 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeR1-Compress: Long Chain-of-Thought Compression via Chunk Compression and Search
May 22, 2025Chain-of-Thought (CoT) reasoning enhances large language models (LLMs) by enabling step-by-step problem-solving, yet its extension to Long-CoT introduces substantial computational overhead due to increased token length. Existing compression approaches -- instance-level and token-level -- either sacrifice essential local reasoning signals like reflection or yield incoherent outputs. To address these limitations, we propose R1-Compress, a two-stage chunk-level compression framework that preserves both local information and coherence. Our method segments Long-CoT into manageable chunks, applies LLM-driven inner-chunk compression, and employs an inter-chunk search mechanism to select the short and coherent sequence. Experiments on Qwen2.5-Instruct models across MATH500, AIME24, and GPQA-Diamond demonstrate that R1-Compress significantly reduces token usage while maintaining comparable reasoning accuracy. On MATH500, R1-Compress achieves an accuracy of 92.4%, with only a 0.6% drop compared to the Long-CoT baseline, while reducing token usage by about 20%. Source code will be available at https://github.com/w-yibo/R1-Compress
Training-Free Text-Guided Image Editing with Visual Autoregressive Model
Mar 31, 2025Text-guided image editing is an essential task that enables users to modify images through natural language descriptions. Recent advances in diffusion models and rectified flows have significantly improved editing quality, primarily relying on inversion techniques to extract structured noise from input images. However, inaccuracies in inversion can propagate errors, leading to unintended modifications and compromising fidelity. Moreover, even with perfect inversion, the entanglement between textual prompts and image features often results in global changes when only local edits are intended. To address these challenges, we propose a novel text-guided image editing framework based on VAR (Visual AutoRegressive modeling), which eliminates the need for explicit inversion while ensuring precise and controlled modifications. Our method introduces a caching mechanism that stores token indices and probability distributions from the original image, capturing the relationship between the source prompt and the image. Using this cache, we design an adaptive fine-grained masking strategy that dynamically identifies and constrains modifications to relevant regions, preventing unintended changes. A token reassembling approach further refines the editing process, enhancing diversity, fidelity, and control. Our framework operates in a training-free manner and achieves high-fidelity editing with faster inference speeds, processing a 1K resolution image in as fast as 1.2 seconds. Extensive experiments demonstrate that our method achieves performance comparable to, or even surpassing, existing diffusion- and rectified flow-based approaches in both quantitative metrics and visual quality. The code will be released.
R1-VL: Learning to Reason with Multimodal Large Language Models via Step-wise Group Relative Policy Optimization
Mar 17, 2025Recent studies generally enhance MLLMs' reasoning capabilities via supervised fine-tuning on high-quality chain-of-thought reasoning data, which often leads models to merely imitate successful reasoning paths without understanding what the wrong reasoning paths are. In this work, we aim to enhance the MLLMs' reasoning ability beyond passively imitating positive reasoning paths. To this end, we design Step-wise Group Relative Policy Optimization (StepGRPO), a new online reinforcement learning framework that enables MLLMs to self-improve reasoning ability via simple, effective and dense step-wise rewarding. Specifically, StepGRPO introduces two novel rule-based reasoning rewards: Step-wise Reasoning Accuracy Reward (StepRAR) and Step-wise Reasoning Validity Reward (StepRVR). StepRAR rewards the reasoning paths that contain necessary intermediate reasoning steps via a soft key-step matching technique, while StepRAR rewards reasoning paths that follow a well-structured and logically consistent reasoning process through a reasoning completeness and logic evaluation strategy. With the proposed StepGRPO, we introduce R1-VL, a series of MLLMs with outstanding capabilities in step-by-step reasoning. Extensive experiments over 8 benchmarks demonstrate the superiority of our methods.
Strategic priorities for transformative progress in advancing biology with proteomics and artificial intelligence
Feb 21, 2025

Artificial intelligence (AI) is transforming scientific research, including proteomics. Advances in mass spectrometry (MS)-based proteomics data quality, diversity, and scale, combined with groundbreaking AI techniques, are unlocking new challenges and opportunities in biological discovery. Here, we highlight key areas where AI is driving innovation, from data analysis to new biological insights. These include developing an AI-friendly ecosystem for proteomics data generation, sharing, and analysis; improving peptide and protein identification and quantification; characterizing protein-protein interactions and protein complexes; advancing spatial and perturbation proteomics; integrating multi-omics data; and ultimately enabling AI-empowered virtual cells.
Reasoning with Reinforced Functional Token Tuning
Feb 19, 2025



In this work, we propose Reinforced Functional Token Tuning (RFTT), a novel reinforced fine-tuning framework that empowers Large Language Models (LLMs) with self-play learn-to-reason capabilities. Unlike prior prompt-driven reasoning efforts, RFTT embeds a rich set of learnable functional tokens (e.g., <analyze>, <verify>, <refine>) directly into the model vocabulary, enabling chain-of-thought construction with diverse human-like reasoning behaviors. Specifically, RFTT comprises two phases: (1) supervised fine-tuning performs prompt-driven tree search to obtain self-generated training data annotated with functional tokens, which warms up the model to learn these tokens for reasoning; and (2) online reinforcement learning further allows the model to explore different reasoning pathways through functional token sampling without relying on prompts, thereby facilitating effective self-improvement for functional reasoning. Extensive experiments demonstrate the superiority of the proposed RFTT on mathematical benchmarks, significantly boosting Qwen-2.5-7B-Instruct (70.6% to 79.8%) and LLaMA-3.1-8B-Instruct (32.2% to 60.2%) on the MATH dataset. Moreover, the performance of RFTT consistently improves with more search rollouts at inference time. Our code is available at https://github.com/sastpg/RFTT.
PhysReason: A Comprehensive Benchmark towards Physics-Based Reasoning
Feb 17, 2025



Large language models demonstrate remarkable capabilities across various domains, especially mathematics and logic reasoning. However, current evaluations overlook physics-based reasoning - a complex task requiring physics theorems and constraints. We present PhysReason, a 1,200-problem benchmark comprising knowledge-based (25%) and reasoning-based (75%) problems, where the latter are divided into three difficulty levels (easy, medium, hard). Notably, problems require an average of 8.1 solution steps, with hard requiring 15.6, reflecting the complexity of physics-based reasoning. We propose the Physics Solution Auto Scoring Framework, incorporating efficient answer-level and comprehensive step-level evaluations. Top-performing models like Deepseek-R1, Gemini-2.0-Flash-Thinking, and o3-mini-high achieve less than 60% on answer-level evaluation, with performance dropping from knowledge questions (75.11%) to hard problems (31.95%). Through step-level evaluation, we identified four key bottlenecks: Physics Theorem Application, Physics Process Understanding, Calculation, and Physics Condition Analysis. These findings position PhysReason as a novel and comprehensive benchmark for evaluating physics-based reasoning capabilities in large language models. Our code and data will be published at https:/dxzxy12138.github.io/PhysReason.
Panacea: Mitigating Harmful Fine-tuning for Large Language Models via Post-fine-tuning Perturbation
Jan 30, 2025



Harmful fine-tuning attack introduces significant security risks to the fine-tuning services. Mainstream defenses aim to vaccinate the model such that the later harmful fine-tuning attack is less effective. However, our evaluation results show that such defenses are fragile -- with a few fine-tuning steps, the model still can learn the harmful knowledge. To this end, we do further experiment and find that an embarrassingly simple solution -- adding purely random perturbations to the fine-tuned model, can recover the model from harmful behavior, though it leads to a degradation in the model's fine-tuning performance. To address the degradation of fine-tuning performance, we further propose Panacea, which optimizes an adaptive perturbation that will be applied to the model after fine-tuning. Panacea maintains model's safety alignment performance without compromising downstream fine-tuning performance. Comprehensive experiments are conducted on different harmful ratios, fine-tuning tasks and mainstream LLMs, where the average harmful scores are reduced by up-to 21.5%, while maintaining fine-tuning performance. As a by-product, we analyze the optimized perturbation and show that different layers in various LLMs have distinct safety coefficients. Source code available at https://github.com/w-yibo/Panacea
Mulberry: Empowering MLLM with o1-like Reasoning and Reflection via Collective Monte Carlo Tree Search
Dec 24, 2024



In this work, we aim to develop an MLLM that understands and solves questions by learning to create each intermediate step of the reasoning involved till the final answer. To this end, we propose Collective Monte Carlo Tree Search (CoMCTS), a new learning-to-reason method for MLLMs, which introduces the concept of collective learning into ``tree search'' for effective and efficient reasoning-path searching and learning. The core idea of CoMCTS is to leverage collective knowledge from multiple models to collaboratively conjecture, search and identify effective reasoning paths toward correct answers via four iterative operations including Expansion, Simulation and Error Positioning, Backpropagation, and Selection. Using CoMCTS, we construct Mulberry-260k, a multimodal dataset with a tree of rich, explicit and well-defined reasoning nodes for each question. With Mulberry-260k, we perform collective SFT to train our model, Mulberry, a series of MLLMs with o1-like step-by-step Reasoning and Reflection capabilities. Extensive experiments demonstrate the superiority of our proposed methods on various benchmarks. Code will be available at https://github.com/HJYao00/Mulberry
SPAgent: Adaptive Task Decomposition and Model Selection for General Video Generation and Editing
Nov 28, 2024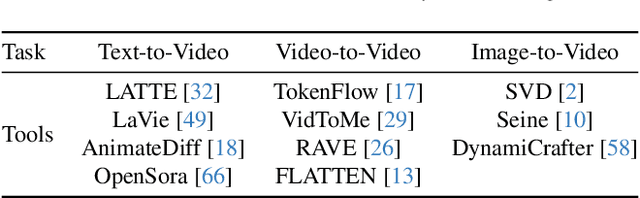
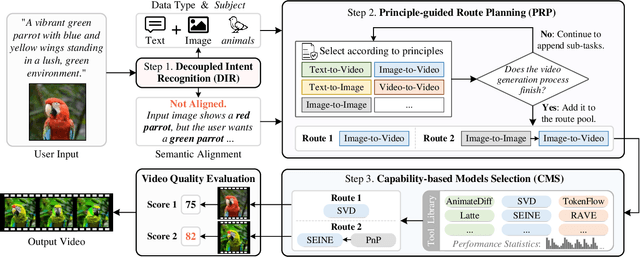

While open-source video generation and editing models have made significant progress, individual models are typically limited to specific tasks, failing to meet the diverse needs of users. Effectively coordinating these models can unlock a wide range of video generation and editing capabilities. However, manual coordination is complex and time-consuming, requiring users to deeply understand task requirements and possess comprehensive knowledge of each model's performance, applicability, and limitations, thereby increasing the barrier to entry. To address these challenges, we propose a novel video generation and editing system powered by our Semantic Planning Agent (SPAgent). SPAgent bridges the gap between diverse user intents and the effective utilization of existing generative models, enhancing the adaptability, efficiency, and overall quality of video generation and editing. Specifically, the SPAgent assembles a tool library integrating state-of-the-art open-source image and video generation and editing models as tools. After fine-tuning on our manually annotated dataset, SPAgent can automatically coordinate the tools for video generation and editing, through our novelly designed three-step framework: (1) decoupled intent recognition, (2) principle-guided route planning, and (3) capability-based execution model selection. Additionally, we enhance the SPAgent's video quality evaluation capability, enabling it to autonomously assess and incorporate new video generation and editing models into its tool library without human intervention. Experimental results demonstrate that the SPAgent effectively coordinates models to generate or edit videos, highlighting its versatility and adaptability across various video tasks.
A Survey on Vision Autoregressive Model
Nov 13, 2024Autoregressive models have demonstrated great performance in natural language processing (NLP) with impressive scalability, adaptability and generalizability. Inspired by their notable success in NLP field, autoregressive models have been intensively investigated recently for computer vision, which perform next-token predictions by representing visual data as visual tokens and enables autoregressive modelling for a wide range of vision tasks, ranging from visual generation and visual understanding to the very recent multimodal generation that unifies visual generation and understanding with a single autoregressive model. This paper provides a systematic review of vision autoregressive models, including the development of a taxonomy of existing methods and highlighting their major contributions, strengths, and limitations, covering various vision tasks such as image generation, video generation, image editing, motion generation, medical image analysis, 3D generation, robotic manipulation, unified multimodal generation, etc. Besides, we investigate and analyze the latest advancements in autoregressive models, including thorough benchmarking and discussion of existing methods across various evaluation datasets. Finally, we outline key challenges and promising directions for future research, offering a roadmap to guide further advancements in vision autoregressive models.