 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniRel-R1: RL-tuned LLM Reasoning for Knowledge Graph Relational Question Answering
Dec 18, 2025Knowledge Graph Question Answering (KGQA) has traditionally focused on entity-centric queries that return a single answer entity. However, real-world queries are often relational, seeking to understand how entities are associated. In this work, we introduce relation-centric KGQA, a complementary setting where the answer is a subgraph capturing the semantic connections among entities rather than an individual entity. The main challenge lies in the abundance of candidate subgraphs, where trivial or overly common connections often obscure the identification of unique and informative answers. To tackle this, we propose UniRel-R1, a unified framework that integrates subgraph selection, multi-stage graph pruning, and an LLM fine-tuned with reinforcement learning. The reward function is designed to encourage compact and specific subgraphs with more informative relations and lower-degree intermediate entities. Extensive experiments show that UniRel-R1 achieves significant gains in connectivity and reward over Vanilla baselines and generalizes effectively to unseen entities and relations.
VisPlay: Self-Evolving Vision-Language Models from Images
Nov 19, 2025Reinforcement learning (RL) provides a principled framework for improving Vision-Language Models (VLMs) on complex reasoning tasks. However, existing RL approaches often rely on human-annotated labels or task-specific heuristics to define verifiable rewards, both of which are costly and difficult to scale. We introduce VisPlay, a self-evolving RL framework that enables VLMs to autonomously improve their reasoning abilities using large amounts of unlabeled image data. Starting from a single base VLM, VisPlay assigns the model into two interacting roles: an Image-Conditioned Questioner that formulates challenging yet answerable visual questions, and a Multimodal Reasoner that generates silver responses. These roles are jointly trained with Group Relative Policy Optimization (GRPO), which incorporates diversity and difficulty rewards to balance the complexity of generated questions with the quality of the silver answers. VisPlay scales efficiently across two model families. When trained on Qwen2.5-VL and MiMo-VL, VisPlay achieves consistent improvements in visual reasoning, compositional generalization, and hallucination reduction across eight benchmarks, including MM-Vet and MMMU, demonstrating a scalable path toward self-evolving multimodal intelligence. The project page is available at https://bruno686.github.io/VisPlay/
RoboMatch: A Mobile-Manipulation Teleoperation Platform with Auto-Matching Network Architecture for Long-Horizon Manipulation
Sep 10, 2025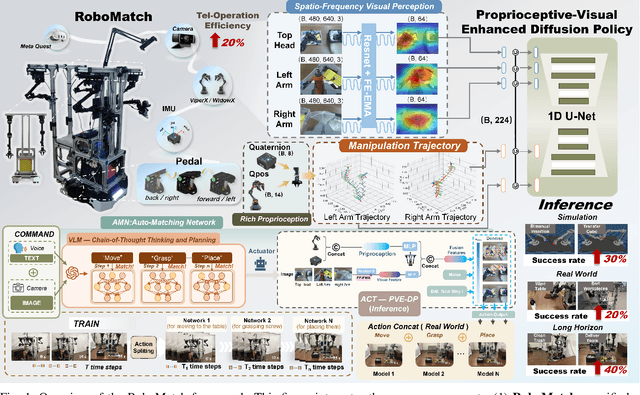

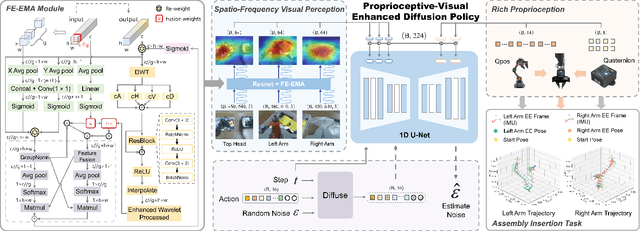
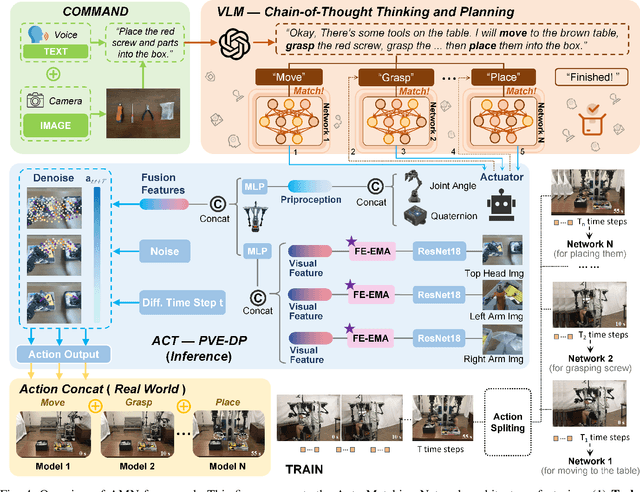
This paper presents RoboMatch, a novel unified teleoperation platform for mobile manipulation with an auto-matching network architecture, designed to tackle long-horizon tasks in dynamic environments. Our system enhances teleoperation performance, data collection efficiency, task accuracy, and operational stability. The core of RoboMatch is a cockpit-style control interface that enables synchronous operation of the mobile base and dual arms, significantly improving control precision and data collection. Moreover, we introduce the Proprioceptive-Visual Enhanced Diffusion Policy (PVE-DP), which leverages Discrete Wavelet Transform (DWT) for multi-scale visual feature extraction and integrates high-precision IMUs at the end-effector to enrich proprioceptive feedback, substantially boosting fine manipulation performance. Furthermore, we propose an Auto-Matching Network (AMN) architecture that decomposes long-horizon tasks into logical sequences and dynamically assigns lightweight pre-trained models for distributed inference. Experimental results demonstrate that our approach improves data collection efficiency by over 20%, increases task success rates by 20-30% with PVE-DP, and enhances long-horizon inference performance by approximately 40% with AMN, offering a robust solution for complex manipulation tasks.
R-Zero: Self-Evolving Reasoning LLM from Zero Data
Aug 07, 2025
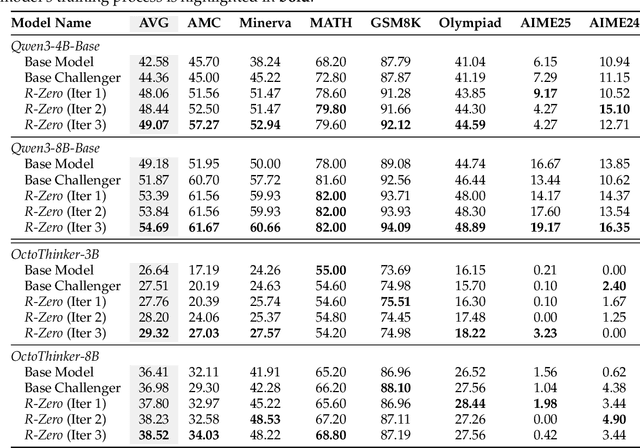

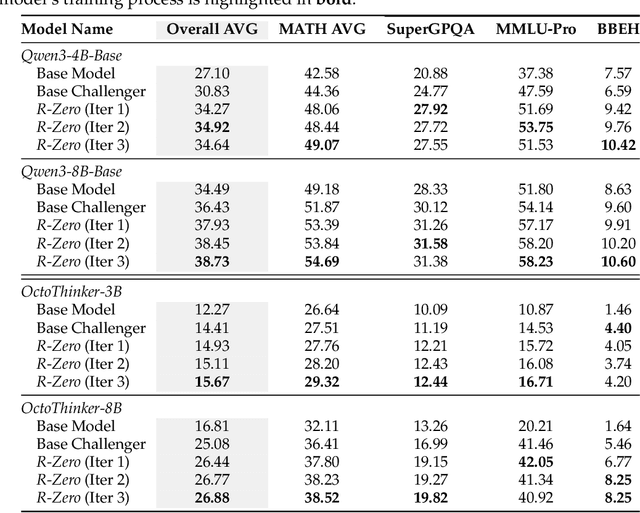
Self-evolving Large Language Models (LLMs) offer a scalable path toward super-intelligence by autonomously generating, refining, and learning from their own experiences. However, existing methods for training such models still rely heavily on vast human-curated tasks and labels, typically via fine-tuning or reinforcement learning, which poses a fundamental bottleneck to advancing AI systems toward capabilities beyond human intelligence. To overcome this limitation, we introduce R-Zero, a fully autonomous framework that generates its own training data from scratch. Starting from a single base LLM, R-Zero initializes two independent models with distinct roles, a Challenger and a Solver. These models are optimized separately and co-evolve through interaction: the Challenger is rewarded for proposing tasks near the edge of the Solver capability, and the Solver is rewarded for solving increasingly challenging tasks posed by the Challenger. This process yields a targeted, self-improving curriculum without any pre-existing tasks and labels. Empirically, R-Zero substantially improves reasoning capability across different backbone LLMs, e.g., boosting the Qwen3-4B-Base by +6.49 on math-reasoning benchmarks and +7.54 on general-domain reasoning benchmarks.
SURPRISE3D: A Dataset for Spatial Understanding and Reasoning in Complex 3D Scenes
Jul 10, 2025The integration of language and 3D perception is critical for embodied AI and robotic systems to perceive, understand, and interact with the physical world. Spatial reasoning, a key capability for understanding spatial relationships between objects, remains underexplored in current 3D vision-language research. Existing datasets often mix semantic cues (e.g., object name) with spatial context, leading models to rely on superficial shortcuts rather than genuinely interpreting spatial relationships. To address this gap, we introduce S\textsc{urprise}3D, a novel dataset designed to evaluate language-guided spatial reasoning segmentation in complex 3D scenes. S\textsc{urprise}3D consists of more than 200k vision language pairs across 900+ detailed indoor scenes from ScanNet++ v2, including more than 2.8k unique object classes. The dataset contains 89k+ human-annotated spatial queries deliberately crafted without object name, thereby mitigating shortcut biases in spatial understanding. These queries comprehensively cover various spatial reasoning skills, such as relative position, narrative perspective, parametric perspective, and absolute distance reasoning. Initial benchmarks demonstrate significant challenges for current state-of-the-art expert 3D visual grounding methods and 3D-LLMs, underscoring the necessity of our dataset and the accompanying 3D Spatial Reasoning Segmentation (3D-SRS) benchmark suite. S\textsc{urprise}3D and 3D-SRS aim to facilitate advancements in spatially aware AI, paving the way for effective embodied interaction and robotic planning. The code and datasets can be found in https://github.com/liziwennba/SUPRISE.
Efficient Medical Image Restoration via Reliability Guided Learning in Frequency Domain
Apr 15, 2025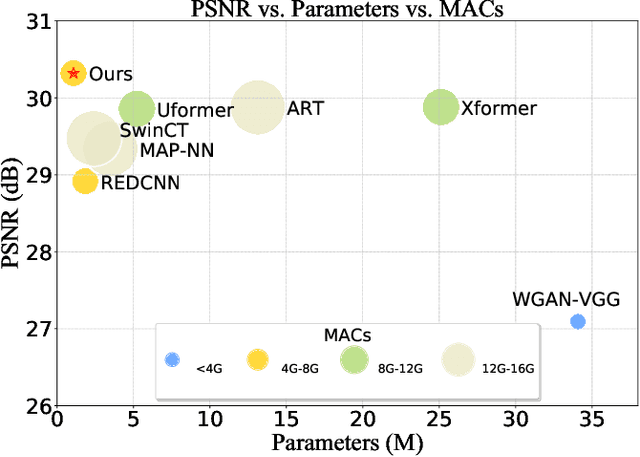
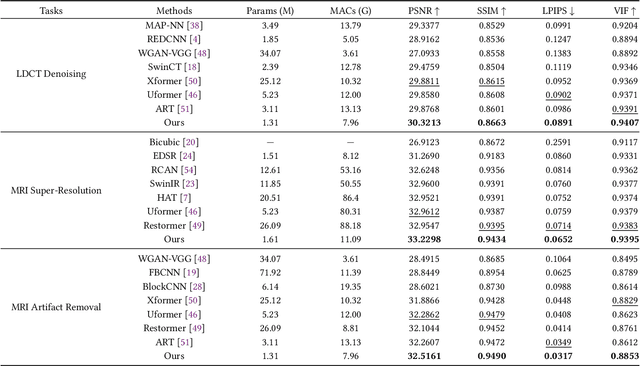
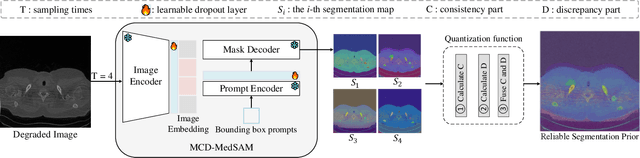
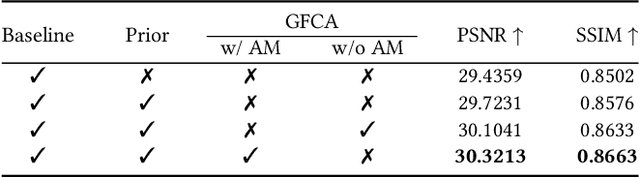
Medical image restoration tasks aim to recover high-quality images from degraded observations, exhibiting emergent desires in many clinical scenarios, such as low-dose CT image denoising, MRI super-resolution, and MRI artifact removal. Despite the success achieved by existing deep learning-based restoration methods with sophisticated modules, they struggle with rendering computationally-efficient reconstruction results. Moreover, they usually ignore the reliability of the restoration results, which is much more urgent in medical systems. To alleviate these issues, we present LRformer, a Lightweight Transformer-based method via Reliability-guided learning in the frequency domain. Specifically, inspired by the uncertainty quantification in Bayesian neural networks (BNNs), we develop a Reliable Lesion-Semantic Prior Producer (RLPP). RLPP leverages Monte Carlo (MC) estimators with stochastic sampling operations to generate sufficiently-reliable priors by performing multiple inferences on the foundational medical image segmentation model, MedSAM. Additionally, instead of directly incorporating the priors in the spatial domain, we decompose the cross-attention (CA) mechanism into real symmetric and imaginary anti-symmetric parts via fast Fourier transform (FFT), resulting in the design of the Guided Frequency Cross-Attention (GFCA) solver. By leveraging the conjugated symmetric property of FFT, GFCA reduces the computational complexity of naive CA by nearly half. Extensive experimental results in various tasks demonstrate the superiority of the proposed LRformer in both effectiveness and efficiency.
Vivid4D: Improving 4D Reconstruction from Monocular Video by Video Inpainting
Apr 15, 2025



Reconstructing 4D dynamic scenes from casually captured monocular videos is valuable but highly challenging, as each timestamp is observed from a single viewpoint. We introduce Vivid4D, a novel approach that enhances 4D monocular video synthesis by augmenting observation views - synthesizing multi-view videos from a monocular input. Unlike existing methods that either solely leverage geometric priors for supervision or use generative priors while overlooking geometry, we integrate both. This reformulates view augmentation as a video inpainting task, where observed views are warped into new viewpoints based on monocular depth priors. To achieve this, we train a video inpainting model on unposed web videos with synthetically generated masks that mimic warping occlusions, ensuring spatially and temporally consistent completion of missing regions. To further mitigate inaccuracies in monocular depth priors, we introduce an iterative view augmentation strategy and a robust reconstruction loss. Experiments demonstrate that our method effectively improves monocular 4D scene reconstruction and completion.
CrossWordBench: Evaluating the Reasoning Capabilities of LLMs and LVLMs with Controllable Puzzle Generation
Mar 30, 2025



Existing reasoning evaluation frameworks for Large Language Models (LLMs) and Large Vision-Language Models (LVLMs) predominantly either assess text-based reasoning or vision-language understanding capabilities, with limited dynamic interplay between textual and visual constraints. To address this limitation, we introduce CrossWordBench, a benchmark designed to evaluate the reasoning capabilities of both LLMs and LVLMs through the medium of crossword puzzles-a task requiring multimodal adherence to semantic constraints from text-based clues and intersectional constraints from visual grid structures. CrossWordBench leverages a controllable puzzle generation framework that produces puzzles in multiple formats (text and image) and offers different evaluation strategies ranging from direct puzzle solving to interactive modes. Our extensive evaluation of over 20 models reveals that reasoning LLMs outperform non-reasoning models substantially by effectively leveraging crossing-letter constraints. We further demonstrate that LVLMs struggle with the task, showing a strong correlation between their puzzle-solving performance and grid-parsing accuracy. Our findings offer insights into the limitations of the reasoning capabilities of current LLMs and LVLMs, and provide an effective approach for creating multimodal constrained tasks for future evaluations.
EVolSplat: Efficient Volume-based Gaussian Splatting for Urban View Synthesis
Mar 26, 2025



Novel view synthesis of urban scenes is essential for autonomous driving-related applications.Existing NeRF and 3DGS-based methods show promising results in achieving photorealistic renderings but require slow, per-scene optimization. We introduce EVolSplat, an efficient 3D Gaussian Splatting model for urban scenes that works in a feed-forward manner. Unlike existing feed-forward, pixel-aligned 3DGS methods, which often suffer from issues like multi-view inconsistencies and duplicated content, our approach predicts 3D Gaussians across multiple frames within a unified volume using a 3D convolutional network. This is achieved by initializing 3D Gaussians with noisy depth predictions, and then refining their geometric properties in 3D space and predicting color based on 2D textures. Our model also handles distant views and the sky with a flexible hemisphere background model. This enables us to perform fast, feed-forward reconstruction while achieving real-time rendering. Experimental evaluations on the KITTI-360 and Waymo datasets show that our method achieves state-of-the-art quality compared to existing feed-forward 3DGS- and NeRF-based methods.
Urban4D: Semantic-Guided 4D Gaussian Splatting for Urban Scene Reconstruction
Dec 04, 2024



Reconstructing dynamic urban scenes presents significant challenges due to their intrinsic geometric structures and spatiotemporal dynamics. Existing methods that attempt to model dynamic urban scenes without leveraging priors on potentially moving regions often produce suboptimal results. Meanwhile, approaches based on manual 3D annotations yield improved reconstruction quality but are impractical due to labor-intensive labeling. In this paper, we revisit the potential of 2D semantic maps for classifying dynamic and static Gaussians and integrating spatial and temporal dimensions for urban scene representation. We introduce Urban4D, a novel framework that employs a semantic-guided decomposition strategy inspired by advances in deep 2D semantic map generation. Our approach distinguishes potentially dynamic objects through reliable semantic Gaussians. To explicitly model dynamic objects, we propose an intuitive and effective 4D Gaussian splatting (4DGS) representation that aggregates temporal information through learnable time embeddings for each Gaussian, predicting their deformations at desired timestamps using a multilayer perceptron (MLP). For more accurate static reconstruction, we also design a k-nearest neighbor (KNN)-based consistency regularization to handle the ground surface due to its low-texture characteristic. Extensive experiments on real-world datasets demonstrate that Urban4D not only achieves comparable or better quality than previous state-of-the-art methods but also effectively captures dynamic objects while maintaining high visual fidelity for static elements.