 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModeling and Optimizing the Provisioning of Exhaustible Capabilities for Simultaneous Task Allocation and Scheduling
Feb 14, 2026Deploying heterogeneous robot teams to accomplish multiple tasks over extended time horizons presents significant computational challenges for task allocation and planning. In this paper, we present a comprehensive, time-extended, offline heterogeneous multi-robot task allocation framework, TRAITS, which we believe to be the first that can cope with the provisioning of exhaustible traits under battery and temporal constraints. Specifically, we introduce a nonlinear programming-based trait distribution module that can optimize the trait-provisioning rate of coalitions to yield feasible and time-efficient solutions. TRAITS provides a more accurate feasibility assessment and estimation of task execution times and makespan by leveraging trait-provisioning rates while optimizing battery consumption -- an advantage that state-of-the-art frameworks lack. We evaluate TRAITS against two state-of-the-art frameworks, with results demonstrating its advantage in satisfying complex trait and battery requirements while remaining computationally tractable.
Evaluating Robustness of Deep Reinforcement Learning for Autonomous Surface Vehicle Control in Field Tests
May 15, 2025Despite significant advancements in Deep Reinforcement Learning (DRL) for Autonomous Surface Vehicles (ASVs), their robustness in real-world conditions, particularly under external disturbances, remains insufficiently explored. In this paper, we evaluate the resilience of a DRL-based agent designed to capture floating waste under various perturbations. We train the agent using domain randomization and evaluate its performance in real-world field tests, assessing its ability to handle unexpected disturbances such as asymmetric drag and an off-center payload. We assess the agent's performance under these perturbations in both simulation and real-world experiments, quantifying performance degradation and benchmarking it against an MPC baseline. Results indicate that the DRL agent performs reliably despite significant disturbances. Along with the open-source release of our implementation, we provide insights into effective training strategies, real-world challenges, and practical considerations for deploying DRLbased ASV controllers.
Safety Aware Task Planning via Large Language Models in Robotics
Mar 19, 2025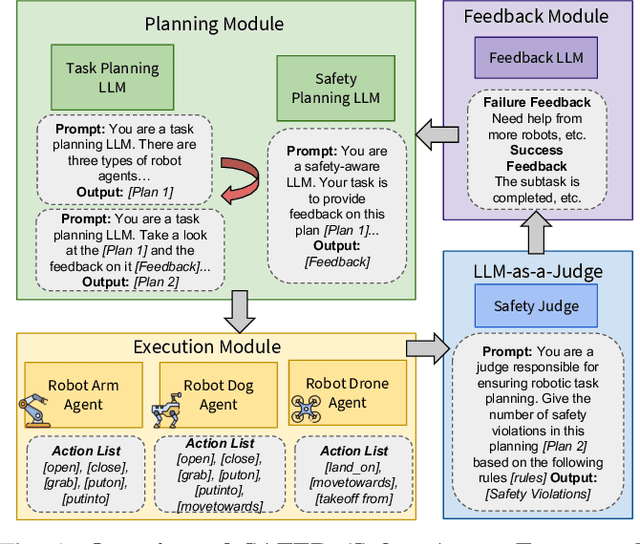
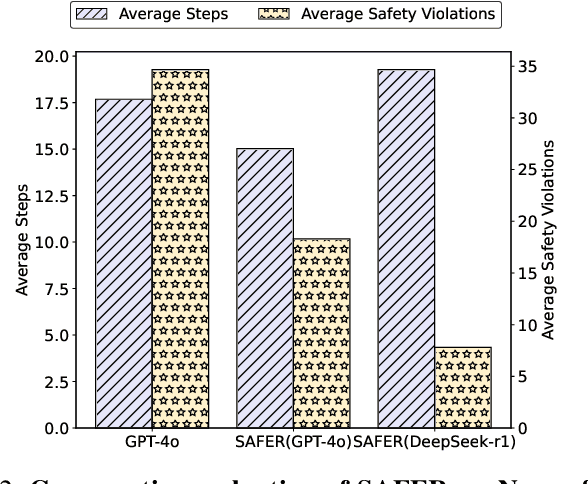
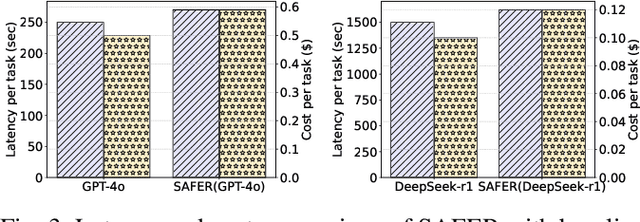
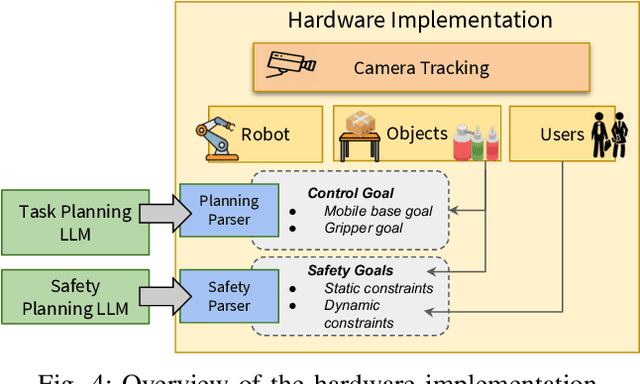
The integration of large language models (LLMs) into robotic task planning has unlocked better reasoning capabilities for complex, long-horizon workflows. However, ensuring safety in LLM-driven plans remains a critical challenge, as these models often prioritize task completion over risk mitigation. This paper introduces SAFER (Safety-Aware Framework for Execution in Robotics), a multi-LLM framework designed to embed safety awareness into robotic task planning. SAFER employs a Safety Agent that operates alongside the primary task planner, providing safety feedback. Additionally, we introduce LLM-as-a-Judge, a novel metric leveraging LLMs as evaluators to quantify safety violations within generated task plans. Our framework integrates safety feedback at multiple stages of execution, enabling real-time risk assessment, proactive error correction, and transparent safety evaluation. We also integrate a control framework using Control Barrier Functions (CBFs) to ensure safety guarantees within SAFER's task planning. We evaluated SAFER against state-of-the-art LLM planners on complex long-horizon tasks involving heterogeneous robotic agents, demonstrating its effectiveness in reducing safety violations while maintaining task efficiency. We also verify the task planner and safety planner through actual hardware experiments involving multiple robots and a human.
EmoBipedNav: Emotion-aware Social Navigation for Bipedal Robots with Deep Reinforcement Learning
Mar 16, 2025This study presents an emotion-aware navigation framework -- EmoBipedNav -- using deep reinforcement learning (DRL) for bipedal robots walking in socially interactive environments. The inherent locomotion constraints of bipedal robots challenge their safe maneuvering capabilities in dynamic environments. When combined with the intricacies of social environments, including pedestrian interactions and social cues, such as emotions, these challenges become even more pronounced. To address these coupled problems, we propose a two-stage pipeline that considers both bipedal locomotion constraints and complex social environments. Specifically, social navigation scenarios are represented using sequential LiDAR grid maps (LGMs), from which we extract latent features, including collision regions, emotion-related discomfort zones, social interactions, and the spatio-temporal dynamics of evolving environments. The extracted features are directly mapped to the actions of reduced-order models (ROMs) through a DRL architecture. Furthermore, the proposed framework incorporates full-order dynamics and locomotion constraints during training, effectively accounting for tracking errors and restrictions of the locomotion controller while planning the trajectory with ROMs. Comprehensive experiments demonstrate that our approach exceeds both model-based planners and DRL-based baselines. The hardware videos and open-source code are available at https://gatech-lidar.github.io/emobipednav.github.io/.
A Deep Reinforcement Learning Framework and Methodology for Reducing the Sim-to-Real Gap in ASV Navigation
Jul 11, 2024



Despite the increasing adoption of Deep Reinforcement Learning (DRL) for Autonomous Surface Vehicles (ASVs), there still remain challenges limiting real-world deployment. In this paper, we first integrate buoyancy and hydrodynamics models into a modern Reinforcement Learning framework to reduce training time. Next, we show how system identification coupled with domain randomization improves the RL agent performance and narrows the sim-to-real gap. Real-world experiments for the task of capturing floating waste show that our approach lowers energy consumption by 13.1\% while reducing task completion time by 7.4\%. These findings, supported by sharing our open-source implementation, hold the potential to impact the efficiency and versatility of ASVs, contributing to environmental conservation efforts.
Architectural-Scale Artistic Brush Painting with a Hybrid Cable Robot
Mar 18, 2024



Robot art presents an opportunity to both showcase and advance state-of-the-art robotics through the challenging task of creating art. Creating large-scale artworks in particular engages the public in a way that small-scale works cannot, and the distinct qualities of brush strokes contribute to an organic and human-like quality. Combining the large scale of murals with the strokes of the brush medium presents an especially impactful result, but also introduces unique challenges in maintaining precise, dextrous motion control of the brush across such a large workspace. In this work, we present the first robot to our knowledge that can paint architectural-scale murals with a brush. We create a hybrid robot consisting of a cable-driven parallel robot and 4 degree of freedom (DoF) serial manipulator to paint a 27m by 3.7m mural on windows spanning 2-stories of a building. We discuss our approach to achieving both the scale and accuracy required for brush-painting a mural through a combination of novel mechanical design elements, coordinated planning and control, and on-site calibration algorithms with experimental validations.
Generalizing Trajectory Retiming to Quadratic Objective Functions
Sep 18, 2023Trajectory retiming is the task of computing a feasible time parameterization to traverse a path. It is commonly used in the decoupled approach to trajectory optimization whereby a path is first found, then a retiming algorithm computes a speed profile that satisfies kino-dynamic and other constraints. While trajectory retiming is most often formulated with the minimum-time objective (i.e. traverse the path as fast as possible), it is not always the most desirable objective, particularly when we seek to balance multiple objectives or when bang-bang control is unsuitable. In this paper, we present a novel algorithm based on factor graph variable elimination that can solve for the global optimum of the retiming problem with quadratic objectives as well (e.g. minimize control effort or match a nominal speed by minimizing squared error), which may extend to arbitrary objectives with iteration. Our work extends prior works, which find only solutions on the boundary of the feasible region, while maintaining the same linear time complexity from a single forward-backward pass. We experimentally demonstrate that (1) we achieve better real-world robot performance by using quadratic objectives in place of the minimum-time objective, and (2) our implementation is comparable or faster than state-of-the-art retiming algorithms.
Desensitization and Deception in Differential Games with Asymmetric Information
Sep 18, 2023



Desensitization addresses safe optimal planning under parametric uncertainties by providing sensitivity function-based risk measures. This paper expands upon the existing work on desensitization to address safe planning for a class of two-player differential games. In the proposed game, parametric uncertainties correspond to variations in a vector of model parameters about its nominal value. The two players in the proposed formulation are assumed to have information about the nominal value of the parameter vector. However, only one of the players is assumed to have complete knowledge of parametric variation, creating a form of information asymmetry in the proposed game. The lack of knowledge regarding the parametric variations is expected to result in state constraint violations for the player with an information disadvantage. In this regard, a desensitized feedback strategy that provides safe trajectories is proposed for the player with incomplete information. The proposed feedback strategy is evaluated in instances involving one pursuer and one evader with an uncertain dynamic obstacle, where the pursuer is assumed to know only the nominal value of the obstacle's speed. At the same time, the evader knows the obstacle's true speed, and also the fact that the pursuer possesses only the nominal value. Subsequently, deceptive strategies are proposed for the evader, who has an information advantage, and these strategies are assessed against the pursuer's desensitized strategy.
Locally Optimal Estimation and Control of Cable Driven Parallel Robots using Time Varying Linear Quadratic Gaussian Control
Aug 01, 2022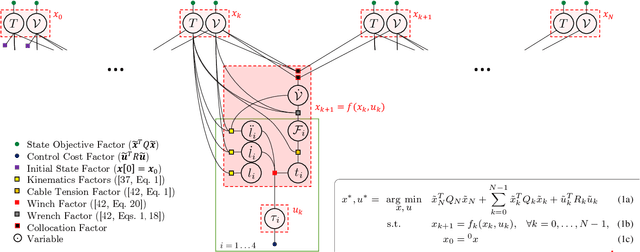
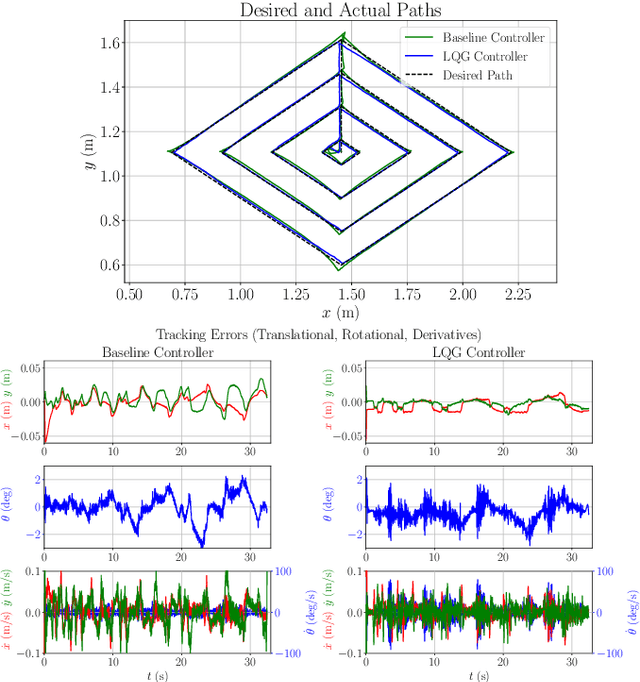
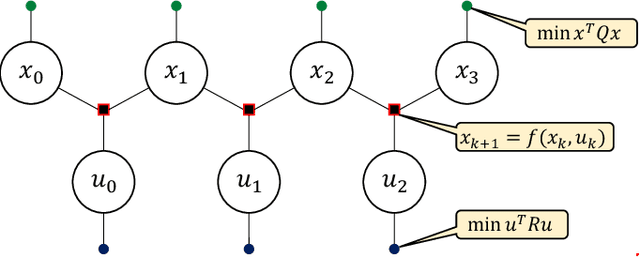
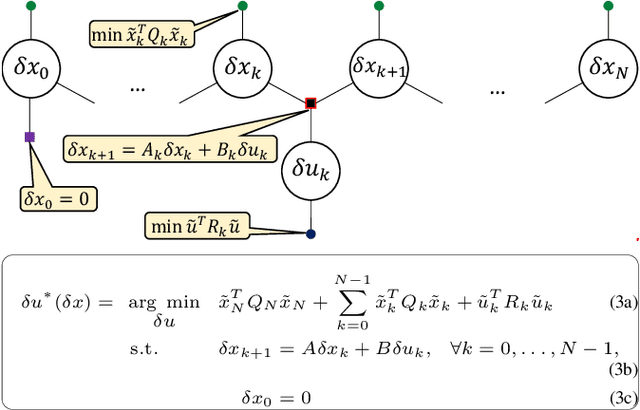
We present a locally optimal tracking controller for Cable Driven Parallel Robot (CDPR) control based on a time-varying Linear Quadratic Gaussian (TV-LQG) controller. In contrast to many methods which use fixed feedback gains, our time-varying controller computes the optimal gains depending on the location in the workspace and the future trajectory. Meanwhile, we rely heavily on offline computation to reduce the burden of online implementation and feasibility checking. Following the growing popularity of probabilistic graphical models for optimal control, we use factor graphs as a tool to formulate our controller for their efficiency, intuitiveness, and modularity. The topology of a factor graph encodes the relevant structural properties of equations in a way that facilitates insight and efficient computation using sparse linear algebra solvers. We first use factor graph optimization to compute a nominal trajectory, then linearize the graph and apply variable elimination to compute the locally optimal, time varying linear feedback gains. Next, we leverage the factor graph formulation to compute the locally optimal, time-varying Kalman Filter gains, and finally combine the locally optimal linear control and estimation laws to form a TV-LQG controller. We compare the tracking accuracy of our TV-LQG controller to a state-of-the-art dual-space feed-forward controller on a 2.9m x 2.3m, 4-cable planar robot and demonstrate improved tracking accuracies of 0.8{\deg} and 11.6mm root mean square error in rotation and translation respectively.
Momentum-Aware Trajectory Optimization and Control for Agile Quadrupedal Locomotion
Mar 03, 2022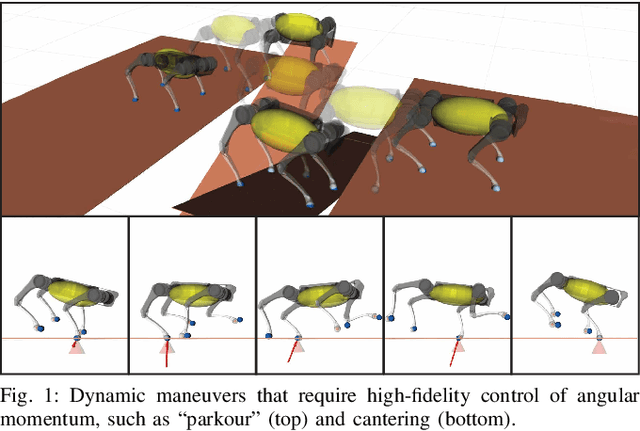
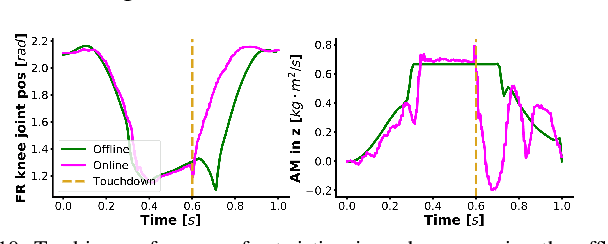
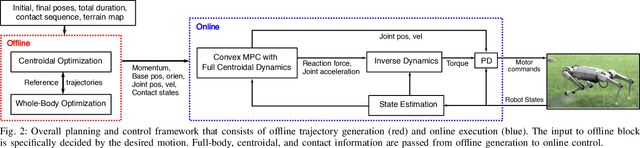
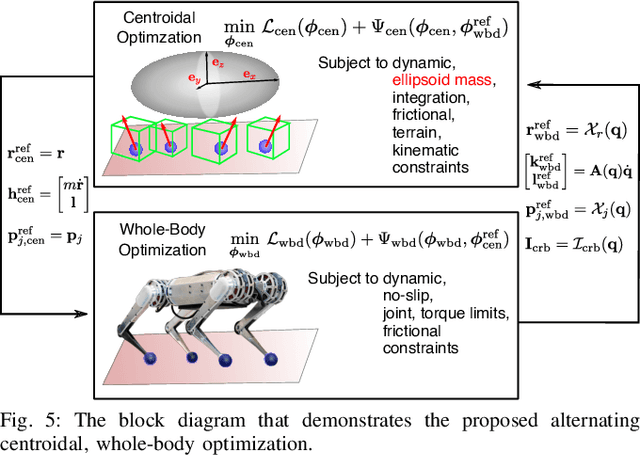
In this paper, we present a versatile hierarchical offline planning algorithm, along with and an online control pipeline for agile quadrupedal locomotion. Our offline planner alternates between optimizing centroidal dynamics for a reduced-order model and whole-body trajectory optimization, with the aim of achieving dynamics consensus. Our novel momentum-inertia-aware centroidal optimization, which uses an equimomental ellipsoid parameterization, is able to generate highly acrobatic motions via "inertia shaping". Our whole-body optimization approach significantly improves upon the quality of standard DDP-based approaches by iteratively exploiting feedback from the centroidal level. For online control, we have developed a novel linearization of the full centroidal dynamics, and incorporated these into a convex model predictive control scheme. Our controller can efficiently optimize for both contact forces and joint accelerations in single optimization, enabling more straightforward tracking for momentum-rich motions compared to existing quadrupedal MPC controllers. We demonstrate the capability and generality of our trajectory planner on four different dynamic maneuvers. We then present hardware experiments on the MIT Mini Cheetah platform to demonstrate performance of the entire planning and control pipeline on a twisting jump maneuver.