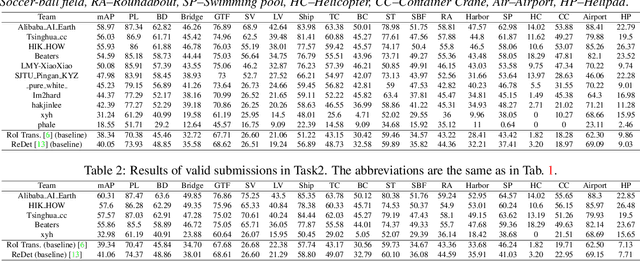
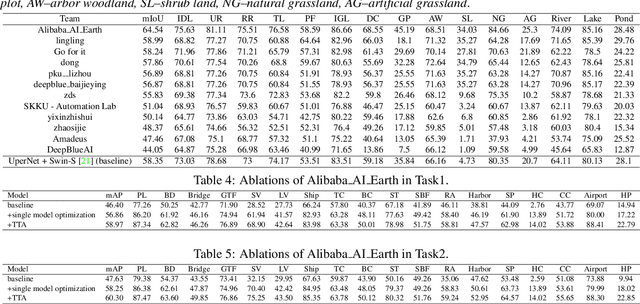
This report summarizes the results of Learning to Understand Aerial Images (LUAI) 2021 challenge held on ICCV 2021, which focuses on object detection and semantic segmentation in aerial images. Using DOTA-v2.0 and GID-15 datasets, this challenge proposes three tasks for oriented object detection, horizontal object detection, and semantic segmentation of common categories in aerial images. This challenge received a total of 146 registrations on the three tasks. Through the challenge, we hope to draw attention from a wide range of communities and call for more efforts on the problems of learning to understand aerial images.