 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Cross-Modal Retrieval with Missing Modalities via Semantic Routing and Adapter Personalization
Apr 24, 2026Federated cross-modal retrieval faces severe challenges from heterogeneous client data, particularly non-IID semantic distributions and missing modalities. Under such heterogeneity, a single global model is often insufficient to capture both shared cross-modal knowledge and client-specific characteristics. We propose RCSR, a personalization-friendly federated framework that integrates prototype anchoring, retrieval-centric semantic routing, and optional client-specific adapters. Built on a frozen CLIP backbone, RCSR leverages lightweight shared adapters for global knowledge transfer while supporting efficient local personalization. Prototype anchoring helps unimodal clients align with global cross-modal semantics, and a server-side semantic router adaptively assigns aggregation weights based on retrieval consistency to mitigate alignment drift during heterogeneous updates. Extensive experiments on MS-COCO, Flickr30K, and other benchmarks show that RCSR consistently improves global retrieval accuracy and training stability, while further enhancing client-level retrieval performance, especially for clients with incomplete modalities. Code is available at https://github.com/RezinChow/RCSR-Retrieval-Centric-Semantic-Routing.
AgentTutor: Empowering Personalized Learning with Multi-Turn Interactive Teaching in Intelligent Education Systems
Dec 24, 2025The rapid advancement of large-scale language models (LLMs) has shown their potential to transform intelligent education systems (IESs) through automated teaching and learning support applications. However, current IESs often rely on single-turn static question-answering, which fails to assess learners' cognitive levels, cannot adjust teaching strategies based on real-time feedback, and is limited to providing simple one-off responses. To address these issues, we introduce AgentTutor, a multi-turn interactive intelligent education system to empower personalized learning. It features an LLM-powered generative multi-agent system and a learner-specific personalized learning profile environment that dynamically optimizes and delivers teaching strategies based on learners' learning status, personalized goals, learning preferences, and multimodal study materials. It includes five key modules: curriculum decomposition, learner assessment, dynamic strategy, teaching reflection, and knowledge & experience memory. We conducted extensive experiments on multiple benchmark datasets, AgentTutor significantly enhances learners' performance while demonstrating strong effectiveness in multi-turn interactions and competitiveness in teaching quality among other baselines.
BAPFL: Exploring Backdoor Attacks Against Prototype-based Federated Learning
Sep 16, 2025Prototype-based federated learning (PFL) has emerged as a promising paradigm to address data heterogeneity problems in federated learning, as it leverages mean feature vectors as prototypes to enhance model generalization. However, its robustness against backdoor attacks remains largely unexplored. In this paper, we identify that PFL is inherently resistant to existing backdoor attacks due to its unique prototype learning mechanism and local data heterogeneity. To further explore the security of PFL, we propose BAPFL, the first backdoor attack method specifically designed for PFL frameworks. BAPFL integrates a prototype poisoning strategy with a trigger optimization mechanism. The prototype poisoning strategy manipulates the trajectories of global prototypes to mislead the prototype training of benign clients, pushing their local prototypes of clean samples away from the prototypes of trigger-embedded samples. Meanwhile, the trigger optimization mechanism learns a unique and stealthy trigger for each potential target label, and guides the prototypes of trigger-embedded samples to align closely with the global prototype of the target label. Experimental results across multiple datasets and PFL variants demonstrate that BAPFL achieves a 35\%-75\% improvement in attack success rate compared to traditional backdoor attacks, while preserving main task accuracy. These results highlight the effectiveness, stealthiness, and adaptability of BAPFL in PFL.
STREAMINGGS: Voxel-Based Streaming 3D Gaussian Splatting with Memory Optimization and Architectural Support
Jun 09, 2025



3D Gaussian Splatting (3DGS) has gained popularity for its efficiency and sparse Gaussian-based representation. However, 3DGS struggles to meet the real-time requirement of 90 frames per second (FPS) on resource-constrained mobile devices, achieving only 2 to 9 FPS.Existing accelerators focus on compute efficiency but overlook memory efficiency, leading to redundant DRAM traffic. We introduce STREAMINGGS, a fully streaming 3DGS algorithm-architecture co-design that achieves fine-grained pipelining and reduces DRAM traffic by transforming from a tile-centric rendering to a memory-centric rendering. Results show that our design achieves up to 45.7 $\times$ speedup and 62.9 $\times$ energy savings over mobile Ampere GPUs.
LocalGCL: Local-aware Contrastive Learning for Graphs
Feb 27, 2024Graph representation learning (GRL) makes considerable progress recently, which encodes graphs with topological structures into low-dimensional embeddings. Meanwhile, the time-consuming and costly process of annotating graph labels manually prompts the growth of self-supervised learning (SSL) techniques. As a dominant approach of SSL, Contrastive learning (CL) learns discriminative representations by differentiating between positive and negative samples. However, when applied to graph data, it overemphasizes global patterns while neglecting local structures. To tackle the above issue, we propose \underline{Local}-aware \underline{G}raph \underline{C}ontrastive \underline{L}earning (\textbf{\methnametrim}), a self-supervised learning framework that supplementarily captures local graph information with masking-based modeling compared with vanilla contrastive learning. Extensive experiments validate the superiority of \methname against state-of-the-art methods, demonstrating its promise as a comprehensive graph representation learner.
SecureCut: Federated Gradient Boosting Decision Trees with Efficient Machine Unlearning
Nov 22, 2023



In response to legislation mandating companies to honor the \textit{right to be forgotten} by erasing user data, it has become imperative to enable data removal in Vertical Federated Learning (VFL) where multiple parties provide private features for model training. In VFL, data removal, i.e., \textit{machine unlearning}, often requires removing specific features across all samples under privacy guarentee in federated learning. To address this challenge, we propose \methname, a novel Gradient Boosting Decision Tree (GBDT) framework that effectively enables both \textit{instance unlearning} and \textit{feature unlearning} without the need for retraining from scratch. Leveraging a robust GBDT structure, we enable effective data deletion while reducing degradation of model performance. Extensive experimental results on popular datasets demonstrate that our method achieves superior model utility and forgetfulness compared to \textit{state-of-the-art} methods. To our best knowledge, this is the first work that investigates machine unlearning in VFL scenarios.
MARS: Exploiting Multi-Level Parallelism for DNN Workloads on Adaptive Multi-Accelerator Systems
Jul 23, 2023



Along with the fast evolution of deep neural networks, the hardware system is also developing rapidly. As a promising solution achieving high scalability and low manufacturing cost, multi-accelerator systems widely exist in data centers, cloud platforms, and SoCs. Thus, a challenging problem arises in multi-accelerator systems: selecting a proper combination of accelerators from available designs and searching for efficient DNN mapping strategies. To this end, we propose MARS, a novel mapping framework that can perform computation-aware accelerator selection, and apply communication-aware sharding strategies to maximize parallelism. Experimental results show that MARS can achieve 32.2% latency reduction on average for typical DNN workloads compared to the baseline, and 59.4% latency reduction on heterogeneous models compared to the corresponding state-of-the-art method.
Temporal Gradient Inversion Attacks with Robust Optimization
Jun 13, 2023



Federated Learning (FL) has emerged as a promising approach for collaborative model training without sharing private data. However, privacy concerns regarding information exchanged during FL have received significant research attention. Gradient Inversion Attacks (GIAs) have been proposed to reconstruct the private data retained by local clients from the exchanged gradients. While recovering private data, the data dimensions and the model complexity increase, which thwart data reconstruction by GIAs. Existing methods adopt prior knowledge about private data to overcome those challenges. In this paper, we first observe that GIAs with gradients from a single iteration fail to reconstruct private data due to insufficient dimensions of leaked gradients, complex model architectures, and invalid gradient information. We investigate a Temporal Gradient Inversion Attack with a Robust Optimization framework, called TGIAs-RO, which recovers private data without any prior knowledge by leveraging multiple temporal gradients. To eliminate the negative impacts of outliers, e.g., invalid gradients for collaborative optimization, robust statistics are proposed. Theoretical guarantees on the recovery performance and robustness of TGIAs-RO against invalid gradients are also provided. Extensive empirical results on MNIST, CIFAR10, ImageNet and Reuters 21578 datasets show that the proposed TGIAs-RO with 10 temporal gradients improves reconstruction performance compared to state-of-the-art methods, even for large batch sizes (up to 128), complex models like ResNet18, and large datasets like ImageNet (224*224 pixels). Furthermore, the proposed attack method inspires further exploration of privacy-preserving methods in the context of FL.
Adaptive incentive for cross-silo federated learning: A multi-agent reinforcement learning approach
Feb 15, 2023


Cross-silo federated learning (FL) is a typical FL that enables organizations(e.g., financial or medical entities) to train global models on isolated data. Reasonable incentive is key to encouraging organizations to contribute data. However, existing works on incentivizing cross-silo FL lack consideration of the environmental dynamics (e.g., precision of the trained global model and data owned by uncertain clients during the training processes). Moreover, most of them assume that organizations share private information, which is unrealistic. To overcome these limitations, we propose a novel adaptive mechanism for cross-silo FL, towards incentivizing organizations to contribute data to maximize their long-term payoffs in a real dynamic training environment. The mechanism is based on multi-agent reinforcement learning, which learns near-optimal data contribution strategy from the history of potential games without organizations' private information. Experiments demonstrate that our mechanism achieves adaptive incentive and effectively improves the long-term payoffs for organizations.
GraphCoCo: Graph Complementary Contrastive Learning
Mar 24, 2022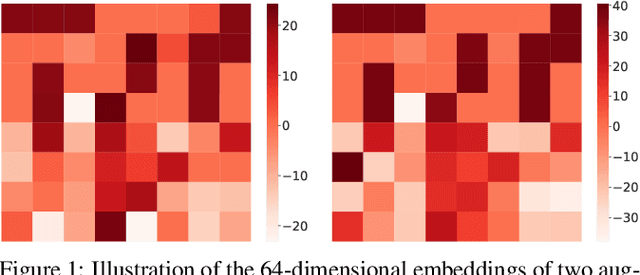
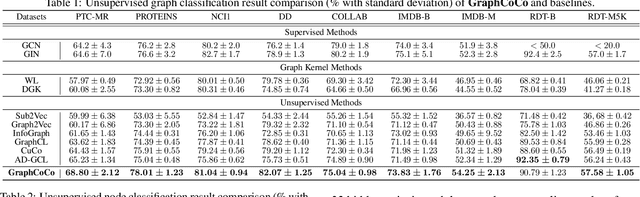
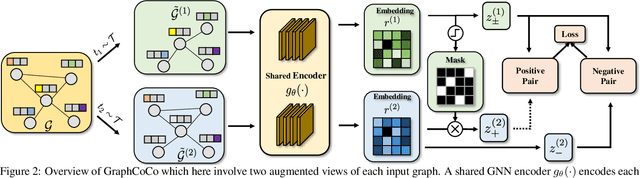
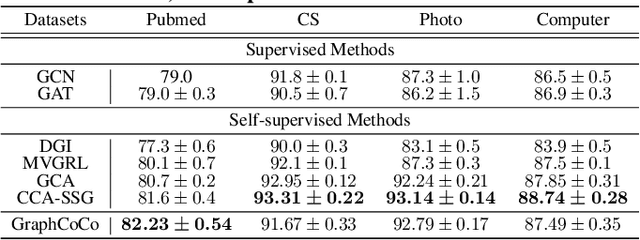
Graph Contrastive Learning (GCL) has shown promising performance in graph representation learning (GRL) without the supervision of manual annotations. GCL can generate graph-level embeddings by maximizing the Mutual Information (MI) between different augmented views of the same graph (positive pairs). However, we identify an obstacle that the optimization of InfoNCE loss only concentrates on a few embeddings dimensions, limiting the distinguishability of embeddings in downstream graph classification tasks. This paper proposes an effective graph complementary contrastive learning approach named GraphCoCo to tackle the above issue. Specifically, we set the embedding of the first augmented view as the anchor embedding to localize "highlighted" dimensions (i.e., the dimensions contribute most in similarity measurement). Then remove these dimensions in the embeddings of the second augmented view to discover neglected complementary representations. Therefore, the combination of anchor and complementary embeddings significantly improves the performance in downstream tasks. Comprehensive experiments on various benchmark datasets are conducted to demonstrate the effectiveness of GraphCoCo, and the results show that our model outperforms the state-of-the-art methods. Source code will be made publicly available.