 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSurgAtlas: A Large-Scale Surgical Video-Language Dataset with 2,391 Hours of Open and Minimally Invasive Surgery
Jun 24, 2026We introduce SurgAtlas, the largest surgical video-language dataset to date, comprising 15,291 videos (2,391 hours) spanning 18 surgical specialties and over 5,000 procedure types, sourced entirely from publicly available YouTube content. SurgAtlas is also the first surgical video-language dataset to include open surgery at scale, with 6,182 open procedure videos alongside over 9,000 minimally invasive recordings, and the first to establish standardized benchmarks for open-surgery video understanding. We additionally provide an expert-validated subset with verified visual question-answer pairs across diverse open and minimally invasive procedures, serving as a clinically grounded benchmark for surgical reasoning. Compared with existing surgical video-language datasets, SurgAtlas provides one of the most diverse annotation schemas, combining segment-level captions, step- and phase-level descriptions, video-level surgical descriptions, and reasoning-oriented question-answer pairs organized within a hierarchical taxonomy. These annotations are constructed through an automated multi-tier pipeline with LLM-based enrichment and a staged VQA generation framework with explicit groundedness verification. The scale and diversity of SurgAtlas enable training surgical foundation models with broad procedural coverage: we finetune Qwen3-VL-8B through a two-stage captioning-then-instruction pipeline and achieve competitive or state-of-the-art results on multiple established surgical benchmarks, including phase recognition, triplet detection, and reasoning question answering. More broadly, SurgAtlas provides a large native public video corpus that can support future large-scale pretraining of multimodal surgical AI systems and contribute to the development of next-generation foundation models for surgery.
TDMM-LM: Bridging Facial Understanding and Animation via Language Models
Mar 14, 2026Text-guided human body animation has advanced rapidly, yet facial animation lags due to the scarcity of well-annotated, text-paired facial corpora. To close this gap, we leverage foundation generative models to synthesize a large, balanced corpus of facial behavior. We design prompts suite covering emotions and head motions, generate about 80 hours of facial videos with multiple generators, and fit per-frame 3D facial parameters, yielding large-scale (prompt and parameter) pairs for training. Building on this dataset, we probe language models for bidirectional competence over facial motion via two complementary tasks: (1) Motion2Language: given a sequence of 3D facial parameters, the model produces natural-language descriptions capturing content, style, and dynamics; and (2) Language2Motion: given a prompt, the model synthesizes the corresponding sequence of 3D facial parameters via quantized motion tokens for downstream animation. Extensive experiments show that in this setting language models can both interpret and synthesize facial motion with strong generalization. To best of our knowledge, this is the first work to cast facial-parameter modeling as a language problem, establishing a unified path for text-conditioned facial animation and motion understanding.
Omni-Judge: Can Omni-LLMs Serve as Human-Aligned Judges for Text-Conditioned Audio-Video Generation?
Feb 02, 2026State-of-the-art text-to-video generation models such as Sora 2 and Veo 3 can now produce high-fidelity videos with synchronized audio directly from a textual prompt, marking a new milestone in multi-modal generation. However, evaluating such tri-modal outputs remains an unsolved challenge. Human evaluation is reliable but costly and difficult to scale, while traditional automatic metrics, such as FVD, CLAP, and ViCLIP, focus on isolated modality pairs, struggle with complex prompts, and provide limited interpretability. Omni-modal large language models (omni-LLMs) present a promising alternative: they naturally process audio, video, and text, support rich reasoning, and offer interpretable chain-of-thought feedback. Driven by this, we introduce Omni-Judge, a study assessing whether omni-LLMs can serve as human-aligned judges for text-conditioned audio-video generation. Across nine perceptual and alignment metrics, Omni-Judge achieves correlation comparable to traditional metrics and excels on semantically demanding tasks such as audio-text alignment, video-text alignment, and audio-video-text coherence. It underperforms on high-FPS perceptual metrics, including video quality and audio-video synchronization, due to limited temporal resolution. Omni-Judge provides interpretable explanations that expose semantic or physical inconsistencies, enabling practical downstream uses such as feedback-based refinement. Our findings highlight both the potential and current limitations of omni-LLMs as unified evaluators for multi-modal generation.
VisualActBench: Can VLMs See and Act like a Human?
Dec 10, 2025Vision-Language Models (VLMs) have achieved impressive progress in perceiving and describing visual environments. However, their ability to proactively reason and act based solely on visual inputs, without explicit textual prompts, remains underexplored. We introduce a new task, Visual Action Reasoning, and propose VisualActBench, a large-scale benchmark comprising 1,074 videos and 3,733 human-annotated actions across four real-world scenarios. Each action is labeled with an Action Prioritization Level (APL) and a proactive-reactive type to assess models' human-aligned reasoning and value sensitivity. We evaluate 29 VLMs on VisualActBench and find that while frontier models like GPT4o demonstrate relatively strong performance, a significant gap remains compared to human-level reasoning, particularly in generating proactive, high-priority actions. Our results highlight limitations in current VLMs' ability to interpret complex context, anticipate outcomes, and align with human decision-making frameworks. VisualActBench establishes a comprehensive foundation for assessing and improving the real-world readiness of proactive, vision-centric AI agents.
When to Think and When to Look: Uncertainty-Guided Lookback
Nov 19, 2025



Test-time thinking (that is, generating explicit intermediate reasoning chains) is known to boost performance in large language models and has recently shown strong gains for large vision language models (LVLMs). However, despite these promising results, there is still no systematic analysis of how thinking actually affects visual reasoning. We provide the first such analysis with a large scale, controlled comparison of thinking for LVLMs, evaluating ten variants from the InternVL3.5 and Qwen3-VL families on MMMU-val under generous token budgets and multi pass decoding. We show that more thinking is not always better; long chains often yield long wrong trajectories that ignore the image and underperform the same models run in standard instruct mode. A deeper analysis reveals that certain short lookback phrases, which explicitly refer back to the image, are strongly enriched in successful trajectories and correlate with better visual grounding. Building on this insight, we propose uncertainty guided lookback, a training free decoding strategy that combines an uncertainty signal with adaptive lookback prompts and breadth search. Our method improves overall MMMU performance, delivers the largest gains in categories where standard thinking is weak, and outperforms several strong decoding baselines, setting a new state of the art under fixed model families and token budgets. We further show that this decoding strategy generalizes, yielding consistent improvements on five additional benchmarks, including two broad multimodal suites and math focused visual reasoning datasets.
Diagnosing Visual Reasoning: Challenges, Insights, and a Path Forward
Oct 23, 2025Multimodal large language models (MLLMs) that integrate visual and textual reasoning leverage chain-of-thought (CoT) prompting to tackle complex visual tasks, yet continue to exhibit visual hallucinations and an over-reliance on textual priors. We present a systematic diagnosis of state-of-the-art vision-language models using a three-stage evaluation framework, uncovering key failure modes. To address these, we propose an agent-based architecture that combines LLM reasoning with lightweight visual modules, enabling fine-grained analysis and iterative refinement of reasoning chains. Our results highlight future visual reasoning models should focus on integrating a broader set of specialized tools for analyzing visual content. Our system achieves significant gains (+10.3 on MMMU, +6.0 on MathVista over a 7B baseline), matching or surpassing much larger models. We will release our framework and evaluation suite to facilitate future research.
Video-LMM Post-Training: A Deep Dive into Video Reasoning with Large Multimodal Models
Oct 06, 2025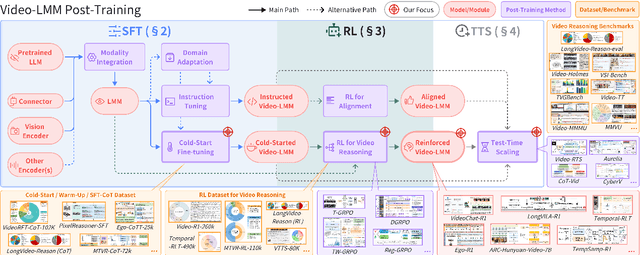
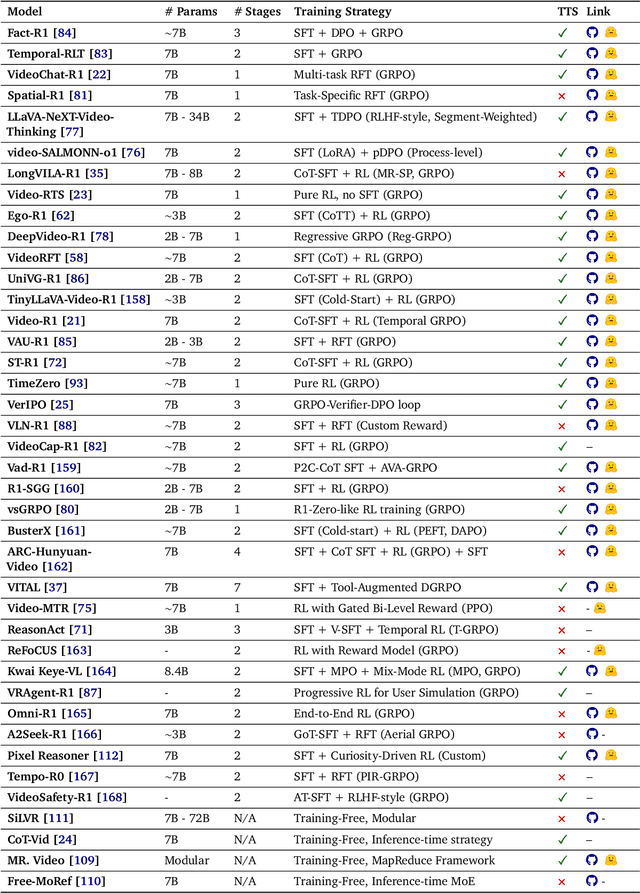
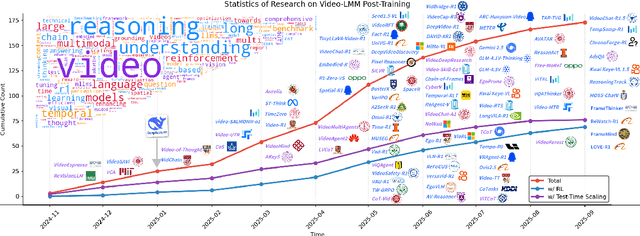
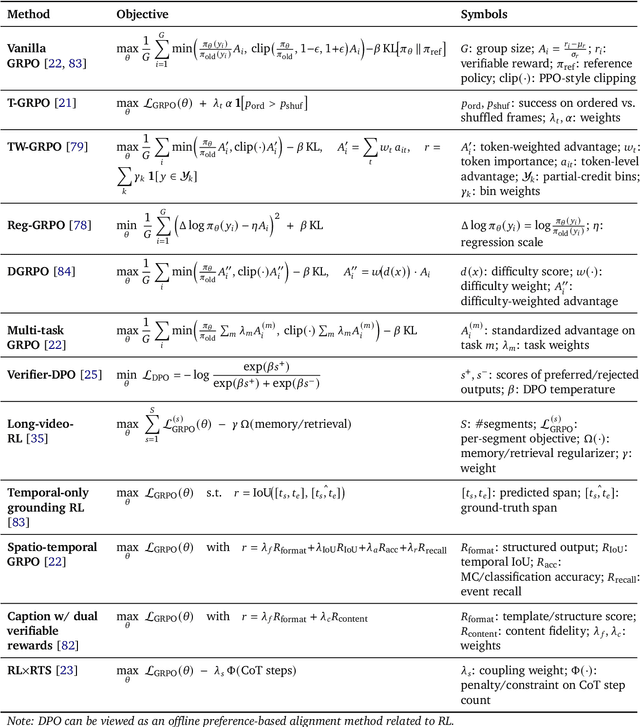
Video understanding represents the most challenging frontier in computer vision, requiring models to reason about complex spatiotemporal relationships, long-term dependencies, and multimodal evidence. The recent emergence of Video-Large Multimodal Models (Video-LMMs), which integrate visual encoders with powerful decoder-based language models, has demonstrated remarkable capabilities in video understanding tasks. However, the critical phase that transforms these models from basic perception systems into sophisticated reasoning engines, post-training, remains fragmented across the literature. This survey provides the first comprehensive examination of post-training methodologies for Video-LMMs, encompassing three fundamental pillars: supervised fine-tuning (SFT) with chain-of-thought, reinforcement learning (RL) from verifiable objectives, and test-time scaling (TTS) through enhanced inference computation. We present a structured taxonomy that clarifies the roles, interconnections, and video-specific adaptations of these techniques, addressing unique challenges such as temporal localization, spatiotemporal grounding, long video efficiency, and multimodal evidence integration. Through systematic analysis of representative methods, we synthesize key design principles, insights, and evaluation protocols while identifying critical open challenges in reward design, scalability, and cost-performance optimization. We further curate essential benchmarks, datasets, and metrics to facilitate rigorous assessment of post-training effectiveness. This survey aims to provide researchers and practitioners with a unified framework for advancing Video-LMM capabilities. Additional resources and updates are maintained at: https://github.com/yunlong10/Awesome-Video-LMM-Post-Training
rQdia: Regularizing Q-Value Distributions With Image Augmentation
Jun 26, 2025rQdia regularizes Q-value distributions with augmented images in pixel-based deep reinforcement learning. With a simple auxiliary loss, that equalizes these distributions via MSE, rQdia boosts DrQ and SAC on 9/12 and 10/12 tasks respectively in the MuJoCo Continuous Control Suite from pixels, and Data-Efficient Rainbow on 18/26 Atari Arcade environments. Gains are measured in both sample efficiency and longer-term training. Moreover, the addition of rQdia finally propels model-free continuous control from pixels over the state encoding baseline.
Can Sound Replace Vision in LLaVA With Token Substitution?
Jun 12, 2025While multimodal systems have achieved impressive advances, they typically rely on text-aligned representations rather than directly integrating audio and visual inputs. This reliance can limit the use of acoustic information in tasks requiring nuanced audio understanding. In response, SoundCLIP explores direct audio-visual integration within multimodal large language models (MLLMs) by substituting CLIP's visual tokens with audio representations and selecting sound-relevant patch tokens in models such as LLaVA. We investigate two configurations: (1) projecting audio features into CLIP's visual manifold via a multilayer perceptron trained with InfoNCE on paired audio-video segments, and (2) preserving raw audio embeddings with minimal dimensional adjustments. Experiments with five state-of-the-art audio encoders reveal a fundamental trade-off. While audio-to-video retrieval performance increases dramatically (up to 44 percentage points in Top-1 accuracy) when audio is projected into CLIP's space, text generation quality declines. Encoders pre-trained with text supervision (CLAP, Whisper, ImageBind) maintain stronger generative capabilities than those focused primarily on audiovisual alignment (Wav2CLIP, AudioCLIP), highlighting the value of language exposure for generation tasks. We introduce WhisperCLIP, an architecture that fuses intermediate representations from Whisper, as well as AudioVisual Event Evaluation (AVE-2), a dataset of 580,147 three-second audiovisual clips with fine-grained alignment annotations. Our findings challenge the assumption that stronger cross-modal alignment necessarily benefits all multimodal tasks; instead, a Pareto frontier emerges wherein optimal performance depends on balancing retrieval accuracy with text generation quality. Codes and datasets: https://github.com/ali-vosoughi/SoundCLIP.
ZeroSep: Separate Anything in Audio with Zero Training
May 29, 2025Audio source separation is fundamental for machines to understand complex acoustic environments and underpins numerous audio applications. Current supervised deep learning approaches, while powerful, are limited by the need for extensive, task-specific labeled data and struggle to generalize to the immense variability and open-set nature of real-world acoustic scenes. Inspired by the success of generative foundation models, we investigate whether pre-trained text-guided audio diffusion models can overcome these limitations. We make a surprising discovery: zero-shot source separation can be achieved purely through a pre-trained text-guided audio diffusion model under the right configuration. Our method, named ZeroSep, works by inverting the mixed audio into the diffusion model's latent space and then using text conditioning to guide the denoising process to recover individual sources. Without any task-specific training or fine-tuning, ZeroSep repurposes the generative diffusion model for a discriminative separation task and inherently supports open-set scenarios through its rich textual priors. ZeroSep is compatible with a variety of pre-trained text-guided audio diffusion backbones and delivers strong separation performance on multiple separation benchmarks, surpassing even supervised methods.