 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Out-of-distribution (OOD) Detection: Masked Image Modeling is All You Need
Feb 06, 2023



The core of out-of-distribution (OOD) detection is to learn the in-distribution (ID) representation, which is distinguishable from OOD samples. Previous work applied recognition-based methods to learn the ID features, which tend to learn shortcuts instead of comprehensive representations. In this work, we find surprisingly that simply using reconstruction-based methods could boost the performance of OOD detection significantly. We deeply explore the main contributors of OOD detection and find that reconstruction-based pretext tasks have the potential to provide a generally applicable and efficacious prior, which benefits the model in learning intrinsic data distributions of the ID dataset. Specifically, we take Masked Image Modeling as a pretext task for our OOD detection framework (MOOD). Without bells and whistles, MOOD outperforms previous SOTA of one-class OOD detection by 5.7%, multi-class OOD detection by 3.0%, and near-distribution OOD detection by 2.1%. It even defeats the 10-shot-per-class outlier exposure OOD detection, although we do not include any OOD samples for our detection
Understanding Imbalanced Semantic Segmentation Through Neural Collapse
Jan 03, 2023



A recent study has shown a phenomenon called neural collapse in that the within-class means of features and the classifier weight vectors converge to the vertices of a simplex equiangular tight frame at the terminal phase of training for classification. In this paper, we explore the corresponding structures of the last-layer feature centers and classifiers in semantic segmentation. Based on our empirical and theoretical analysis, we point out that semantic segmentation naturally brings contextual correlation and imbalanced distribution among classes, which breaks the equiangular and maximally separated structure of neural collapse for both feature centers and classifiers. However, such a symmetric structure is beneficial to discrimination for the minor classes. To preserve these advantages, we introduce a regularizer on feature centers to encourage the network to learn features closer to the appealing structure in imbalanced semantic segmentation. Experimental results show that our method can bring significant improvements on both 2D and 3D semantic segmentation benchmarks. Moreover, our method ranks 1st and sets a new record (+6.8% mIoU) on the ScanNet200 test leaderboard. Code will be available at https://github.com/dvlab-research/Imbalanced-Learning.
What Makes for Good Tokenizers in Vision Transformer?
Dec 21, 2022



The architecture of transformers, which recently witness booming applications in vision tasks, has pivoted against the widespread convolutional paradigm. Relying on the tokenization process that splits inputs into multiple tokens, transformers are capable of extracting their pairwise relationships using self-attention. While being the stemming building block of transformers, what makes for a good tokenizer has not been well understood in computer vision. In this work, we investigate this uncharted problem from an information trade-off perspective. In addition to unifying and understanding existing structural modifications, our derivation leads to better design strategies for vision tokenizers. The proposed Modulation across Tokens (MoTo) incorporates inter-token modeling capability through normalization. Furthermore, a regularization objective TokenProp is embraced in the standard training regime. Through extensive experiments on various transformer architectures, we observe both improved performance and intriguing properties of these two plug-and-play designs with negligible computational overhead. These observations further indicate the importance of the commonly-omitted designs of tokenizers in vision transformer.
General Adversarial Defense Against Black-box Attacks via Pixel Level and Feature Level Distribution Alignments
Dec 11, 2022Deep Neural Networks (DNNs) are vulnerable to the black-box adversarial attack that is highly transferable. This threat comes from the distribution gap between adversarial and clean samples in feature space of the target DNNs. In this paper, we use Deep Generative Networks (DGNs) with a novel training mechanism to eliminate the distribution gap. The trained DGNs align the distribution of adversarial samples with clean ones for the target DNNs by translating pixel values. Different from previous work, we propose a more effective pixel level training constraint to make this achievable, thus enhancing robustness on adversarial samples. Further, a class-aware feature-level constraint is formulated for integrated distribution alignment. Our approach is general and applicable to multiple tasks, including image classification, semantic segmentation, and object detection. We conduct extensive experiments on different datasets. Our strategy demonstrates its unique effectiveness and generality against black-box attacks.
SDM: Spatial Diffusion Model for Large Hole Image Inpainting
Dec 06, 2022



Generative adversarial networks (GANs) have made great success in image inpainting yet still have difficulties tackling large missing regions. In contrast, iterative algorithms, such as autoregressive and denoising diffusion models, have to be deployed with massive computing resources for decent effect. To overcome the respective limitations, we present a novel spatial diffusion model (SDM) that uses a few iterations to gradually deliver informative pixels to the entire image, largely enhancing the inference efficiency. Also, thanks to the proposed decoupled probabilistic modeling and spatial diffusion scheme, our method achieves high-quality large-hole completion. On multiple benchmarks, we achieve new state-of-the-art performance. Code is released at https://github.com/fenglinglwb/SDM.
Ref-NPR: Reference-Based Non-Photorealistic Radiance Fields
Dec 06, 2022



Existing 3D scene stylization methods employ an arbitrary style reference to transfer textures and colors as styles without establishing meaningful semantic correspondences. We present Reference-Based Non-Photorealistic Radiance Fields, i.e., Ref-NPR. It is a controllable scene stylization method utilizing radiance fields to stylize a 3D scene, with a single stylized 2D view taken as reference. To achieve decent results, we propose a ray registration process based on the stylized reference view to obtain pseudo-ray supervision in novel views, and exploit the semantic correspondence in content images to fill occluded regions with perceptually similar styles. Combining these operations, Ref-NPR generates non-photorealistic and continuous novel view sequences with a single reference while obtaining reasonable stylization in occluded regions. Experiments show that Ref-NPR significantly outperforms other scene and video stylization methods in terms of both visual quality and semantic correspondence. Code and data will be made publicly available.
Fine-Grained Entity Segmentation
Nov 12, 2022



In dense image segmentation tasks (e.g., semantic, panoptic), existing methods can hardly generalize well to unseen image domains, predefined classes, and image resolution & quality variations. Motivated by these observations, we construct a large-scale entity segmentation dataset to explore fine-grained entity segmentation, with a strong focus on open-world and high-quality dense segmentation. The dataset contains images spanning diverse image domains and resolutions, along with high-quality mask annotations for training and testing. Given the high-quality and -resolution nature of the dataset, we propose CropFormer for high-quality segmentation, which can improve mask prediction using high-res image crops that provide more fine-grained image details than the full image. CropFormer is the first query-based Transformer architecture that can effectively ensemble mask predictions from multiple image crops, by learning queries that can associate the same entities across the full image and its crop. With CropFormer, we achieve a significant AP gain of $1.9$ on the challenging fine-grained entity segmentation task. The dataset and code will be released at http://luqi.info/entityv2.github.io/.
Generalized Parametric Contrastive Learning
Sep 26, 2022
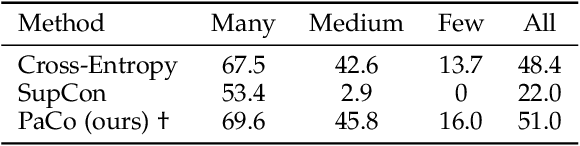
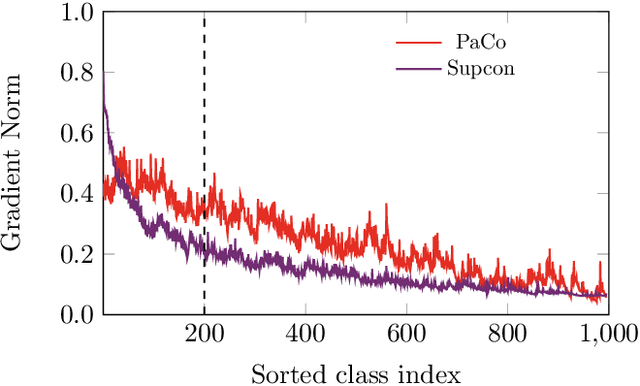
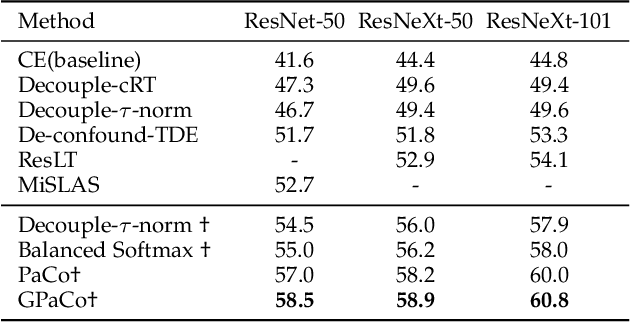
In this paper, we propose the Generalized Parametric Contrastive Learning (GPaCo/PaCo) which works well on both imbalanced and balanced data. Based on theoretical analysis, we observe that supervised contrastive loss tends to bias high-frequency classes and thus increases the difficulty of imbalanced learning. We introduce a set of parametric class-wise learnable centers to rebalance from an optimization perspective. Further, we analyze our GPaCo/PaCo loss under a balanced setting. Our analysis demonstrates that GPaCo/PaCo can adaptively enhance the intensity of pushing samples of the same class close as more samples are pulled together with their corresponding centers and benefit hard example learning. Experiments on long-tailed benchmarks manifest the new state-of-the-art for long-tailed recognition. On full ImageNet, models from CNNs to vision transformers trained with GPaCo loss show better generalization performance and stronger robustness compared with MAE models. Moreover, GPaCo can be applied to the semantic segmentation task and obvious improvements are observed on the 4 most popular benchmarks. Our code is available at https://github.com/dvlab-research/Parametric-Contrastive-Learning.
End-to-end View Synthesis via NeRF Attention
Aug 01, 2022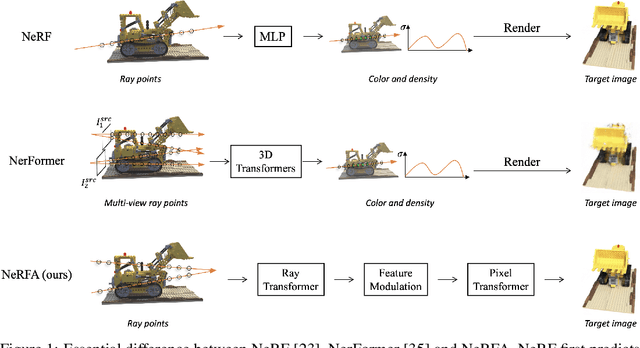
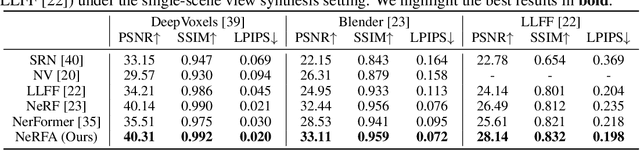
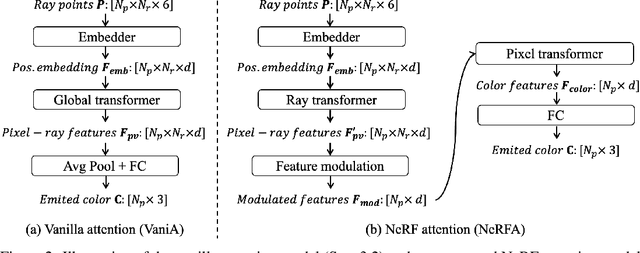
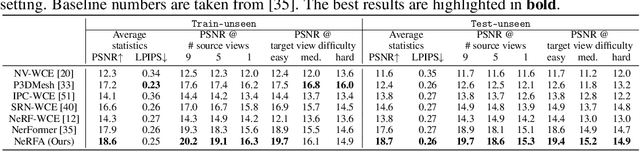
In this paper, we present a simple seq2seq formulation for view synthesis where we take a set of ray points as input and output colors corresponding to the rays. Directly applying a standard transformer on this seq2seq formulation has two limitations. First, the standard attention cannot successfully fit the volumetric rendering procedure, and therefore high-frequency components are missing in the synthesized views. Second, applying global attention to all rays and pixels is extremely inefficient. Inspired by the neural radiance field (NeRF), we propose the NeRF attention (NeRFA) to address the above problems. On the one hand, NeRFA considers the volumetric rendering equation as a soft feature modulation procedure. In this way, the feature modulation enhances the transformers with the NeRF-like inductive bias. On the other hand, NeRFA performs multi-stage attention to reduce the computational overhead. Furthermore, the NeRFA model adopts the ray and pixel transformers to learn the interactions between rays and pixels. NeRFA demonstrates superior performance over NeRF and NerFormer on four datasets: DeepVoxels, Blender, LLFF, and CO3D. Besides, NeRFA establishes a new state-of-the-art under two settings: the single-scene view synthesis and the category-centric novel view synthesis. The code will be made publicly available.
DecoupleNet: Decoupled Network for Domain Adaptive Semantic Segmentation
Jul 20, 2022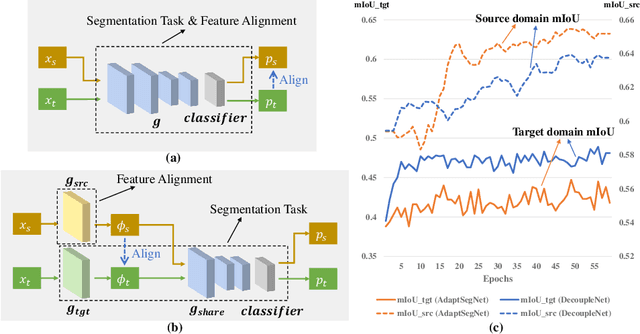
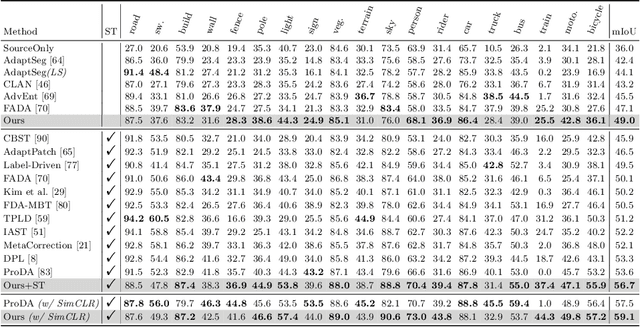
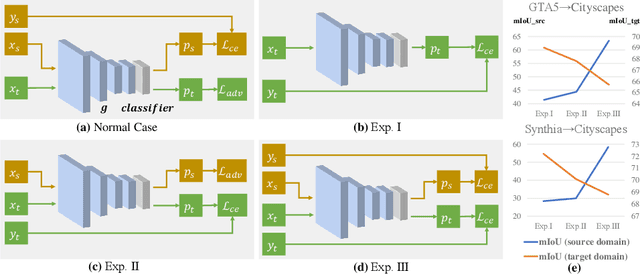
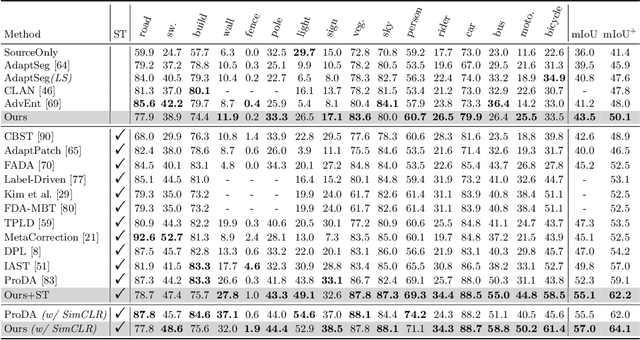
Unsupervised domain adaptation in semantic segmentation has been raised to alleviate the reliance on expensive pixel-wise annotations. It leverages a labeled source domain dataset as well as unlabeled target domain images to learn a segmentation network. In this paper, we observe two main issues of the existing domain-invariant learning framework. (1) Being distracted by the feature distribution alignment, the network cannot focus on the segmentation task. (2) Fitting source domain data well would compromise the target domain performance. To address these issues, we propose DecoupleNet that alleviates source domain overfitting and enables the final model to focus more on the segmentation task. Furthermore, we put forward Self-Discrimination (SD) and introduce an auxiliary classifier to learn more discriminative target domain features with pseudo labels. Finally, we propose Online Enhanced Self-Training (OEST) to contextually enhance the quality of pseudo labels in an online manner. Experiments show our method outperforms existing state-of-the-art methods, and extensive ablation studies verify the effectiveness of each component. Code is available at https://github.com/dvlab-research/DecoupleNet.