 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMVGGT: Multimodal Visual Geometry Grounded Transformer for Multiview 3D Referring Expression Segmentation
Jan 13, 2026Most existing 3D referring expression segmentation (3DRES) methods rely on dense, high-quality point clouds, while real-world agents such as robots and mobile phones operate with only a few sparse RGB views and strict latency constraints. We introduce Multi-view 3D Referring Expression Segmentation (MV-3DRES), where the model must recover scene structure and segment the referred object directly from sparse multi-view images. Traditional two-stage pipelines, which first reconstruct a point cloud and then perform segmentation, often yield low-quality geometry, produce coarse or degraded target regions, and run slowly. We propose the Multimodal Visual Geometry Grounded Transformer (MVGGT), an efficient end-to-end framework that integrates language information into sparse-view geometric reasoning through a dual-branch design. Training in this setting exposes a critical optimization barrier, termed Foreground Gradient Dilution (FGD), where sparse 3D signals lead to weak supervision. To resolve this, we introduce Per-view No-target Suppression Optimization (PVSO), which provides stronger and more balanced gradients across views, enabling stable and efficient learning. To support consistent evaluation, we build MVRefer, a benchmark that defines standardized settings and metrics for MV-3DRES. Experiments show that MVGGT establishes the first strong baseline and achieves both high accuracy and fast inference, outperforming existing alternatives. Code and models are publicly available at https://mvggt.github.io.
CSMCIR: CoT-Enhanced Symmetric Alignment with Memory Bank for Composed Image Retrieval
Jan 07, 2026Composed Image Retrieval (CIR) enables users to search for target images using both a reference image and manipulation text, offering substantial advantages over single-modality retrieval systems. However, existing CIR methods suffer from representation space fragmentation: queries and targets comprise heterogeneous modalities and are processed by distinct encoders, forcing models to bridge misaligned representation spaces only through post-hoc alignment, which fundamentally limits retrieval performance. This architectural asymmetry manifests as three distinct, well-separated clusters in the feature space, directly demonstrating how heterogeneous modalities create fundamentally misaligned representation spaces from initialization. In this work, we propose CSMCIR, a unified representation framework that achieves efficient query-target alignment through three synergistic components. First, we introduce a Multi-level Chain-of-Thought (MCoT) prompting strategy that guides Multimodal Large Language Models to generate discriminative, semantically compatible captions for target images, establishing modal symmetry. Building upon this, we design a symmetric dual-tower architecture where both query and target sides utilize the identical shared-parameter Q-Former for cross-modal encoding, ensuring consistent feature representations and further reducing the alignment gap. Finally, this architectural symmetry enables an entropy-based, temporally dynamic Memory Bank strategy that provides high-quality negative samples while maintaining consistency with the evolving model state. Extensive experiments on four benchmark datasets demonstrate that our CSMCIR achieves state-of-the-art performance with superior training efficiency. Comprehensive ablation studies further validate the effectiveness of each proposed component.
Evolving, Not Training: Zero-Shot Reasoning Segmentation via Evolutionary Prompting
Dec 31, 2025Reasoning Segmentation requires models to interpret complex, context-dependent linguistic queries to achieve pixel-level localization. Current dominant approaches rely heavily on Supervised Fine-Tuning (SFT) or Reinforcement Learning (RL). However, SFT suffers from catastrophic forgetting and domain dependency, while RL is often hindered by training instability and rigid reliance on predefined reward functions. Although recent training-free methods circumvent these training burdens, they are fundamentally limited by a static inference paradigm. These methods typically rely on a single-pass "generate-then-segment" chain, which suffers from insufficient reasoning depth and lacks the capability to self-correct linguistic hallucinations or spatial misinterpretations. In this paper, we challenge these limitations and propose EVOL-SAM3, a novel zero-shot framework that reformulates reasoning segmentation as an inference-time evolutionary search process. Instead of relying on a fixed prompt, EVOL-SAM3 maintains a population of prompt hypotheses and iteratively refines them through a "Generate-Evaluate-Evolve" loop. We introduce a Visual Arena to assess prompt fitness via reference-free pairwise tournaments, and a Semantic Mutation operator to inject diversity and correct semantic errors. Furthermore, a Heterogeneous Arena module integrates geometric priors with semantic reasoning to ensure robust final selection. Extensive experiments demonstrate that EVOL-SAM3 not only substantially outperforms static baselines but also significantly surpasses fully supervised state-of-the-art methods on the challenging ReasonSeg benchmark in a zero-shot setting. The code is available at https://github.com/AHideoKuzeA/Evol-SAM3.
JavisGPT: A Unified Multi-modal LLM for Sounding-Video Comprehension and Generation
Dec 28, 2025This paper presents JavisGPT, the first unified multimodal large language model (MLLM) for Joint Audio-Video (JAV) comprehension and generation. JavisGPT adopts a concise encoder-LLM-decoder architecture, featuring a SyncFusion module for spatio-temporal audio-video fusion and synchrony-aware learnable queries to bridge a pretrained JAV-DiT generator. This design enables temporally coherent video-audio understanding and generation from multimodal instructions. We design an effective three-stage training pipeline consisting of multimodal pretraining, audio-video fine-tuning, and large-scale instruction-tuning, to progressively build multimodal comprehension and generation from existing vision-language models. To support this, we further construct JavisInst-Omni, a high-quality instruction dataset with over 200K GPT-4o-curated audio-video-text dialogues that span diverse and multi-level comprehension and generation scenarios. Extensive experiments on JAV comprehension and generation benchmarks show that JavisGPT outperforms existing MLLMs, particularly in complex and temporally synchronized settings.
Understanding What Is Not Said:Referring Remote Sensing Image Segmentation with Scarce Expressions
Oct 26, 2025Referring Remote Sensing Image Segmentation (RRSIS) aims to segment instances in remote sensing images according to referring expressions. Unlike Referring Image Segmentation on general images, acquiring high-quality referring expressions in the remote sensing domain is particularly challenging due to the prevalence of small, densely distributed objects and complex backgrounds. This paper introduces a new learning paradigm, Weakly Referring Expression Learning (WREL) for RRSIS, which leverages abundant class names as weakly referring expressions together with a small set of accurate ones to enable efficient training under limited annotation conditions. Furthermore, we provide a theoretical analysis showing that mixed-referring training yields a provable upper bound on the performance gap relative to training with fully annotated referring expressions, thereby establishing the validity of this new setting. We also propose LRB-WREL, which integrates a Learnable Reference Bank (LRB) to refine weakly referring expressions through sample-specific prompt embeddings that enrich coarse class-name inputs. Combined with a teacher-student optimization framework using dynamically scheduled EMA updates, LRB-WREL stabilizes training and enhances cross-modal generalization under noisy weakly referring supervision. Extensive experiments on our newly constructed benchmark with varying weakly referring data ratios validate both the theoretical insights and the practical effectiveness of WREL and LRB-WREL, demonstrating that they can approach or even surpass models trained with fully annotated referring expressions.
CIR-CoT: Towards Interpretable Composed Image Retrieval via End-to-End Chain-of-Thought Reasoning
Oct 09, 2025



Composed Image Retrieval (CIR), which aims to find a target image from a reference image and a modification text, presents the core challenge of performing unified reasoning across visual and semantic modalities. While current approaches based on Vision-Language Models (VLMs, e.g., CLIP) and more recent Multimodal Large Language Models (MLLMs, e.g., Qwen-VL) have shown progress, they predominantly function as ``black boxes." This inherent opacity not only prevents users from understanding the retrieval rationale but also restricts the models' ability to follow complex, fine-grained instructions. To overcome these limitations, we introduce CIR-CoT, the first end-to-end retrieval-oriented MLLM designed to integrate explicit Chain-of-Thought (CoT) reasoning. By compelling the model to first generate an interpretable reasoning chain, CIR-CoT enhances its ability to capture crucial cross-modal interactions, leading to more accurate retrieval while making its decision process transparent. Since existing datasets like FashionIQ and CIRR lack the necessary reasoning data, a key contribution of our work is the creation of structured CoT annotations using a three-stage process involving a caption, reasoning, and conclusion. Our model is then fine-tuned to produce this structured output before encoding its final retrieval intent into a dedicated embedding. Comprehensive experiments show that CIR-CoT achieves highly competitive performance on in-domain datasets (FashionIQ, CIRR) and demonstrates remarkable generalization on the out-of-domain CIRCO dataset, establishing a new path toward more effective and trustworthy retrieval systems.
MIHBench: Benchmarking and Mitigating Multi-Image Hallucinations in Multimodal Large Language Models
Aug 01, 2025Despite growing interest in hallucination in Multimodal Large Language Models, existing studies primarily focus on single-image settings, leaving hallucination in multi-image scenarios largely unexplored. To address this gap, we conduct the first systematic study of hallucinations in multi-image MLLMs and propose MIHBench, a benchmark specifically tailored for evaluating object-related hallucinations across multiple images. MIHBench comprises three core tasks: Multi-Image Object Existence Hallucination, Multi-Image Object Count Hallucination, and Object Identity Consistency Hallucination, targeting semantic understanding across object existence, quantity reasoning, and cross-view identity consistency. Through extensive evaluation, we identify key factors associated with the occurrence of multi-image hallucinations, including: a progressive relationship between the number of image inputs and the likelihood of hallucination occurrences; a strong correlation between single-image hallucination tendencies and those observed in multi-image contexts; and the influence of same-object image ratios and the positional placement of negative samples within image sequences on the occurrence of object identity consistency hallucination. To address these challenges, we propose a Dynamic Attention Balancing mechanism that adjusts inter-image attention distributions while preserving the overall visual attention proportion. Experiments across multiple state-of-the-art MLLMs demonstrate that our method effectively reduces hallucination occurrences and enhances semantic integration and reasoning stability in multi-image scenarios.
AIGI-Holmes: Towards Explainable and Generalizable AI-Generated Image Detection via Multimodal Large Language Models
Jul 03, 2025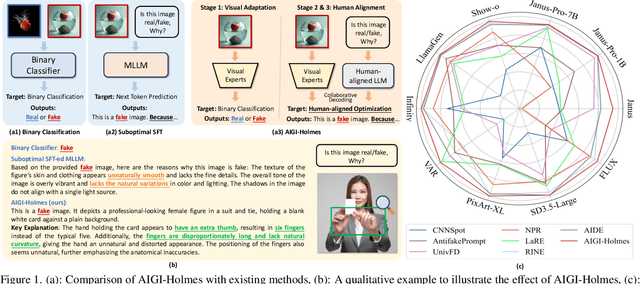
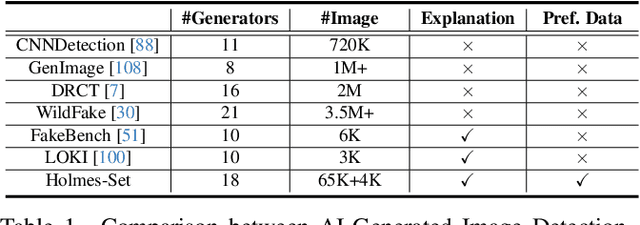
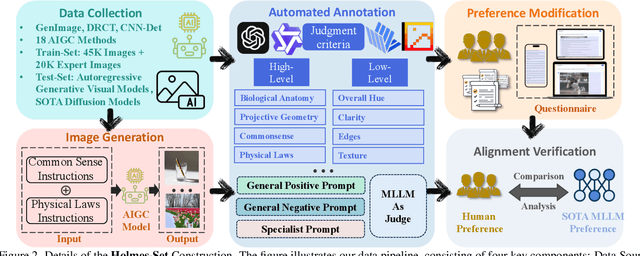
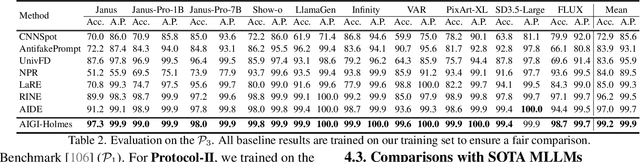
The rapid development of AI-generated content (AIGC) technology has led to the misuse of highly realistic AI-generated images (AIGI) in spreading misinformation, posing a threat to public information security. Although existing AIGI detection techniques are generally effective, they face two issues: 1) a lack of human-verifiable explanations, and 2) a lack of generalization in the latest generation technology. To address these issues, we introduce a large-scale and comprehensive dataset, Holmes-Set, which includes the Holmes-SFTSet, an instruction-tuning dataset with explanations on whether images are AI-generated, and the Holmes-DPOSet, a human-aligned preference dataset. Our work introduces an efficient data annotation method called the Multi-Expert Jury, enhancing data generation through structured MLLM explanations and quality control via cross-model evaluation, expert defect filtering, and human preference modification. In addition, we propose Holmes Pipeline, a meticulously designed three-stage training framework comprising visual expert pre-training, supervised fine-tuning, and direct preference optimization. Holmes Pipeline adapts multimodal large language models (MLLMs) for AIGI detection while generating human-verifiable and human-aligned explanations, ultimately yielding our model AIGI-Holmes. During the inference stage, we introduce a collaborative decoding strategy that integrates the model perception of the visual expert with the semantic reasoning of MLLMs, further enhancing the generalization capabilities. Extensive experiments on three benchmarks validate the effectiveness of our AIGI-Holmes.
SpaCE-10: A Comprehensive Benchmark for Multimodal Large Language Models in Compositional Spatial Intelligence
Jun 09, 2025Multimodal Large Language Models (MLLMs) have achieved remarkable progress in various multimodal tasks. To pursue higher intelligence in space, MLLMs require integrating multiple atomic spatial capabilities to handle complex and dynamic tasks. However, existing benchmarks struggle to comprehensively evaluate the spatial intelligence of common MLLMs from the atomic level to the compositional level. To fill this gap, we present SpaCE-10, a comprehensive benchmark for compositional spatial evaluations. In SpaCE-10, we define 10 atomic spatial capabilities, which are combined to form 8 compositional capabilities. Based on these definitions, we propose a novel hierarchical annotation pipeline to generate high-quality and diverse question-answer (QA) pairs. With over 150+ hours of human expert effort, we obtain over 5k QA pairs for 811 real indoor scenes in SpaCE-10, which covers various evaluation settings like point cloud input and multi-choice QA. We conduct an extensive evaluation of common MLLMs on SpaCE-10 and find that even the most advanced MLLM still lags behind humans by large margins. Through our careful study, we also draw several significant findings that benefit the MLLM community. For example, we reveal that the shortcoming of counting capability greatly limits the compositional spatial capabilities of existing MLLMs. The evaluation code and benchmark datasets are available at https://github.com/Cuzyoung/SpaCE-10.
RePrompt: Reasoning-Augmented Reprompting for Text-to-Image Generation via Reinforcement Learning
May 23, 2025Despite recent progress in text-to-image (T2I) generation, existing models often struggle to faithfully capture user intentions from short and under-specified prompts. While prior work has attempted to enhance prompts using large language models (LLMs), these methods frequently generate stylistic or unrealistic content due to insufficient grounding in visual semantics and real-world composition. Inspired by recent advances in reasoning for language model, we propose RePrompt, a novel reprompting framework that introduces explicit reasoning into the prompt enhancement process via reinforcement learning. Instead of relying on handcrafted rules or stylistic rewrites, our method trains a language model to generate structured, self-reflective prompts by optimizing for image-level outcomes. The tailored reward models assesse the generated images in terms of human preference, semantic alignment, and visual composition, providing indirect supervision to refine prompt generation. Our approach enables end-to-end training without human-annotated data. Experiments on GenEval and T2I-Compbench show that RePrompt significantly boosts spatial layout fidelity and compositional generalization across diverse T2I backbones, establishing new state-of-the-art results.