 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisentangling Multiplex Spatial-Temporal Transition Graph Representation Learning for Socially Enhanced POI Recommendation
Aug 11, 2025Next Point-of-Interest (POI) recommendation is a research hotspot in business intelligence, where users' spatial-temporal transitions and social relationships play key roles. However, most existing works model spatial and temporal transitions separately, leading to misaligned representations of the same spatial-temporal key nodes. This misalignment introduces redundant information during fusion, increasing model uncertainty and reducing interpretability. To address this issue, we propose DiMuST, a socially enhanced POI recommendation model based on disentangled representation learning over multiplex spatial-temporal transition graphs. The model employs a novel Disentangled variational multiplex graph Auto-Encoder (DAE), which first disentangles shared and private distributions using a multiplex spatial-temporal graph strategy. It then fuses the shared features via a Product of Experts (PoE) mechanism and denoises the private features through contrastive constraints. The model effectively captures the spatial-temporal transition representations of POIs while preserving the intrinsic correlation of their spatial-temporal relationships. Experiments on two challenging datasets demonstrate that our DiMuST significantly outperforms existing methods across multiple metrics.
MemoryKT: An Integrative Memory-and-Forgetting Method for Knowledge Tracing
Aug 11, 2025Knowledge Tracing (KT) is committed to capturing students' knowledge mastery from their historical interactions. Simulating students' memory states is a promising approach to enhance both the performance and interpretability of knowledge tracing models. Memory consists of three fundamental processes: encoding, storage, and retrieval. Although forgetting primarily manifests during the storage stage, most existing studies rely on a single, undifferentiated forgetting mechanism, overlooking other memory processes as well as personalized forgetting patterns. To address this, this paper proposes memoryKT, a knowledge tracing model based on a novel temporal variational autoencoder. The model simulates memory dynamics through a three-stage process: (i) Learning the distribution of students' knowledge memory features, (ii) Reconstructing their exercise feedback, while (iii) Embedding a personalized forgetting module within the temporal workflow to dynamically modulate memory storage strength. This jointly models the complete encoding-storage-retrieval cycle, significantly enhancing the model's perception capability for individual differences. Extensive experiments on four public datasets demonstrate that our proposed approach significantly outperforms state-of-the-art baselines.
Region Proposal Network with Graph Prior and IoU-Balance Loss for Landmark Detection in 3D Ultrasound
Apr 01, 2020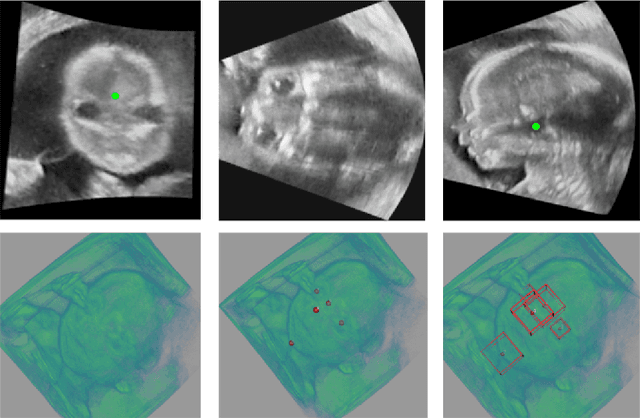
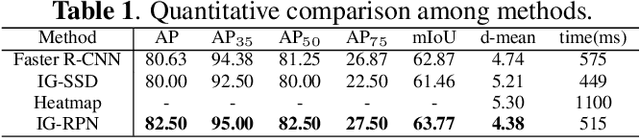
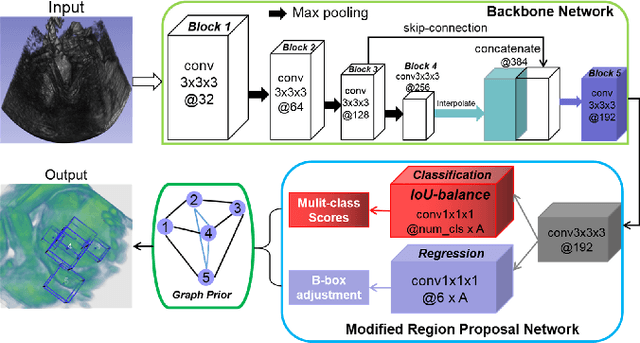
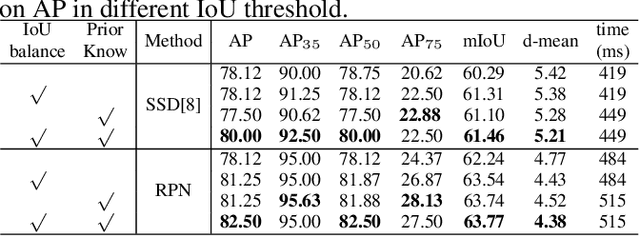
3D ultrasound (US) can facilitate detailed prenatal examinations for fetal growth monitoring. To analyze a 3D US volume, it is fundamental to identify anatomical landmarks of the evaluated organs accurately. Typical deep learning methods usually regress the coordinates directly or involve heatmap-matching. However, these methods struggle to deal with volumes with large sizes and the highly-varying positions and orientations of fetuses. In this work, we exploit an object detection framework to detect landmarks in 3D fetal facial US volumes. By regressing multiple parameters of the landmark-centered bounding box (B-box) with a strict criteria, the proposed model is able to pinpoint the exact location of the targeted landmarks. Specifically, the model uses a 3D region proposal network (RPN) to generate 3D candidate regions, followed by several 3D classification branches to select the best candidate. It also adopts an IoU-balance loss to improve communications between branches that benefits the learning process. Furthermore, it leverages a distance-based graph prior to regularize the training and helps to reduce false positive predictions. The performance of the proposed framework is evaluated on a 3D US dataset to detect five key fetal facial landmarks. Results showed the proposed method outperforms some of the state-of-the-art methods in efficacy and efficiency.