 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTaR-Attack: A Spatio-Temporal and Narrative Reasoning Attack Framework for Unified Multimodal Understanding and Generation Models
Sep 30, 2025



Unified Multimodal understanding and generation Models (UMMs) have demonstrated remarkable capabilities in both understanding and generation tasks. However, we identify a vulnerability arising from the generation-understanding coupling in UMMs. The attackers can use the generative function to craft an information-rich adversarial image and then leverage the understanding function to absorb it in a single pass, which we call Cross-Modal Generative Injection (CMGI). Current attack methods on malicious instructions are often limited to a single modality while also relying on prompt rewriting with semantic drift, leaving the unique vulnerabilities of UMMs unexplored. We propose STaR-Attack, the first multi-turn jailbreak attack framework that exploits unique safety weaknesses of UMMs without semantic drift. Specifically, our method defines a malicious event that is strongly correlated with the target query within a spatio-temporal context. Using the three-act narrative theory, STaR-Attack generates the pre-event and the post-event scenes while concealing the malicious event as the hidden climax. When executing the attack strategy, the opening two rounds exploit the UMM's generative ability to produce images for these scenes. Subsequently, an image-based question guessing and answering game is introduced by exploiting the understanding capability. STaR-Attack embeds the original malicious question among benign candidates, forcing the model to select and answer the most relevant one given the narrative context. Extensive experiments show that STaR-Attack consistently surpasses prior approaches, achieving up to 93.06% ASR on Gemini-2.0-Flash and surpasses the strongest prior baseline, FlipAttack. Our work uncovers a critical yet underdeveloped vulnerability and highlights the need for safety alignments in UMMs.
BAPFL: Exploring Backdoor Attacks Against Prototype-based Federated Learning
Sep 16, 2025Prototype-based federated learning (PFL) has emerged as a promising paradigm to address data heterogeneity problems in federated learning, as it leverages mean feature vectors as prototypes to enhance model generalization. However, its robustness against backdoor attacks remains largely unexplored. In this paper, we identify that PFL is inherently resistant to existing backdoor attacks due to its unique prototype learning mechanism and local data heterogeneity. To further explore the security of PFL, we propose BAPFL, the first backdoor attack method specifically designed for PFL frameworks. BAPFL integrates a prototype poisoning strategy with a trigger optimization mechanism. The prototype poisoning strategy manipulates the trajectories of global prototypes to mislead the prototype training of benign clients, pushing their local prototypes of clean samples away from the prototypes of trigger-embedded samples. Meanwhile, the trigger optimization mechanism learns a unique and stealthy trigger for each potential target label, and guides the prototypes of trigger-embedded samples to align closely with the global prototype of the target label. Experimental results across multiple datasets and PFL variants demonstrate that BAPFL achieves a 35\%-75\% improvement in attack success rate compared to traditional backdoor attacks, while preserving main task accuracy. These results highlight the effectiveness, stealthiness, and adaptability of BAPFL in PFL.
EEG-FM-Bench: A Comprehensive Benchmark for the Systematic Evaluation of EEG Foundation Models
Aug 25, 2025
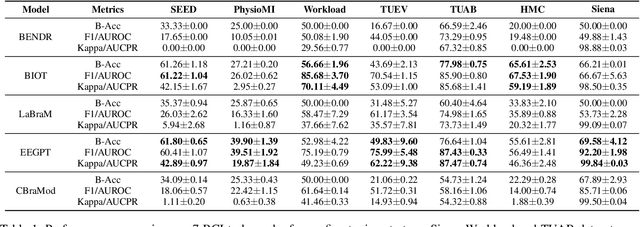
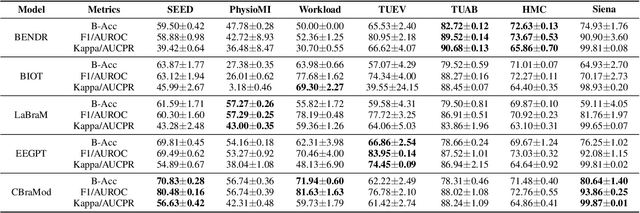
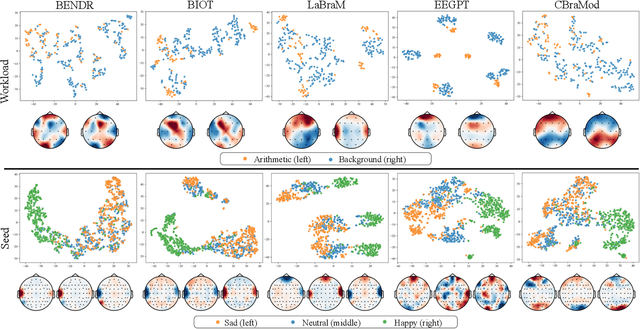
Electroencephalography (EEG) foundation models are poised to significantly advance brain signal analysis by learning robust representations from large-scale, unlabeled datasets. However, their rapid proliferation has outpaced the development of standardized evaluation benchmarks, which complicates direct model comparisons and hinders systematic scientific progress. This fragmentation fosters scientific inefficiency and obscures genuine architectural advancements. To address this critical gap, we introduce EEG-FM-Bench, the first comprehensive benchmark for the systematic and standardized evaluation of EEG foundation models (EEG-FMs). Our contributions are threefold: (1) we curate a diverse suite of downstream tasks and datasets from canonical EEG paradigms, implementing standardized processing and evaluation protocols within a unified open-source framework; (2) we benchmark prominent state-of-the-art foundation models to establish comprehensive baseline results for a clear comparison of the current landscape; (3) we perform qualitative analyses of the learned representations to provide insights into model behavior and inform future architectural design. Through extensive experiments, we find that fine-grained spatio-temporal feature interaction, multitask unified training and neuropsychological priors would contribute to enhancing model performance and generalization capabilities. By offering a unified platform for fair comparison and reproducible research, EEG-FM-Bench seeks to catalyze progress and guide the community toward the development of more robust and generalizable EEG-FMs. Code is released at https://github.com/xw1216/EEG-FM-Bench.
Disentangling Multiplex Spatial-Temporal Transition Graph Representation Learning for Socially Enhanced POI Recommendation
Aug 11, 2025Next Point-of-Interest (POI) recommendation is a research hotspot in business intelligence, where users' spatial-temporal transitions and social relationships play key roles. However, most existing works model spatial and temporal transitions separately, leading to misaligned representations of the same spatial-temporal key nodes. This misalignment introduces redundant information during fusion, increasing model uncertainty and reducing interpretability. To address this issue, we propose DiMuST, a socially enhanced POI recommendation model based on disentangled representation learning over multiplex spatial-temporal transition graphs. The model employs a novel Disentangled variational multiplex graph Auto-Encoder (DAE), which first disentangles shared and private distributions using a multiplex spatial-temporal graph strategy. It then fuses the shared features via a Product of Experts (PoE) mechanism and denoises the private features through contrastive constraints. The model effectively captures the spatial-temporal transition representations of POIs while preserving the intrinsic correlation of their spatial-temporal relationships. Experiments on two challenging datasets demonstrate that our DiMuST significantly outperforms existing methods across multiple metrics.
MemoryKT: An Integrative Memory-and-Forgetting Method for Knowledge Tracing
Aug 11, 2025Knowledge Tracing (KT) is committed to capturing students' knowledge mastery from their historical interactions. Simulating students' memory states is a promising approach to enhance both the performance and interpretability of knowledge tracing models. Memory consists of three fundamental processes: encoding, storage, and retrieval. Although forgetting primarily manifests during the storage stage, most existing studies rely on a single, undifferentiated forgetting mechanism, overlooking other memory processes as well as personalized forgetting patterns. To address this, this paper proposes memoryKT, a knowledge tracing model based on a novel temporal variational autoencoder. The model simulates memory dynamics through a three-stage process: (i) Learning the distribution of students' knowledge memory features, (ii) Reconstructing their exercise feedback, while (iii) Embedding a personalized forgetting module within the temporal workflow to dynamically modulate memory storage strength. This jointly models the complete encoding-storage-retrieval cycle, significantly enhancing the model's perception capability for individual differences. Extensive experiments on four public datasets demonstrate that our proposed approach significantly outperforms state-of-the-art baselines.
TELEVAL: A Dynamic Benchmark Designed for Spoken Language Models in Chinese Interactive Scenarios
Jul 24, 2025Spoken language models (SLMs) have seen rapid progress in recent years, along with the development of numerous benchmarks for evaluating their performance. However, most existing benchmarks primarily focus on evaluating whether SLMs can perform complex tasks comparable to those tackled by large language models (LLMs), often failing to align with how users naturally interact in real-world conversational scenarios. In this paper, we propose TELEVAL, a dynamic benchmark specifically designed to evaluate SLMs' effectiveness as conversational agents in realistic Chinese interactive settings. TELEVAL defines three evaluation dimensions: Explicit Semantics, Paralinguistic and Implicit Semantics, and System Abilities. It adopts a dialogue format consistent with real-world usage and evaluates text and audio outputs separately. TELEVAL particularly focuses on the model's ability to extract implicit cues from user speech and respond appropriately without additional instructions. Our experiments demonstrate that despite recent progress, existing SLMs still have considerable room for improvement in natural conversational tasks. We hope that TELEVAL can serve as a user-centered evaluation framework that directly reflects the user experience and contributes to the development of more capable dialogue-oriented SLMs.
SafeWork-R1: Coevolving Safety and Intelligence under the AI-45$^{\circ}$ Law
Jul 24, 2025



We introduce SafeWork-R1, a cutting-edge multimodal reasoning model that demonstrates the coevolution of capabilities and safety. It is developed by our proposed SafeLadder framework, which incorporates large-scale, progressive, safety-oriented reinforcement learning post-training, supported by a suite of multi-principled verifiers. Unlike previous alignment methods such as RLHF that simply learn human preferences, SafeLadder enables SafeWork-R1 to develop intrinsic safety reasoning and self-reflection abilities, giving rise to safety `aha' moments. Notably, SafeWork-R1 achieves an average improvement of $46.54\%$ over its base model Qwen2.5-VL-72B on safety-related benchmarks without compromising general capabilities, and delivers state-of-the-art safety performance compared to leading proprietary models such as GPT-4.1 and Claude Opus 4. To further bolster its reliability, we implement two distinct inference-time intervention methods and a deliberative search mechanism, enforcing step-level verification. Finally, we further develop SafeWork-R1-InternVL3-78B, SafeWork-R1-DeepSeek-70B, and SafeWork-R1-Qwen2.5VL-7B. All resulting models demonstrate that safety and capability can co-evolve synergistically, highlighting the generalizability of our framework in building robust, reliable, and trustworthy general-purpose AI.
BoSS: Beyond-Semantic Speech
Jul 23, 2025Human communication involves more than explicit semantics, with implicit signals and contextual cues playing a critical role in shaping meaning. However, modern speech technologies, such as Automatic Speech Recognition (ASR) and Text-to-Speech (TTS) often fail to capture these beyond-semantic dimensions. To better characterize and benchmark the progression of speech intelligence, we introduce Spoken Interaction System Capability Levels (L1-L5), a hierarchical framework illustrated the evolution of spoken dialogue systems from basic command recognition to human-like social interaction. To support these advanced capabilities, we propose Beyond-Semantic Speech (BoSS), which refers to the set of information in speech communication that encompasses but transcends explicit semantics. It conveys emotions, contexts, and modifies or extends meanings through multidimensional features such as affective cues, contextual dynamics, and implicit semantics, thereby enhancing the understanding of communicative intentions and scenarios. We present a formalized framework for BoSS, leveraging cognitive relevance theories and machine learning models to analyze temporal and contextual speech dynamics. We evaluate BoSS-related attributes across five different dimensions, reveals that current spoken language models (SLMs) are hard to fully interpret beyond-semantic signals. These findings highlight the need for advancing BoSS research to enable richer, more context-aware human-machine communication.
WonderFree: Enhancing Novel View Quality and Cross-View Consistency for 3D Scene Exploration
Jun 25, 2025Interactive 3D scene generation from a single image has gained significant attention due to its potential to create immersive virtual worlds. However, a key challenge in current 3D generation methods is the limited explorability, which cannot render high-quality images during larger maneuvers beyond the original viewpoint, particularly when attempting to move forward into unseen areas. To address this challenge, we propose WonderFree, the first model that enables users to interactively generate 3D worlds with the freedom to explore from arbitrary angles and directions. Specifically, we decouple this challenge into two key subproblems: novel view quality, which addresses visual artifacts and floating issues in novel views, and cross-view consistency, which ensures spatial consistency across different viewpoints. To enhance rendering quality in novel views, we introduce WorldRestorer, a data-driven video restoration model designed to eliminate floaters and artifacts. In addition, a data collection pipeline is presented to automatically gather training data for WorldRestorer, ensuring it can handle scenes with varying styles needed for 3D scene generation. Furthermore, to improve cross-view consistency, we propose ConsistView, a multi-view joint restoration mechanism that simultaneously restores multiple perspectives while maintaining spatiotemporal coherence. Experimental results demonstrate that WonderFree not only enhances rendering quality across diverse viewpoints but also significantly improves global coherence and consistency. These improvements are confirmed by CLIP-based metrics and a user study showing a 77.20% preference for WonderFree over WonderWorld enabling a seamless and immersive 3D exploration experience. The code, model, and data will be publicly available.
EKPC: Elastic Knowledge Preservation and Compensation for Class-Incremental Learning
Jun 14, 2025Class-Incremental Learning (CIL) aims to enable AI models to continuously learn from sequentially arriving data of different classes over time while retaining previously acquired knowledge. Recently, Parameter-Efficient Fine-Tuning (PEFT) methods, like prompt pool-based approaches and adapter tuning, have shown great attraction in CIL. However, these methods either introduce additional parameters that increase memory usage, or rely on rigid regularization techniques which reduce forgetting but compromise model flexibility. To overcome these limitations, we propose the Elastic Knowledge Preservation and Compensation (EKPC) method, integrating Importance-aware Parameter Regularization (IPR) and Trainable Semantic Drift Compensation (TSDC) for CIL. Specifically, the IPR method assesses the sensitivity of network parameters to prior tasks using a novel parameter-importance algorithm. It then selectively constrains updates within the shared adapter according to these importance values, thereby preserving previously acquired knowledge while maintaining the model's flexibility. However, it still exhibits slight semantic differences in previous knowledge to accommodate new incremental tasks, leading to decision boundaries confusion in classifier. To eliminate this confusion, TSDC trains a unified classifier by compensating prototypes with trainable semantic drift. Extensive experiments on five CIL benchmarks demonstrate the effectiveness of the proposed method, showing superior performances to existing state-of-the-art methods.